TinyRISCV 完整指南
本文是 TinyRISCV 项目的完整文档, 共 21 个子页面,涵盖从概述到验证策略的全部内容。
项目 GitHub 地址:https://github.com/build-your-own-x-with-ai/TinyRISCV
原始文档来源:zread.ai
概述
⌘K
-
- 分享
TinyRISCV 是一个用 Verilog 编写的极简单周期 RISC-V 处理器 ,实现了 RV32I 基础整数指令集——共计 40 条指令。本项目基于第一性原理设计,旨在提供教学级别的清晰度 ,项目中的每个模块都具有单一且明确的功能,这使得它成为希望从零开始理解真实处理器工作原理的开发者的理想起点。该处理器采用哈佛架构 ,拥有独立的指令内存和数据内存,每个时钟周期执行一条指令,并在遇到
ECALL指令时干净地停机——没有流水线,没有缓存,没有微代码。你所见即所执行。 来源:README.md, docs/SUMMARY.mdTinyRISCV 的功能
从核心来看,TinyRISCV 从指令内存中取回一条 32 位指令,将其译码产生控制信号,通过 ALU 或分支单元执行操作,视需访问数据内存,并将结果写回寄存器堆——所有这些都在单个时钟周期内完成。该处理器从地址
0x00000000启动,运行从十六进制文件加载的程序,并在遇到ECALL(操作码0x1110011)时停止运行。这种清晰的执行模型意味着,你只需逐周期观察,就能追踪每条指令对寄存器和内存的影响。 来源:riscv_core.v, pc_register.v
来源:riscv_core.v, pc_register.v架构概览
下图展示了 13 个 Verilog 模块 如何连接以构成完整的单周期数据通路。数据从取指到写回自左向右流动,而控制单元向下广播信号,控制每个数据通路多路选择器和操作。
先决条件 :此图使用 Mermaid 语法。标签引用了模块名称,本指南后续页面将对每个模块进行专门文档说明。 来源:riscv_core.v
核心规格
下表总结了定义 TinyRISCV 能力与约束的核心设计参数。这些数值并非随意设定,而是反映了教学简洁性与功能完整性之间的审慎权衡。 参数| 值| 设计依据 —|—|— 架构| 单周期,哈佛架构| 每周期一条指令;独立的指令/数据通路以保持清晰 ISA| RV32I(40 条指令)| 完整的基础整数集,减去 FENCE/CSR/EBREAK 数据宽度| 32 位| 标准 RV32 寄存器数量| 32(x0 硬连线至零)| 完整的 RV32I 寄存器堆 指令内存| 4KB(1024 × 32 位字)| 在仿真开始时通过
$readmemh加载 数据内存| 4KB(4096 字节)| 字节寻址,支持字节/半字/字访问 内存访问| 小端序| RISC-V 标准 时钟| 单周期(1 条指令 = 1 个周期)| 无流水线——关键路径决定最大频率 停机机制| ECALL 指令| 当操作码 =1110011时停止 PC 递增 工具链| Icarus Verilog + RISC-V GCC| 开源、跨平台仿真 来源:README.md, imem.v, dmem.v, control.v支持的指令集
TinyRISCV 实现了 43 条标准 RV32I 指令中的 40 条。被省略的三条指令(
FENCE、FENCE.I、EBREAK)及所有 CSR 指令均为系统级操作,在教学目的的单核设计中并非必要。下表按类别对支持的指令进行了分组,并附有其功能描述。 类别| 数量| 指令| 主要负责模块 —|—|—|— 算术/逻辑(R 型)| 10| ADD, SUB, AND, OR, XOR, SLL, SRL, SRA, SLT, SLTU| ALU 立即数操作(I 型)| 9| ADDI, ANDI, ORI, XORI, SLLI, SRLI, SRAI, SLTI, SLTIU| ALU + Imm Gen 加载/存储| 8| LW, LH, LB, LHU, LBU, SW, SH, SB| Data Memory 分支| 6| BEQ, BNE, BLT, BGE, BLTU, BGEU| Branch Unit 跳转| 2| JAL, JALR| PC Adder 高位立即数| 2| LUI, AUIPC| Imm Gen + ALU 系统| 1| ECALL(停机)| PC Register 每类指令都映射到特定的硬件模块。在调试某条指令时,请从最右侧列出的模块开始检查——这是实际发生计算或决策的地方。 来源:README.md, control.v, alu.v, branch_unit.v项目结构
仓库被组织为五个顶层目录,每个目录的关注点相互分离。在深入研究任何单个模块之前,理解此布局至关重要。 Copy code TinyRISCV/ ├── rtl/ │ ├── core/ # 顶层集成与控制 │ │ ├── riscv_core.v # ◀ 顶层模块连线 │ │ ├── control.v # ◀ 40 条指令的控制信号生成器 │ │ ├── pc_register.v # ◀ 支持停机的程序计数器 │ │ └── pc_adder.v # ◀ 下一 PC 多路选择逻辑 │ ├── datapath/ # 计算与存储元素 │ │ ├── alu.v # ◀ 10 操作的算术/逻辑单元 │ │ ├── regfile.v # ◀ 32 项寄存器堆 (x0=0) │ │ ├── branch_unit.v # ◀ 6 条件分支评估器 │ │ └── imm_gen.v # ◀ 5 格式立即数符号扩展器 │ ├── decoder/ # 指令字段提取 │ │ └── decoder.v # ◀ 位切片 opcode/rd/rs1/rs2/funct3/funct7 │ └── memory/ # 指令与数据存储 │ ├── imem.v # ◀ 4KB 只读指令内存 │ └── dmem.v # ◀ 4KB 读写数据内存 ├── tb/ # 验证 │ └── riscv_core_tb.v # 集成测试台 (VCD 转储) ├── programs/ # 汇编程序与构建工具 │ ├── asm/ # 源码:hello.s, fibonacci.s, factorial.s │ ├── compile.sh # 通过 RISC-V 工具链汇编所有 .s → .hex │ └── linker.ld # 链接脚本(text 段起始于 0x00000000) ├── sim/ # 仿真产物与脚本 │ ├── Makefile # compile / simulate / wave / clean 目标 │ ├── run_sim.sh # 仿真的 Shell 包装脚本 │ ├── view_wave.sh # 查看波形的 Shell 包装脚本 │ └── wave.gtkw # GTKWave 信号组布局 ├── tools/ # Python 实用工具 │ ├── vcd_viewer.py # 解析 VCD → 人类可读的执行追踪 │ └── publish_to_wechat.py # 发布辅助工具 └── docs/ # 文档源文件 来源:README.md, docs/SUMMARY.md
单周期执行流程
单周期架构意味着每条指令恰好在一个时钟周期内遍历完整的数据通路。以下是在该周期内发生的事情,从上升沿到上升沿: 1. 取指 :PC 寄存器输出当前地址;指令内存返回该地址处的 32 位指令字。 2. 译码 :译码器提取操作码、寄存器索引和功能码;控制单元生成所有控制信号;立即数生成器产生符号扩展的立即数值;寄存器堆读取两个源操作数。 3. 执行 :ALU 计算结果(或分支单元评估条件);PC 加法器根据是否发生分支或跳转,计算下一个 PC。 4. 访存 :对于加载/存储指令,数据内存以字节/半字/字的粒度,在 ALU 计算出的地址处进行读取或写入。 5. 写回 :结果(ALU 输出、内存读取数据,或用于跳转的 PC+4)被写回目标寄存器——前提是
reg_write信号有效且rd ≠ 0。 由于每个阶段都在同一周期内执行,关键路径从取指经 ALU 计算直至数据内存访问及写回——全部为组合逻辑。这就是单周期设计的基本性能权衡:以限制了时钟频率的长关键路径为代价,换取简洁性与可调试性。 来源:riscv_core.v, pc_adder.v测试程序
包含了三个汇编程序,用于在安装设置后立即验证处理器的功能。每个程序逐步测试了更广泛的指令集: 程序| 文件| 重点| 测试的关键指令 —|—|—|— hello|
hello.s| 基础算术|LI→ADDI,ADD,ADDI,SUB,LUI,ECALLfibonacci|fibonacci.s| 循环与分支|BEQ,ADD,MV→ADDI,J→JAL,ADDIfactorial|factorial.s| 嵌套循环|BEQ,MV,ADD,ADDI,J→JAL(通过重复加法实现嵌套乘法)hello.s程序是最简单的入口——它加载两个立即数,将它们相加,加上一个常数,相减,加载一个高位立即数,然后停机。fibonacci.s和factorial.s程序通过循环控制流对分支单元和 PC 加法器施加压力,特别是factorial.s演示了嵌套循环结构,大量演练了 PC 加法器中的分支跳转路径。 来源:hello.s, fibonacci.s, factorial.s接下来去哪
现在你已经对 TinyRISCV 是什么及其模块如何互连有了高层次的理解,推荐的阅读路径遵循从设置到深入理解的自然进程: 从这里开始 → 快速入门 —— 安装工具链,编译你的第一个程序,并在 5 分钟内看到处理器运行。 然后探索架构 → 架构概览 —— 详细了解单周期数据通路,包括信号流、多路选择和控制信号表。 深入各个模块 —— 遵循目录的自然分组:
- 分享
TinyRISCV 是一个用 Verilog 编写的极简单周期 RISC-V 处理器 ,实现了 RV32I 基础整数指令集——共计 40 条指令。本项目基于第一性原理设计,旨在提供教学级别的清晰度 ,项目中的每个模块都具有单一且明确的功能,这使得它成为希望从零开始理解真实处理器工作原理的开发者的理想起点。该处理器采用哈佛架构 ,拥有独立的指令内存和数据内存,每个时钟周期执行一条指令,并在遇到
- 核心控制 :控制单元 → 指令译码器 → 立即数生成器
- 数据通路 :ALU 设计 → 寄存器堆 → 分支单元
- 内存 :指令内存 → 数据内存
- PC 逻辑 :PC 寄存器 → PC 加法器与下一 PC 选择 参考资料 —— 在学习模块时根据需要查阅:
- RV32I 指令参考
- 控制信号参考
- 内存映射与地址布局 动手实践 :
- 编写汇编测试程序
- 仿真与波形调试
- 顶层模块集成 进阶理解 :
- 设计决策与权衡
- 验证与测试台策略 划线 写想法 提问
-
在Github README中添加Zread徽章添加徽章
来源
概述
- README.md
-
docs
- SUMMARY.md
-
rtl
-
core
- riscv_core.v
- pc_register.v
- control.v
- pc_adder.v
-
memory
- imem.v
- dmem.v
-
datapath
- alu.v
- imm_gen.v
- branch_unit.v
-
-
programs/asm
- hello.s
- fibonacci.s
-
factorial.s
快速上手
⌘K
-
- 分享
五分钟内启动并运行 TinyRISCV。本页将引导你完成整个工作流——从安装工具链,到编译你的第一个 RISC-V 汇编程序、运行周期精确的仿真,再到检查结果。无需具备任何 RISC-V 或 Verilog 经验;每个命令均可直接复制使用。
来源: README.md
工作流是如何串联的
TinyRISCV 遵循直观的三级流水线:将
.s汇编源码汇编 成 Verilog 十六进制镜像,使用 Icarus Verilog 仿真 处理器,然后使用你喜欢的查看器检查 VCD 轨迹。下图展示了每一个步骤及在它们之间流动的产物。 compile.sh objcopy -O verilog copy to sim/ generates vcd_viewer.py GTKWave / Surfer / vc.drom.io 📝 Assembly Source (.s file) 🔧 Object + ELF (.o → .elf) 💾 Hex Image (program.hex) ⚙️ Icarus Verilog (iverilog + vvp) 📊 VCD Trace (riscv_core.vcd) 🖥️ Execution Trace (terminal output) 🔬 Waveform View (GUI) 指令存储器 (imem) 在仿真时刻零通过$readmemh加载program.hex。这意味着你必须 在启动仿真之前将十六进制文件放置在sim/program.hex——该机制不支持运行时加载。 来源: programs/compile.sh, rtl/memory/imem.v, sim/Makefile前置条件
TinyRISCV 需要两类工具:用于将汇编代码转换为十六进制镜像的 RISC-V 交叉编译工具链 ,以及用于执行处理器模型的 HDL 仿真器 。下表列出了每个依赖项、其用途以及 macOS (Homebrew) 的推荐安装命令。Linux 用户应替换为其包管理器的等效命令。 工具| 用途| 安装命令 —|—|— Icarus Verilog (
iverilog)| 编译和仿真 Verilog RTL|brew install icarus-verilogGTKWave| 波形查看器(可选;参见下文替代方案)|brew install --cask gtkwaveriscv64-elf-gcc| RISC-V 交叉汇编器、链接器和 objcopy|brew install riscv64-elf-gcc安装 RISC-V 工具链后,请创建兼容性符号链接,以便构建脚本(调用riscv32-unknown-elf-*)能够找到这些工具: BASH Copy code sudo ln -s $(which riscv64-elf-as) /usr/local/bin/riscv32-unknown-elf-as sudo ln -s $(which riscv64-elf-ld) /usr/local/bin/riscv32-unknown-elf-ld sudo ln -s $(which riscv64-elf-gcc) /usr/local/bin/riscv32-unknown-elf-gcc sudo ln -s $(which riscv64-elf-objdump) /usr/local/bin/riscv32-unknown-elf-objdump sudo ln -s $(which riscv64-elf-objcopy) /usr/local/bin/riscv32-unknown-elf-objcopy 在 Apple Silicon macOS 上,Homebrew 安装到/opt/homebrew/bin/而不是/usr/local/bin/。请相应地调整符号链接目标路径,或者如上所示使用$(which ...)来自动解析正确的位置。 来源: README.md步骤 1 — 编译测试程序
TinyRISCV 附带了三个现成的汇编程序,逐步测试更多指令集: 程序| 演示内容| 关键指令 —|—|— hello.s| 基本算术和立即数加载|
li,add,addi,sub,lui,ecallfibonacci.s| 循环和条件分支|beq,add,mv,addi,j,ecallfactorial.s| 嵌套循环(通过重复加法实现乘法)|beq,mv,add,addi,j,ecall一次性编译所有程序: BASH Copy code cd programs ./compile.sh cd .. 该脚本会遍历programs/asm/中的每个.s文件,运行汇编器、链接器和objcopy,为每个程序生成一个 Verilog 兼容的十六进制文件。输出文件位于programs/hex/: Copy code programs/hex/ ├── hello.hex ├── fibonacci.hex └── factorial.hex 链接脚本将所有代码放置在地址0x00000000,这与处理器的复位向量相匹配——在rst_n取消断言后,PC 从地址零开始。在幕后,compile.sh对每个源文件执行三条命令:riscv32-unknown-elf-as汇编成目标文件,riscv32-unknown-elf-ld与linker.ld链接,riscv32-unknown-elf-objcopy -O verilog将.text段提取为$readmemh所期望的十六进制格式。 来源: programs/compile.sh, programs/linker.ld, programs/asm/hello.s步骤 2 — 将程序加载到仿真中
指令存储器模块在仿真启动时从其工作目录读取名为
program.hex的文件。将你选择的十六进制镜像复制到相应位置: BASH Copy code cp programs/hex/hello.hex sim/program.hex 之后若要切换程序,只需用不同的编译镜像(例如fibonacci.hex或factorial.hex)覆盖sim/program.hex并重新运行仿真即可。无需重新编译 Verilog——十六进制文件是在运行时读取的,而非固化在编译后的仿真文件中。 来源: rtl/memory/imem.v, README.md步骤 3 — 运行仿真
在
sim/目录下,执行: BASH Copy code cd sim make simulate 这个单一目标按顺序执行两件事:首先使用 Icarus Verilog 将所有 Verilog 源码(RTL + 测试平台)编译为riscv_core.vvp,然后使用vvp运行仿真。Makefile 会从rtl/core/、rtl/datapath/、rtl/memory/和rtl/decoder/收集每个.v文件,以及来自tb/riscv_core_tb.v的测试平台。该测试平台驱动一个 100 MHz 时钟(10 ns 周期),将rst_n保持低电平 20 ns,然后释放它并监视停机信号。在每个时钟上升沿,它会打印当前的 PC 和指令字。 来源: sim/Makefile, tb/riscv_core_tb.v步骤 4 — 检查结果
基于文本的执行轨迹
查看执行情况最快捷的方式是使用自带的 Python 分析器: BASH Copy code python3 ../tools/vcd_viewer.py riscv_core.vcd 它将解析 VCD 文件,提取
pc_out、instr和halt信号,并打印表格化的执行轨迹,最后附上摘要: Copy code ================================================================================ TINY RISC-V EXECUTION TRACE ================================================================================ Time PC Instruction Halt ——————————————————————————– 25 0x00000000 0x01300093 NO 35 0x00000004 0x01400113 NO 45 0x00000008 0x002081b3 NO … 255 0x00000018 0x00000073 YES ================================================================================ PROGRAM HALTED at time 255000 Final PC: 0x00000018 Total instructions executed: 7 ================================================================================ecall指令会触发停机条件——当控制单元解码到操作码1110011时,它会拉高halt信号,从而冻结 PC 寄存器并结束执行。波形可视化
若要进行周期级别的信号调试,请使用波形查看器打开 VCD 文件: 查看器| 安装| 最适用场景 —|—|— Surfer|
cargo install surfer| 快速,Rust 原生,对 Apple Silicon 友好 vc.drom.io| 无需安装——基于浏览器访问 https://vc.drom.io| 无需本地工具即可快速查看 GTKWave|brew install --cask gtkwave| 功能齐全,但在 Apple Silicon 上通过 Rosetta 运行可能会崩溃sim/wave.gtkw保存文件已为 GTKWave 预配置了有用的信号分组。对于 Surfer 或在线查看器,只需拖放sim/riscv_core.vcd即可。 来源: tools/vcd_viewer.py, rtl/core/control.v, sim/view_wave.sh故障排除
症状| 可能原因| 解决方法 —|—|—
riscv32-unknown-elf-as: command not found| 未创建符号链接| 重新运行前置条件中的ln -s命令program.hex: No such file or directory| 十六进制文件未复制到sim/| 运行cp programs/hex/hello.hex sim/program.hexProgram did not halt within timeout| 十六进制文件错误或汇编损坏| 验证.s文件是否以ecall结尾;使用./compile.sh重新编译 未生成 VCD 文件| 仿真在$dumpfile之前崩溃| 检查iverilog编译输出是否存在语法错误 GTKWave 在 macOS 上崩溃| Apple Silicon Rosetta 问题| 使用 Surfer (cargo install surfer) 或 vc.drom.io 在线查看器./compile.sh: Permission denied| 脚本不可执行| 运行chmod +x programs/compile.sh来源: sim/Makefile, README.md接下来做什么?
你已经成功在 TinyRISCV 上编译、加载、仿真并检查了你的第一个 RISC-V 程序。从这里开始,文档将根据你的目标分为两条路径:
- 分享
五分钟内启动并运行 TinyRISCV。本页将引导你完成整个工作流——从安装工具链,到编译你的第一个 RISC-V 汇编程序、运行周期精确的仿真,再到检查结果。无需具备任何 RISC-V 或 Verilog 经验;每个命令均可直接复制使用。
- 理解架构 → 从架构概览 开始,了解单周期数据通路如何将控制单元、ALU、寄存器堆和存储器连接成一个可工作的处理器。
- 编写自己的程序 → 跳转到编写汇编测试程序 ,学习如何编写用于测试特定指令类别的
.s文件。 - 使用波形调试 → 查看仿真与波形调试 ,深入了解信号追踪及常见陷阱。 有关所有文档页面的完整导图,请返回概览 。 划线 写想法 提问
-
在Github README中添加Zread徽章添加徽章
来源
- README.md
-
programs
- compile.sh
- linker.ld
-
asm
- hello.s
-
rtl
-
memory
- imem.v
-
core
- control.v
-
-
sim
- Makefile
- view_wave.sh
-
tb
- riscv_core_tb.v
-
tools
-
vcd_viewer.py
架构概览
⌘K
-
-
- 分享
TinyRISCV 是一款单周期 RISC-V 处理器 ,在恰好一个时钟周期内完成每条指令从开始到结束的执行。它采用哈佛架构 实现了 RV32I 基础整数指令集(40 条指令),具有物理分离的指令存储器和数据存储器,从而消除了因同时取指和数据访问而产生的结构冒险。该设计优先考虑教学清晰度而非性能:没有流水线,没有冒险逻辑,也没有微代码——每个控制信号都是当前指令的 opcode、funct3 和 funct7 字段的纯组合逻辑函数。处理器从地址
0x00000000启动,运行直至遇到ECALL指令(操作码1110011),然后无限期冻结程序计数器。 来源: riscv_core.v, control.v, README.md顶层架构
处理器由
riscv_core内部的十个模块扁平组合而成,所有模块间的连线均在顶层声明为线网。没有分层总线或请求/授予协议——每条连接都是直接的线网,使得数据流完全透明。下图展示了完整的信号拓扑结构,其中每个箭头代表顶层模块中的一个命名线网,边上的标签对应实际的 Verilog 信号名。 Memory Execute Decode Fetch PC Logic pc pc instr instr opcode, funct3, funct7 opcode rs1, rs2 reg_write, mem_read, mem_write, alu_src, mem_to_reg, branch, jump, alu_op, pc_src rs1data rs2_data, rs1_data rs2_data, rs1_data imm imm rs1_data branch_taken alu_src alu_op branch, jump pc_src alu_result mem_read_data alu_result pc_next PC Register _pc_register PC Adder pc_adder Instruction Memory imem Decoder decoder Immediate Generator imm_gen Control Unit control Register File regfile ALU alu Branch Unit branch_unit Data Memory dmemriscv_core模块自身没有任何时序逻辑——所有的状态都位于pc_register、regfile和dmem中。顶层模块纯粹是一个连线外壳,这意味着你只需阅读该文件即可追踪任何信号的源和宿。 来源: riscv_core.v模块清单
这十个模块分为四个功能类别。下表将每个模块映射到其源文件、RTL 目录以及一句职责描述。对每个模块的深入分析位于其专属的目录页面上。 类别| 模块| 源文件| 职责 —|—|—|— 核心控制|
pc_register|rtl/core/pc_register.v| 保存当前 PC;在halt时冻结;复位至0x00000000核心控制|pc_adder|rtl/core/pc_adder.v| 从三个来源计算pc_next:PC+4、PC+imm 或 rs1+imm 核心控制|control|rtl/core/control.v| 将 opcode/funct3/funct7 转换为 9 个控制信号 译码|decoder|rtl/decoder/decoder.v| 通过位切片提取六个指令字段 译码|imm_gen|rtl/datapath/imm_gen.v| 对五种指令格式(I/S/B/U/J)的立即数进行符号/零扩展 数据通路|regfile|rtl/datapath/regfile.v| 32×32 位寄存器阵列;x0 硬连线为零;2 读 1 写 数据通路|alu|rtl/datapath/alu.v| 10 种算术/逻辑运算,带零标志输出 数据通路|branch_unit|rtl/datapath/branch_unit.v| 评估 6 种分支条件码(BEQ/BNE/BLT/BGE/BLTU/BGEU) 存储器|imem|rtl/memory/imem.v| 4 KB 只读指令存储器;通过$readmemh加载 存储器|dmem|rtl/memory/dmem.v| 4 KB 读写数据存储器;支持字节/半字/字访问及符号扩展
来源: riscv_core.v, control.v, pc_register.v, pc_adder.v, decoder.v, imm_gen.v, regfile.v, alu.v, branch_unit.v, imem.v, dmem.v项目结构
代码仓库将关注点分离到
rtl/下的四个顶层目录中,每个目录对应上述的一个功能类别。仿真工具、测试程序和文档位于同级目录中。 Copy code TinyRISCV/ ├── rtl/ │ ├── core/ # PC 逻辑 + 控制单元 │ │ ├── riscv_core.v # ← 顶层连线外壳 │ │ ├── control.v # ← 9 信号控制生成器 │ │ ├── pc_register.v # ← 程序计数器触发器 │ │ └── pc_adder.v # ← 下一 PC 多路选择器 + 加法器 │ ├── decoder/ # 指令字段提取 │ │ └── decoder.v # ← 位切片字段提取器 │ ├── datapath/ # 计算与存储 │ │ ├── alu.v # ← 10 操作算术单元 │ │ ├── branch_unit.v # ← 6 条件评估器 │ │ ├── imm_gen.v # ← 5 格式立即数扩展器 │ │ └── regfile.v # ← 32×32 位寄存器阵列 │ └── memory/ # 指令与数据存储 │ ├── imem.v # ← 4 KB 指令 ROM │ └── dmem.v # ← 4 KB 数据 RAM(按字节寻址) ├── tb/ # 测试台 │ └── riscv_core_tb.v # Icarus Verilog 测试平台 ├── programs/ # 汇编程序与构建脚本 │ ├── asm/ # .s 源文件 │ ├── hex/ # 编译后的 .hex 输出 │ ├── compile.sh # 汇编器 + 链接器流水线 │ └── linker.ld # 链接脚本(起始地址 = 0x0) ├── sim/ # 仿真工作区 │ ├── Makefile # 编译 / 仿真 / 波形目标 │ └── wave.gtkw # GTKWave 信号分组 ├── tools/ # Python 辅助工具 │ ├── vcd_viewer.py # 基于文本的 VCD 轨迹查看器 │ └── publish_to_wechat.py # 文档发布器 └── docs/ # 文档(中文 + 英文) 来源: Makefile, linker.ld, riscv_core_tb.v, README.md单周期数据通路流
尽管处理器执行了教科书所描述的五个“阶段”(取指 → 译码 → 执行 → 访存 → 写回),但所有操作都在单个时钟周期内以组合逻辑完成。上升沿仅捕获三个状态:将新 PC 值写入
pc_register,将结果写入regfile,以及将存储数据写入dmem。下面的流程图展示了一条指令如何流经数据通路,每个节点由执行该步骤的 Verilog 模块标注。 pc_next FETCH PC Register → imem pc → instr DECODE decoder + control + imm_gen instr → fields + signals + imm EXECUTE regfile → ALU + branch_unit rs1/rs2 data → alu_result, branch_taken MEMORY ALU result → dmem addr → mem_read_data WRITE-BACK mux → regfile alu_result | mem_data | pc+4 → rd 数据通路末端的写回多路选择器根据两个控制信号从三个来源中进行选择。当jump有效时(JAL/JALR),寄存器堆接收pc + 4——即调用的返回地址。当mem_to_reg有效时(Load 指令),值来自数据存储器。否则,写回 ALU 结果。这种三路选择实现为单个三元链:write_back_data = jump ? pc_plus_4 : (mem_to_reg ? mem_read_data : alu_result)。 AUIPC 指令在 ALU 之前引入了一个特殊情况的多路选择器:alu_operand_a = (opcode == 7'b0010111) ? pc : rs1_data。这是唯一一条 ALU 接收 PC 作为操作数而非寄存器值的指令,它由专用的 assign 语句处理,而非由控制信号处理。 来源: riscv_core.v控制信号摘要
控制单元产生九个输出信号,控制数据通路中的每个多路选择器和使能引脚。下表总结了十种指令类别的信号编码。“X”表示无关值(该指令类型的任何使能路径都不会采样该信号)。 指令类型|
reg_write|mem_read|mem_write|alu_src|mem_to_reg|branch|jump|pc_src| ALU 操作 —|—|—|—|—|—|—|—|—|— R-type| 1| 0| 0| 0| 0| 0| 0| 00| funct3 + funct7 I-type (ALU)| 1| 0| 0| 1| 0| 0| 0| 00| funct3 + funct7 Load| 1| 1| 0| 1| 1| 0| 0| 00| ADD Store| 0| 0| 1| 1| X| 0| 0| 00| ADD Branch| 0| 0| 0| 0| X| 1| 0| 01| — JAL| 1| 0| 0| X| 0| 0| 1| 01| — JALR| 1| 0| 0| 1| 0| 0| 1| 10| ADD LUI| 1| 0| 0| 1| 0| 0| 0| 00| ADD AUIPC| 1| 0| 0| 1| 0| 0| 0| 00| ADD SYSTEM (ECALL)| 0| 0| 0| 0| 0| 0| 0| 00| —pc_src信号是控制流的关键选择器:00顺序推进(PC+4),01选择分支/跳转目标(PC+imm),10选择间接寄存器目标(最低位清零的 rs1+imm)。pc_adder模块将pc_src与branch_taken和jump标志结合,产生最终的pc_next值。 来源: control.v, pc_adder.v存储器架构
TinyRISCV 采用哈佛风格的存储器系统,具有两个占用非重叠地址范围的独立 4 KB 存储器。指令存储器为只读 且按字寻址 (1024 × 32 位条目),而数据存储器为读写 且按字节寻址 (4096 × 8 位条目),支持带正确符号扩展的字节、半字和字传输。 属性| 指令存储器 (
imem)| 数据存储器 (dmem) —|—|— 容量| 4 KB (1024 字)| 4 KB (4096 字节) 寻址方式| 字对齐 (addr[11:2])| 字节级 访问方式| 只读,组合逻辑读取| 读写,时钟同步写入 初始化|$readmemh("program.hex")| 零初始化 传输宽度| 仅 32 位| LB/LH/LW/LBU/LHU/SB/SH/SW 符号扩展| 不适用| 由 funct3 控制 文件|imem.v|dmem.v指令存储器使用addr[11:2]索引 1024 条目的阵列,这隐式丢弃了最低两位并强制字对齐。数据存储器使用 ALU 结果的低 12 位作为字节地址,funct3字段在运行时选择传输大小和有符号性。写入是同步的(边沿触发),而读取是组合逻辑的——这是一种匹配单周期执行模型的标准非对称 RAM 模式。 来源: imem.v, dmem.v, riscv_core.v, riscv_core.v关键设计特征
下表捕获了定义 TinyRISCV 能力范围的量化设计参数。这些数值是单周期、非流水线设计选择和 4 KB 存储器大小限制的直接结果。 特征| 值| 原理 —|—|— ISA| RV32I (40 条指令)| 足以运行真实程序;省略了 FENCE/CSR/EBREAK CPI| 1 (所有指令)| 单周期设计——无停顿,无气泡 寄存器数量| 32 × 32 位| 完整的 RV32I 规范;x0 硬连线为零 ALU 操作| 10| ADD/SUB/AND/OR/XOR/SLL/SRL/SRA/SLT/SLTU 分支条件| 6| BEQ/BNE/BLT/BGE/BLTU/BGEU 立即数格式| 5| I/S/B/U/J 带符号/零扩展 指令存储器| 4 KB (1024 字)| 仿真开始时加载;执行期间只读 数据存储器| 4 KB (4096 字节)| 按字节寻址,支持子字访问 PC 复位值|
0x00000000| 链接脚本将.text放置在起始地址 0x0 停机机制| ECALL (操作码1110011)| 冻结 PC 寄存器;无异常处理程序 流水线深度| 无| 所有逻辑在一个周期内以组合逻辑完成 关键时序路径端到端遍历整个数据通路:PC Register → imem → decoder → control + imm_gen → regfile → ALU → dmem → write-back mux → regfile write。这是在下一个时钟沿到来之前必须稳定的最长组合链,它最终决定了最大可达到的时钟频率。 来源: riscv_core.v, control.v, linker.ld后续去向
你刚刚阅读的架构概述是这片领地的地图。以下页面将带你深入了解每个模块的实现,从驱动所有其他组件的控制通路开始,然后按照依赖顺序依次介绍数据通路、存储器和 PC 逻辑。 从控制通路开始 ——它生成引导数据通路的每一个信号:
- 分享
TinyRISCV 是一款单周期 RISC-V 处理器 ,在恰好一个时钟周期内完成每条指令从开始到结束的执行。它采用哈佛架构 实现了 RV32I 基础整数指令集(40 条指令),具有物理分离的指令存储器和数据存储器,从而消除了因同时取指和数据访问而产生的结构冒险。该设计优先考虑教学清晰度而非性能:没有流水线,没有冒险逻辑,也没有微代码——每个控制信号都是当前指令的 opcode、funct3 和 funct7 字段的纯组合逻辑函数。处理器从地址
- 控制单元 — opcode/funct3/funct7 如何译码为 9 个控制信号
- 指令译码器 — 六个指令字段的位切片提取
- 立即数生成器 — 五种指令格式的符号/零扩展 然后探索在这些信号控制下执行的数据通路组件:
- ALU 设计 — 10 操作算术单元及其操作码映射
- 寄存器堆 — 双读单写寄存器阵列,x0 硬连线为零
- 分支单元 — 为 PC 加法器提供输入的 6 条件评估器 最后是存储器和 PC 子系统:
- 指令存储器 — 仿真开始时加载的按字寻址 ROM
- 数据存储器 — 带子字符号扩展的按字节寻址 RAM
- PC 寄存器 — 取指阶段中唯一的时序元件
- PC 加法器与下一 PC 选择 — 三源 PC 多路选择器 划线 写想法 提问
-
在Github README中添加Zread徽章添加徽章
来源
架构概述
-
rtl
-
core
- riscv_core.v
- control.v
- pc_register.v
- pc_adder.v
-
decoder
- decoder.v
-
datapath
- imm_gen.v
- regfile.v
- alu.v
- branch_unit.v
-
memory
- imem.v
- dmem.v
-
- README.md
-
sim
- Makefile
-
programs
- linker.ld
-
tb
-
riscv_core_tb.v
控制单元
⌘K
-
-
- 分享
控制单元 是 TinyRISCV 的大脑——一个纯组合逻辑模块,它检查当前指令的 opcode、funct3 和 funct7 字段,并产生九个控制信号,协调数据通路中的所有其他组件。在单周期处理器中,控制单元必须为每种指令类型 同时 发出正确的信号组合,使其成为将 ISA 的语义意图转化为硬件协作的唯一枢纽。理解这个模块是理解处理器如何从“这是什么指令?”过渡到“硬件应该做什么?”的关键。
在流水线中的位置
在深入探讨控制单元内部结构之前,有必要先了解它在数据流中的位置。译码器从指令字中提取原始位字段;控制单元接收其中三个字段(
opcode、funct3、funct7),并将其输出广播至寄存器堆、ALU、数据存储器和 PC 逻辑。下图展示了这些关系——请注意,控制单元没有反馈路径 ;它完全是当前指令的纯函数。 Consumers Control Signals Control Unit Inputs opcode 7b funct3 3b funct7 7b Opcode Dispatch\n+ funct3/funct7 Decode reg_write mem_read mem_write alu_src mem_to_reg branch jump alu_op 4b pc_src 2b Register File ALU Data Memory PC Adder Operand B MUX Write-back MUX 译码器(指令译码器 )为控制单元提供输入,而 ALU 设计 、寄存器堆 、数据存储器 和 PC 加法器与下一 PC 选择 页面则深入介绍了下游的信号消费方。 来源: control.v, riscv_core.v接口与信号字典
控制单元的端口列表经过刻意精简——三个输入,九个输出。这种极简的接口反映了一个设计决策:控制单元只需知道生成信号所需的信息,对数据值本身一无所知。 信号| 方向| 位宽| 描述 —|—|—|—
opcode| input| 7| 主操作码字段——选择指令类别funct3| input| 3| 次功能字段——选择类别内的子操作funct7| input| 7| 扩展功能字段——区分 ADD/SUB 和 SRL/SRAreg_write| output| 1| 寄存器堆写使能(高电平有效)mem_read| output| 1| 数据存储器读使能(高电平有效)mem_write| output| 1| 数据存储器写使能(高电平有效)alu_src| output| 1| ALU 操作数 B 来源:0 =rs2_data,1 =immmem_to_reg| output| 1| 写回来源:0 = ALU 结果,1 = 存储器读出数据branch| output| 1| 指示条件分支指令处于活动状态jump| output| 1| 指示无条件跳转(JAL/JALR)处于活动状态alu_op| output| 4| ALU 操作选择——直接驱动 ALU 的alu_op输入pc_src| output| 2| 下一 PC 来源:00= PC+4,01= PC+imm,10= rs1+immalu_src信号是单比特多路选择器选择信号,它决定 ALU 是对两个寄存器值进行运算(R 型),还是对寄存器和立即数进行运算(I 型、Load、Store、LUI、AUIPC、JALR)。它的消费方是riscv_core.v中的alu_operand_b赋值逻辑。 来源: control.v设计原则
三个架构选择决定了控制单元的典型特征。 安全默认值。
always @(*)块首先将每个输出赋为其“无操作”值——reg_write = 0、mem_read = 0、mem_write = 0、alu_src = 0、mem_to_reg = 0、branch = 0、jump = 0、alu_op = ALU_ADD和pc_src = PC_PLUS4。这意味着,如果操作码落入了default分支(或落入空的OP_SYSTEM分支),处理器将毫无副作用地推进到下一条指令,而不修改任何状态。这种防御性模式防止了未定义的控制信号在数据通路中传播。 操作码优先派发。 case 语句首先以opcode为键,仅在 R 型和 I 型分支中查阅funct3和funct7,以消除 ALU 操作的歧义。这反映了 RV32I 编码层次的规则:操作码决定指令的 类别 (算术、存储器、分支、跳转),而 funct3/funct7 决定该类别内的指令 变体 。 无状态,无时钟。 控制单元是一个单一的组合逻辑块。它在一个时钟周期内生成所有信号,这与 TinyRISCV 的单周期执行模型一致。没有微码 ROM,没有流水线寄存器,也没有时序元件——从{opcode, funct3, funct7}到控制信号的映射是一个纯查找表,通过 Verilog 的 case 逻辑实现。 来源: control.v操作码派发与信号映射
控制单元的核心是一个包含十个分支的
case (opcode)语句。每个分支发出该指令类别所需的最小信号集。下表总结了完整的映射关系——每个单元格均直接源自 Verilog 源码。 操作码| 类别|reg_write|mem_read|mem_write|alu_src|mem_to_reg|branch|jump|pc_src| ALU 操作来源 —|—|—|—|—|—|—|—|—|—|—0110011| R-type| 1| 0| 0| 0| 0| 0| 0|00| funct3 + funct7[5]0010011| I-type ALU| 1| 0| 0| 1| 0| 0| 0|00| funct3 + funct7[5]0110111| LUI| 1| 0| 0| 1| 0| 0| 0|00| ALU_ADD0010111| AUIPC| 1| 0| 0| 1| 0| 0| 0|00| ALU_ADD0000011| Load| 1| 1| 0| 1| 1| 0| 0|00| ALU_ADD0100011| Store| 0| 0| 1| 1| 0| 0| 0|00| ALU_ADD1100011| Branch| 0| 0| 0| 0| 0| 1| 0|01| ALU_ADD (默认)1101111| JAL| 1| 0| 0| 0| 0| 0| 1|01| ALU_ADD (默认)1100111| JALR| 1| 0| 0| 1| 0| 0| 1|10| ALU_ADD (默认)1110011| SYSTEM| 0| 0| 0| 0| 0| 0| 0|00| ALU_ADD (默认) 从这个表格中可以看出几个规律。只要 ALU 需要立即数操作数,就会置位alu_src = 1——这涵盖了所有 I 型格式(ALU-imm、Load、JALR)以及 U 型(LUI、AUIPC)和 Store。mem_to_reg = 1是 Load 指令独有的,因为只有这类指令的写回值来自数据存储器而非 ALU。pc_src仅对 Branch(01)、JAL(01)和 JALR(10)为非零值,反映了下一 PC 偏离默认 PC+4 的三种方式。jump信号具有双重用途。在riscv_core.v中,它选择pc_plus_4作为写回数据(将返回地址保存到rd中), 并且 通过与branch_taken进行或运算,在pc_adder.v中启用分支目标。这种双重角色解释了为什么 JAL 的pc_src = PC_BRANCH——PC 加法器使用了与条件分支相同的PC_BRANCH路径,但由于jump = 1,branch_taken || jump的条件始终为真。 来源: control.v, riscv_core.v, pc_adder.vALU 操作译码:两级查找
对于 R 型和 I 型 ALU 指令,控制单元执行两级译码。第一级通过
opcode选择指令类别;第二级将funct3(有时还包括funct7[5])映射为直接驱动 ALU 的 4 位alu_op信号。 000 0 1 001 010 011 100 101 0 1 110 111 opcode dispatch R-type / I-type funct3 funct7[5]? ALU_ADD (0000) ALU_SUB (0001) ALU_SLL (0101) ALU_SLT (1000) ALU_SLTU (1001) ALU_XOR (0100) funct7[5]? ALU_SRL (0110) ALU_SRA (0111) ALU_OR (0011) ALU_AND (0010) 黄色的决策节点突出了funct7[5]——即 RV32I 规范中所谓的第 30 位区分符 ——如何在共享相同funct3代码的指令对之间打破平局。ADD 与 SUB 均使用funct3 = 000;SRL 与 SRA 均使用funct3 = 101。控制单元通过检查funct7[5]是否被置位来解决这种歧义,当其被置位时分别产生ALU_SUB或ALU_SRA。alu_op编码在 control.v 和 alu.v 中通过匹配的localparam声明进行相同的定义。这是一个有意识的选择,以避免引入共享头文件(某些 Verilog 工具链对共享头文件的处理不佳),代价是需要在两个模块之间进行手动同步。下方的编码表展示了完整的映射:alu_op| 代码| 操作| 使用者 —|—|—|—ALU_ADD|0000|a + b| R-type ADD, I-type ADDI, LUI, AUIPC, Load, StoreALU_SUB|0001|a - b| R-type SUBALU_AND|0010|a & b| R-type AND, I-type ANDIALU_OR|0011|a | b| R-type OR, I-type ORIALU_XOR|0100|a ^ b| R-type XOR, I-type XORIALU_SLL|0101|a << b[4:0]| R-type SLL, I-type SLLIALU_SRL|0110|a >> b[4:0]| R-type SRL, I-type SRLIALU_SRA|0111|a >>> b[4:0]| R-type SRA, I-type SRAIALU_SLT|1000|signed(a) < signed(b) ? 1 : 0| R-type SLT, I-type SLTIALU_SLTU|1001|a < b ? 1 : 0| R-type SLTU, I-type SLTIU 请注意,对于所有非算术指令类别(Load、Store、Branch、JAL、JALR、SYSTEM),alu_op保持其默认值ALU_ADD。这是正确的,因为在这些类别中,ALU 仅用于计算地址(基址 + 偏移量),这始终是一个加法操作。 来源: control.v, control.v, alu.vPC 来源选择与跳转语义
pc_src信号是控制单元对 PC 加法器的指令,用于选择三种可能的下一 PC 值之一。其编码及在 PC 加法器中产生的行为如下:pc_src| 代码| 下一 PC 值| 条件| 使用者 —|—|—|—|—PC_PLUS4|00|pc + 4| 无条件| 所有非分支、非跳转指令PC_BRANCH|01|branch_taken ? pc + imm : pc + 4| 条件| Branch, JAL (通过jump无条件执行)PC_JALR|10|(rs1 + imm) & ~1| 无条件| JALRPC_BRANCH路径是两个非默认路径中较有趣的一个。在pc_adder.v中,逻辑为if (branch_taken || jump),这意味着只有当分支单元将条件评估为真, 或者 当指令为无条件跳转时,才会应用分支偏移量。对于 Branch 指令,控制单元置位branch = 1和pc_src = PC_BRANCH;然后分支单元根据funct3对rs1_data和rs2_data的比较独立确定branch_taken。对于 JAL,控制单元置位jump = 1和pc_src = PC_BRANCH;由于jump与branch_taken进行了或运算,因此目标始终会被选中。PC_JALR路径为 JALR 指令独有。它使用寄存器间接寻址模式:rs1_data + imm,并将最低有效位强制置零以保持对齐。控制单元为 JALR 设置alu_src = 1,以便 ALU 操作数 B 多路选择器传入立即数值,但值得注意的是,实际的下一 PC 计算并不 经过 ALU——它在pc_adder.v中独立计算。JALR 的alu_src = 1和alu_op = ALU_ADD默认设置产生的 ALU 结果恰好为rs1_data + imm,等于跳转目标,但此结果并未被使用,因为jump = 1选择了pc_plus_4进行写回(保存返回地址),而pc_src = PC_JALR将独立计算的目标路由至pc_next。 来源: control.v, control.v, pc_adder.v, riscv_core.v特殊情况:SYSTEM 与默认处理
OP_SYSTEM分支(opcode = 1110011)作为空块处理——控制单元除了默认值外不生成任何信号。这是因为 TinyRISCV 仅实现了 EBREAK/ECALL 停机机制,该机制是在riscv_core.v中通过assign halt = (opcode == 7'b1110011)外部检测的。停机信号流向 PC 寄存器,使其停止更新。不需要任何寄存器写入、存储器访问或 ALU 操作。这种最简处理意味着 SYSTEM 操作码实际上充当了“停止世界”指令。default分支同样为空。任何无法识别的操作码都会使所有信号保持安全默认值——处理器在 PC+4 处获取下一条指令,不进行任何状态修改,然后继续执行。虽然这可以对未定义指令提供鲁棒性保护(无破坏性写入),但这确实意味着未实现非法指令陷阱;该指令只是被简单地跳过。 来源: control.v, riscv_core.v控制单元决策流程
下图提供了控制单元决策逻辑的完整可视化,从操作码输入到最终的信号置位。每个叶节点按照
{reg_write, mem_read, mem_write, alu_src, mem_to_reg, branch, jump, pc_src}的顺序展示了完整的信号向量,并在alu_op有变化的地方单独标注。 1,0,0,0,0,0,0,00 1,0,0,1,0,0,0,00 1,0,0,1,0,0,0,00 alu_op = ADD 1,0,0,1,0,0,0,00 alu_op = ADD 1,1,0,1,1,0,0,00 alu_op = ADD 0,0,1,1,0,0,0,00 alu_op = ADD 0,0,0,0,0,1,0,01 alu_op = ADD 1,0,0,0,0,0,1,01 alu_op = ADD 1,0,0,1,0,0,1,10 alu_op = ADD 0,0,0,0,0,0,0,00 alu_op = ADD (halt handled externally) opcode 0110011 R-type 0010011 I-type ALU 0110111 LUI 0010111 AUIPC 0000011 Load 0100011 Store 1100011 Branch 1101111 JAL 1100111 JALR 1110011 SYSTEM alu_op ← funct3/funct7 decode alu_op ← funct3/funct7 decode Done Done Done Done Done Done Done Done 颜色分组揭示了自然的类别:绿色 代表寄存器-寄存器和寄存器-立即数 ALU 操作(它们共享相同的 funct3/funct7 子译码),蓝色 代表高位立即数指令(LUI/AUIPC——除了在控制单元外部处理的操作数 A 选择外,信号完全相同),黄色 代表存储器操作(Load/Store——通过mem_to_reg和mem_read/mem_write区分),红色 代表控制流(Branch/JAL/JALR——通过pc_src和jump区分),灰色 代表 SYSTEM(在控制信号层面实际上是空操作)。 来源: control.v信号如何被消费
每个控制信号路由至内核中特定的消费方。理解这些消费点有助于阐明控制单元为何要置位每个信号。
reg_write→ 寄存器堆。 驱动寄存器堆的write_enable端口。当其被解除断言时,时钟边沿不会修改任何寄存器。寄存器堆独立保护免受对x0(硬连线零)的写入,因此控制单元不需要检查rd == 0——它只需为任何在 语义上 写入目标寄存器的指令置位reg_write。 regfile.vmem_read/mem_write→ 数据存储器。 这两个信号控制数据存储器模块中的读写路径。它们永远不会被同时置位(没有指令既加载又存储),控制单元的安全默认模式确保了这一不变量得以保持。 dmem.valu_src→ 操作数 B 多路选择器。riscv_core.v中的赋值alu_operand_b = alu_src ? imm : rs2_data是一个单一的多路选择器,用于在寄存器和立即数之间选择 ALU 的第二个操作数。当alu_src = 0时,ALU 接收rs2_data(R 型算术);当alu_src = 1时,它接收来自立即数生成器 的符号扩展或高位立即数值。 riscv_core.vmem_to_reg→ 写回多路选择器。 赋值write_back_data = jump ? pc_plus_4 : (mem_to_reg ? mem_read_data : alu_result)是一个两级优先级选择器。jump信号具有最高优先级(保存 JAL/JALR 的返回地址),然后mem_to_reg在存储器数据(Load)和 ALU 结果(其他指令)之间进行选择。这意味着mem_to_reg对于跳转指令实际上是“无关项”——控制单元将其保持为 0,但无论如何它都会被忽略。 riscv_core.valu_op→ ALU。 4 位操作码直接驱动 ALU 的 case 语句。该编码通过匹配的localparam声明在control.v和alu.v之间共享。 alu.vbranch/jump/pc_src→ PC 加法器。 这三个信号共同决定下一个程序计数器。pc_src选择计算模式;branch_taken(来自分支单元)和jump控制计算出的分支目标是否真正被使用。有关完整细节,请参阅 PC 加法器与下一 PC 选择 。 pc_adder.v 来源: riscv_core.v, regfile.v, dmem.v, alu.v, pc_adder.v后续步骤
控制单元是派发枢纽——既然你已经了解了它如何生成信号,接下来可以沿着这些信号向下游探索:
- 分享
控制单元 是 TinyRISCV 的大脑——一个纯组合逻辑模块,它检查当前指令的 opcode、funct3 和 funct7 字段,并产生九个控制信号,协调数据通路中的所有其他组件。在单周期处理器中,控制单元必须为每种指令类型 同时 发出正确的信号组合,使其成为将 ISA 的语义意图转化为硬件协作的唯一枢纽。理解这个模块是理解处理器如何从“这是什么指令?”过渡到“硬件应该做什么?”的关键。
- 指令译码器 —— 如何从 32 位指令字中提取
opcode、funct3和funct7 - 立即数生成器 —— 如何为每种格式对
imm信号(由alu_src选择)进行符号扩展 - ALU 设计 ——
alu_op如何映射到算术和逻辑操作 - 分支单元 ——
funct3如何驱动控制条件跳转的branch_taken信号 - 控制信号参考 —— 用于快速查找的完整每指令信号表 划线 写想法 提问
-
在Github README中添加Zread徽章添加徽章
来源
控制单元
-
rtl
-
core
- control.v
- riscv_core.v
- pc_adder.v
-
datapath
- alu.v
- regfile.v
-
memory
-
dmem.v
指令译码器
⌘K
-
-
-
- 分享
指令译码器是处理器的读取透镜 ——它从内存中取出原始的 32 位指令字,并将其拆分为其他模块完成工作所需的具名字段。在 TinyRISCV 中,译码器被刻意设计得极为精简:没有状态机,没有决策逻辑,只有六个清晰的线网赋值,将位区间映射到诸如
opcode、rd、rs1和funct3等语义标签。这种简单性是刻意为之的——它使 RV32I 指令格式变得具体且易于调试,并将“各个位处于什么位置”的问题与由控制单元 处理的“这些位代表什么含义”的问题清晰地区分开来。 来源: decoder.v, riscv_core.vRV32I 指令格式全景
在理解译码器提取了什么之前,你需要先理解它是 从什么之中 提取的。每条 RV32I 指令的宽度均为 32 位,但这 32 位会根据指令类型被切割成不同的布局。规范定义了五种核心格式——R、I、S、B、J ——以及 LUI 和 AUIPC 使用的 U 格式。核心要点在于,某些字段 总是 出现在相同的位位置,无论格式如何:opcode 始终位于位 [6:0],目标寄存器
rd始终占据位 [11:7],而funct3始终位于位 [14:12]。这种一致的布局使得简单的位置译码器成为可能。 格式| 位 [31:25]| 位 [24:20]| 位 [19:15]| 位 [14:12]| 位 [11:7]| 位 [6:0] —|—|—|—|—|—|— R 型| funct7| rs2| rs1| funct3| rd| opcode I 型| imm[11:5]| imm[4:0]| rs1| funct3| rd| opcode S 型| imm[11:5]| rs2| rs1| funct3| imm[4:0]| opcode B 型| imm[12|10:5]| rs2| rs1| funct3| imm[4:1|11]| opcode U 型| imm[31:12]| —| —| —| rd| opcode J 型| imm[20|10:1|11|19:12]| —| —| —| rd| opcode 请注意,在 R、I、S 和 B 格式中,rs1和funct3是如何稳稳地固定在位 [19:15] 和 [14:12] 的。译码器正是利用了这种对齐方式——它不需要知道自己正在查看的是 哪种 格式就能提取这些公共字段。针对具体格式的消歧工作被推迟到了立即数生成器 中,该生成器使用opcode来正确地重组分散的立即数位。 来源: decoder.v, architecture_zh.md译码器模块:端口接口与实现
译码器的接口是组合清晰性的典范——一个 32 位输入,六个输出,零控制信号。它是一个纯组合逻辑 模块,没有时钟,没有复位,也没有寄存器。当指令字发生变化时,输出会瞬时更新(经过传播延迟后)。 Decoded Fields Decoder — Bit Slicing 32-bit Instruction Word instr[31:0] decoder opcode[6:0] rd[4:0] funct3[2:0] rs1[4:0] rs2[4:0] funct7[6:0] 其实现是六个
assign语句,每个语句执行直接的位区间提取: 输出| 位区间| 宽度| 语义含义 —|—|—|—opcode| instr[6:0]| 7 位| 指令类型(R 型、I 型、分支等)rd| instr[11:7]| 5 位| 目标寄存器索引 (x0–x31)funct3| instr[14:12]| 3 位| 指令类型内的子操作选择器rs1| instr[19:15]| 5 位| 第一源寄存器索引rs2| instr[24:20]| 5 位| 第二源寄存器索引funct7| instr[31:25]| 7 位| 扩展子操作选择器(仅限 R 型) 这六个线网构成了下游模块使用的完整译码表示。opcode告知控制单元 这是 什么类型 的指令;funct3和funct7共同指定了 具体的操作 (例如,ADD 与 SUB);而rd、rs1、rs2则对寄存器堆 进行寻址,用于操作数读取和结果写回。 来源: decoder.v具体演练:译码真实指令
通过真实指令观察译码器的实际工作,能将抽象的位映射巩固为实用的知识。让我们通过译码器追踪三条代表性指令。 示例 1:
ADD x3, x1, x2(R 型)—— 机器码:0x002081B3二进制形式:0000000 00010 00001 000 00011 0110011。译码器将其切片为opcode=0110011(R 型),rd=00011(x3),funct3=000(ADD/SUB),rs1=00001(x1),rs2=00010(x2),funct7=0000000(ADD,而非 SUB)。随后控制单元读取opcode=0110011+funct3=000+funct7[5]=0,并驱动alu_op=ALU_ADD,reg_write=1,alu_src=0。 示例 2:ADDI x3, x1, -1(I 型)—— 机器码:0xFFF08193二进制形式:111111111111 00001 000 00011 0010011。译码器提取出opcode=0010011(I 型 ALU),rd=00011(x3),funct3=000(ADDI),rs1=00001(x1),rs2=11111(这实际上是 imm[4:0]——但译码器并不关心,它只是提取位),funct7=1111111(这实际上是 imm[11:5])。rs2和funct7字段会被立即数生成器 重新解释为 12 位有符号立即数的组成部分。 示例 3:BEQ x1, x2, offset(B 型)—— 机器码:0x00208463二进制形式:000000 00010 00001 000 01000 1100011。译码器输出opcode=1100011(分支),funct3=000(BEQ),rs1=00001(x1),rs2=00010(x2)。请注意,此处的rd=01000和funct7=0000000并不是寄存器/操作字段——它们编码了分支偏移量的片段。同样,译码器只是按位置提取;语义重组是其他模块的职责。 译码器在设计上对格式是不可知的。在 I/S/B/J 型指令中,名为rd、rs2和funct7的字段可能携带立即数数据——译码器不作区分。如果你在调试时发现 I 型指令的rs2=0x1F,请不要惊慌:那是立即数的低 5 位,而不是寄存器 x31。 来源: decoder.v, control.v, control.v译码器在核心数据流中的角色
译码器位于译码阶段的核心,充当一个扇出枢纽 ,将提取的字段同时广播给多个消费模块。理解谁消费了什么——以及为什么——揭示了译码器设计背后的架构逻辑。 opcode, funct3, funct7 opcode rs1, rs2 rd funct3 opcode Control signals imm[31:0] Instruction Memory instr[31:0] Decoder Control Unit Immediate Generator Register File (read addresses) Register File (write address) Branch Unit Halt Detection (ECALL) ALU, DMEM, PC Logic, Muxes ALU Operand Mux 追踪顶层 riscv_core.v 中的连接,我们可以看到译码器的输出分支到了五个不同的消费者: 译码器输出| 消费模块| 目的 —|—|—
opcode| 控制单元| 确定指令类别,驱动所有控制信号opcode| 立即数生成器| 选择要应用的符号扩展模式opcode| 停机逻辑 (riscv_core.v第 33 行)| 检测SYSTEMopcode (0b1110011) 用于 ECALL 停机funct3,funct7| 控制单元| 解析子操作(ADD 与 SUB,SRL 与 SRA 等)funct3| 分支单元| 选择比较类型(BEQ, BNE, BLT, BGE, BLTU, BGEU)funct3| 数据存储器| 选择加载/存储宽度和符号扩展行为rs1,rs2| 寄存器堆| 用于操作数读取的读端口地址rd| 寄存器堆| 用于结果写回的写端口地址 这种扇出模式就是为什么译码器是一个独立模块,而不是riscv_core.v中的内联接线的原因——它为指令字的结构提供了一个命名的、有文档记录的契约 。任何需要理解指令字段的模块都通过译码器定义良好的端口接口来接收它们,而不是直接索引instr。 来源: riscv_core.v, riscv_core.v, riscv_core.v, branch_unit.v译码字段实战:opcode 与 funct3 作为两级选择器
RV32I ISA 采用两级译码层次结构 :7 位的
opcode标识指令类别( 哪种 操作),而 3 位的funct3(有时结合funct7[5])标识具体的子操作。理解这种层次结构是在阅读控制单元逻辑时不迷失方向的关键。 第一级——TinyRISCV 支持的 Opcode 类别: Opcode| 十六进制| 类别| 译码器含义 —|—|—|—0110011| 0x33| R 型| 寄存器-寄存器 ALU 操作0010011| 0x13| I 型 ALU| 寄存器-立即数 ALU 操作0110111| 0x37| LUI| 加载高位立即数0010111| 0x17| AUIPC| 将高位立即数加到 PC0000011| 0x03| Load| 内存读取0100011| 0x23| Store| 内存写入1100011| 0x63| Branch| 条件分支1101111| 0x6F| JAL| 跳转并链接1100111| 0x67| JALR| 跳转并链接寄存器1110011| 0x73| SYSTEM| ECALL(停机) 第二级——R 型和 I 型中的 funct3 子操作: funct3| R 型操作| I 型操作| funct7[5] 消歧? —|—|—|—000| ADD / SUB| ADDI| 是(R 型:0=ADD, 1=SUB)001| SLL| SLLI| 否010| SLT| SLTI| 否011| SLTU| SLTIU| 否100| XOR| XORI| 否101| SRL / SRA| SRLI / SRAI| 是(0=SRL, 1=SRA)110| OR| ORI| 否111| AND| ANDI| 否 只有两个 funct3 值——000和101——需要funct7[5]位来解决 ADD/SUB 和 SRL/SRA 之间的歧义。控制单元通过三元运算符检查funct7[5]:(funct7[5]) ? ALU_SUB : ALU_ADD和(funct7[5]) ? ALU_SRA : ALU_SRL。这是译码器的funct7输出唯一重要的场景——对于所有其他 R 型和 I 型指令,funct7要么全为零,要么被忽略。 在波形中追踪控制信号时,首先关注opcode以将指令缩小到某个类别,然后检查funct3确定具体操作。只有在funct3=000或funct3=101时才去查看funct7[5]。这种两步阅读顺序反映了控制单元自身的 case 结构,并能显著加快调试速度。 来源: control.v, control.v, control.v译码器不做什么
初学者常犯的一个错误是期望译码器去 解释 指令——决定“这是一个 ADD”或“这是一个分支”。在 TinyRISCV 的架构中,译码器严格来说是一个结构分解器 。它回答的问题是“哪些位在什么位置?” _,而不是_ “这些位代表什么含义?”。这种解释职责被分配到了另外三个模块中:
- 分享
指令译码器是处理器的读取透镜 ——它从内存中取出原始的 32 位指令字,并将其拆分为其他模块完成工作所需的具名字段。在 TinyRISCV 中,译码器被刻意设计得极为精简:没有状态机,没有决策逻辑,只有六个清晰的线网赋值,将位区间映射到诸如
- 控制单元 ——解释
opcode+funct3+funct7以生成控制信号(reg_write, alu_src, alu_op 等) - 立即数生成器 ——解释
opcode以重组分散的立即数位并应用符号扩展 - 分支单元 ——解释
funct3以评估分支条件(BEQ, BNE, BLT, BGE, BLTU, BGEU) 这种关注点分离意味着译码器是 唯一 一个直接按位位置索引原始指令字的模块。其他每个模块都使用译码器的具名输出,这使得系统更易于理解、测试和修改。如果 ISA 假设性地改变了某个字段的位置,你只需更新译码器即可——控制单元和立即数生成器将保持不变。 职责| 模块| 关键输入| 关键输出 —|—|—|— 位提取| 译码器|instr[31:0]|opcode, rd, rs1, rs2, funct3, funct7信号生成| 控制单元|opcode, funct3, funct7|reg_write, mem_read, alu_op, ...立即数组装| 立即数生成器|instr[31:0], opcode|imm[31:0](符号扩展) 分支评估| 分支单元|funct3, operand_a, operand_b|branch_taken来源: decoder.v, control.v, imm_gen.v, branch_unit.v在波形中阅读译码器
在使用 GTKWave 进行调试时(参见仿真与波形调试 ),你经常需要验证指令是否被正确译码。以下是一种根据指令字读取译码器输出的实用方法:
- 首先将
instr[31:0]添加到波形中——以十六进制显示。这是你的参考基准。 - 添加
opcode[6:0]——如果以二进制显示,你可以直接将其与上面的 opcode 表进行匹配。十六进制表示:0x33= R 型,0x13= I 型,0x63= 分支等。 - 以二进制添加
funct3[2:0]——这让你能一目了然地看到子操作。 - 以无符号十进制添加
rs1[4:0]和rs2[4:0]——这会显示实际的寄存器编号(1 = x1/ra, 2 = x2/sp 等),使其比二进制更具可读性。 - 以无符号十进制添加
rd[4:0]——用于写回验证的目标寄存器。 - 交叉核对 :根据 RV32I 位映射手动译码十六进制指令。例如,
0x002081B3→ 位 [6:0] =0110011= R 型 ✓,位 [14:12] =000= ADD ✓,位 [31:25] =0000000→funct7[5]=0→ ADD 而非 SUB ✓。 TinyRISCV 中的测试台会在每个时钟边沿打印PC和Instruction,为你提供了一个基于文本的辅助工具,用于将译码器输出与已知指令进行交叉参考。 来源: riscv_core_tb.v, wave.gtkw下一步
现在你已经理解了译码器是如何从原始指令字中提取字段的,接下来的自然步骤是跟随这些字段进入它们的消费模块:
- 首先将
- 控制单元 ——了解
opcode、funct3和funct7如何被转化为驱动整个数据通路的控制信号。 - 立即数生成器 ——学习相同的
opcode如何被用于将分散的立即数位重组为统一的 32 位有符号值。 - ALU 设计 ——追踪
alu_op(由控制单元从funct3/funct7派生)如何选择实际的算术或逻辑操作。 划线 写想法 提问 -
在Github README中添加Zread徽章添加徽章
来源
指令译码器
-
rtl
-
decoder
- decoder.v
-
core
- riscv_core.v
- control.v
-
datapath
- branch_unit.v
- imm_gen.v
-
-
docs
- architecture_zh.md
-
tb
- riscv_core_tb.v
-
sim
-
wave.gtkw
立即数生成器
⌘K
-
-
- 分享
立即数生成器 (
imm_gen) 是负责提取并符号扩展嵌入在每个需要立即数的 RV32I 指令中的立即操作数 的数据通路组件。与整洁地打包在固定 5 位字段中的寄存器操作数不同,立即数散布在指令字的非连续位范围内,并且其布局因指令格式而异。imm_gen模块解决了这种碎片化问题,产生统一的 32 位符号扩展结果,该结果同时馈入 ALU (用于算术和逻辑运算)和 PC 加法器 (用于分支和跳转目标计算)。 来源:imm_gen.v, riscv_core.v模块接口与集成
imm_gen模块提供了一个极简的组合逻辑接口:它接收原始的 32 位指令字和 7 位操作码,并输出单个 32 位立即数。操作码充当格式选择器 ——它决定应用哪条位提取规则,因为操作码在 RV32I 中唯一标识了指令格式。 端口| 方向| 位宽| 描述 —|—|—|—instr| input| 32| 来自指令存储器的原始指令字opcode| input| 7| 操作码字段 (instr[6:0]),用作格式选择器imm| output| 32| 符号扩展(或零填充)的 32 位立即数 该模块在 riscv_core.v 中被实例化为imm_generator,与指令译码器 并行接收instr和opcode。其输出imm流入两个关键路径:ALU 的操作数 B 多路选择器(当alu_src = 1时被选中)以及用于计算分支和跳转目标的 PC 加法器 。这种双消费者架构意味着单次提取操作可以同时服务于执行阶段和下一 PC 逻辑——这是单周期设计的一个关键效率优势。 来源:imm_gen.v, riscv_core.v, riscv_core.v五种立即数格式
RV32I 定义了五种不同的立即数格式 ,每种格式将立即数位散布在 32 位指令字的不同区域。这种散布并非随意——这是一种经过深思熟虑的编码设计,旨在最大化格式之间的重叠,从而降低硬件中的布线复杂度。
imm_gen模块通过对操作码执行单个case语句来实现所有五种格式。I 型立即数 (OP_IMM / OP_LOAD / OP_JALR)
I 型立即数是最简单的格式。12 位立即数占据指令的
[31:20]位——这是一个连续字段,使用复制运算符, instr[31:20]}将其符号扩展 至 32 位。此格式服务于三类指令:含立即数的整数运算(addi、slti、andi、ori、xori、slli、srli、srai)、加载指令(lb、lh、lw、lbu、lhu)以及间接跳转jalr。符号扩展确保负偏移量(例如addi x3, x3, -1)能够被正确表示为 32 位二进制补码值。 Copy code 指令:[31:20] = imm[11:0], [19:15] = rs1, [14:12] = funct3, [11:7] = rd, [6:0] = opcode 输出:, instr[31:20]} → 32位符号扩展S 型立即数 (OP_STORE)
存储指令(
sw、sh、sb)将立即数拆分至两个非连续字段:高 7 位位于instr[31:25],低 5 位位于instr[11:7](与rd字段位置重叠)。重组方式为, instr[31:25], instr[11:7]},产生符号扩展的 32 位值。这种拆分是有意为之的——通过将低 5 位放置在原本属于rd的位置,rs1和rs2字段分别保持了与 I 型和 R 型格式相同的位置,从而简化了寄存器堆的访问逻辑。 Copy code 指令:[31:25] = imm[11:5], [24:20] = rs2, [19:15] = rs1, [14:12] = funct3, [11:7] = imm[4:0] 输出:, instr[31:25], instr[11:7]} → 32位符号扩展B 型立即数 (OP_BRANCH)
分支指令(
beq、bne、blt、bge、bltu、bgeu)具有最复杂的立即数布局。12 位有符号偏移量分布在四个 独立的位范围内:instr[31](符号位)、instr[7](第 11 位)、instr[30:25](第 10:5 位)和instr[11:8](第 4:1 位)。由于分支目标必须半字对齐,最低有效位(LSB)始终为零(隐式编码)。完整的重组方式为, instr[31], instr[7], instr[30:25], instr[11:8], 1'b0}。这种看似古怪的位放置最大化了与 I 型和 S 型格式的重叠,共享了符号位和instr[30:25]区域。 Copy code 指令:[31]=imm[12], [30:25]=imm[10:5], [24:20]=rs2, [19:15]=rs1, [14:12]=funct3, [11:8]=imm[4:1], [7]=imm[11] 输出:, instr[31], instr[7], instr[30:25], instr[11:8], 1’b0} → 32位符号扩展U 型立即数 (OP_LUI / OP_AUIPC)
U 型格式携带放置在
instr[31:12]的 20 位上部立即数 ,左移 12 位。与其他格式不同,该立即数不进行符号扩展 ——它仅与 12 个零位拼接:{instr[31:12], 12'b0}。此设计服务于lui(加载上部立即数)和auipc(将上部立即数加到 PC),这两条指令用于构造大型 32 位常量。结合后续的addi或jalr,它们可以构建任何 32 位值:lui将 20 位置于高半部分,addi填充低 12 位(通过符号扩展处理两半之间的进位)。 Copy code 指令:[31:12] = imm[31:12], [11:7] = rd, [6:0] = opcode 输出:{instr[31:12], 12’b0} → 32位,无符号扩展J 型立即数 (OP_JAL)
jal(跳转并链接)指令使用 J 型格式,该格式跨四个位范围编码 20 位有符号偏移量:instr[31](符号位,第 20 位)、instr[19:12](第 10:1 位)、instr[20](第 11 位)和instr[30:21](第 19:10 位)。与 B 型类似,其 LSB 隐式为零。重组方式为, instr[31], instr[19:12], instr[20], instr[30:21], 1'b0}。这提供了相对于当前 PC 的 ±1 MiB 跳转范围——足以满足大多数函数内和模块内跳转的需求。 Copy code 指令:[31]=imm[20], [30:21]=imm[10:1], [20]=imm[11], [19:12]=imm[19:12], [11:7]=rd, [6:0]=opcode 输出:, instr[31], instr[19:12], instr[20], instr[30:21], 1’b0} → 32位符号扩展 来源:imm_gen.v格式对比与位字段映射
下表总结了所有五种格式、其指令类别、原始立即数位宽、符号扩展行为以及触发每种情况的操作码。 格式| 指令| 原始位宽| 是否符号扩展?| 操作码| 关键位范围 —|—|—|—|—|— I 型|
addi,lw,jalr, …| 12 位| 是 (第 31 位)|0010011,0000011,1100111|instr[31:20]S 型|sw,sh,sb| 12 位| 是 (第 31 位)|0100011|instr[31:25]+instr[11:7]B 型|beq,bne,blt, …| 13 位 (含隐式 0)| 是 (第 31 位)|1100011|instr[31,7,30:25,11:8]+0U 型|lui,auipc| 20 位| 否 (零填充)|0110111,0010111|instr[31:12]+12'b0J 型|jal| 21 位 (含隐式 0)| 是 (第 31 位)|1101111|instr[31,19:12,20,30:21]+0下图说明了立即数位如何散布在每种格式的 32 位指令中,直观地展示了格式之间的结构重叠。 RV32I 指令位布局 符号扩展 符号扩展 符号扩展 + LSB=0 低 12 位零填充 符号扩展 + LSB=0 I 型: imm[11:0] 位于 [31:20] S 型: imm[11:5] 位于 [31:25], imm[4:0] 位于 [11:7] B 型: imm[12|10:5] 位于 [31|30:25], imm[4:1|11] 位于 [11:8|7] U 型: imm[31:12] 位于 [31:12] J 型: imm[20|10:1|11|19:12] 位于 [31|30:21|20|19:12] 32 位立即数 B 型和 J 型格式始终产生偶数偏移量,因为其 LSB 被硬连线为1'b0。如果在仿真过程中观察到奇数分支目标,则说明立即数提取不正确——末尾的零位不是可选的,而是 RV32I 规范在架构层面强制要求的。 来源:imm_gen.v实现详解
该实现是一个单个组合逻辑
always @(*)块,其中包含由操作码驱动的case语句。每个 case 分支执行一次 位重组操作——没有中间变量,没有时序逻辑,没有时钟。这是 Verilog 中纯组合逻辑硬件模块的典型模式。操作码到格式的映射
该模块为其识别的操作码定义了七个 localparam 常量,与控制单元 的操作码定义完全匹配。三个操作码共享 I 型提取(
OP_IMM、OP_LOAD、OP_JALR),两个共享 U 型提取(OP_LUI、OP_AUIPC)。这种分组之所以可行,是因为这些操作码类别之间的立即数位布局是相同的——操作码只决定处理器对立即数 执行什么操作 ,而不决定立即数在指令中的 位置 。 Copy code OP_IMM = 7’b0010011 → I 型 (addi, slti, andi, ori, xori, slli, srli, srai) OP_LOAD = 7’b0000011 → I 型 (lb, lh, lw, lbu, lhu) OP_JALR = 7’b1100111 → I 型 (jalr) OP_STORE = 7’b0100011 → S 型 (sb, sh, sw) OP_BRANCH = 7’b1100011 → B 型 (beq, bne, blt, bge, bltu, bgeu) OP_LUI = 7’b0110111 → U 型 (lui) OP_AUIPC = 7’b0010111 → U 型 (auipc) OP_JAL = 7’b1101111 → J 型 (jal)通过 Verilog 复制运算符进行符号扩展
符号扩展机制使用 Verilog 的复制运算符
{N{bit}},它将单个位复制 N 次。对于 I 型,, instr[31:20]}取 12 位立即数的 MSB(指令的第 31 位)并将其复制 20 次作为高位,然后附加原始的 12 位字段。如果第 31 位为1,则结果为负的 32 位二进制补码数;如果为0,则为正数。这在功能上等同于符号扩展,但被表示为单个拼接表达式——简洁、可综合且明确无歧义。默认情况与安全性
default分支输出32'b0。这处理了两种情况:不携带立即数的OP_SYSTEM操作码(1110011,用于ecall/ebreak),以及任何损坏或未定义的指令字。在这两种情况下,零立即数都是无害的——控制单元 不会为这些操作码置位alu_src或pc_src,因此imm输出将被下游消费者忽略。 来源:imm_gen.v, control.v数据流:立即数的去向
孤立地理解
imm_gen是必要但不充分的——其输出驱动着两条不同的数据通路,而控制信号决定了对于任何给定指令哪条路径处于活动状态。 路径 1 — ALU 操作数 :当alu_src = 1(由控制单元 为 I 型、S 型、U 型和 JALR 指令设置)时,多路选择器选择imm而非rs2_data作为 ALU 的第二个操作数。这就是addi x3, x3, -1如何添加立即数-1而非寄存器值,以及sw x2, 8(x1)如何使用立即数8作为内存地址偏移量的原理。 路径 2 — PC 加法器 :当pc_src = PC_BRANCH(分支和 JAL)或pc_src = PC_JALR(间接跳转)时,PC 加法器 直接使用imm。对于分支,pc_next = pc + imm给出相对偏移量;对于jalr,pc_next = (rs1_data + imm) & ~1计算出清除 LSB 后的绝对目标地址。值得注意的是,对于auipc,ALU 也会计算pc + imm——控制单元通过 riscv_core.v 中的独立多路选择器将pc(而非rs1_data)路由为alu_operand_a。 在调试波形跟踪时,imm输出是一个强大的诊断信号。如果addi产生了意外的 ALU 结果,请首先验证imm——提取和符号扩展逻辑是译码阶段对格式最敏感的部分。对于分支指令,在检查 PC 加法器输出之前,请确认imm具有偶数值(LSB = 0)。 来源:riscv_core.v, pc_adder.v, control.v测试程序中的实际示例
该项目的汇编程序演示了每种立即数格式的实际运作。通过跟踪这些示例,可以揭示汇编器如何将伪指令编码为实际的 RV32I 格式,以及
imm_gen如何恢复原始值。 以斐波那契程序中的addi x3, x3, -1指令为例。汇编器将-1作为 12 位二进制补码值0xFFF编码在 I 型字段instr[31:20]中。imm_gen提取instr[31:20] = 12'hFFF,并将第 31 位(即1)符号扩展二十次,产生32'hFFFFFFFF——即-1的 32 位表示。然后 ALU 将此值加到x3上,正确地递减了计数器。 对于hello.s中的lui x6, 0x12345指令,上部立即数0x12345被放置在instr[31:12]。imm_gen将其与 12 个零位拼接,产生32'h12345000。由于lui设置alu_src = 1并且 ALU 将此值加到清零的rs1_data上(实际上相当于移动操作),x6接收到了值0x12345000。 斐波那契程序中的beq x3, x0, done指令使用了 B 型格式。汇编器计算从当前 PC 到done标签的偏移量,将其编码为 13 位有符号值(隐含 LSB=0),并将其分布到四个 B 型位范围内。imm_gen重组这些片段并进行符号扩展,从而为分支单元 和 PC 加法器产生正确的 PC 相对偏移量。 来源:fibonacci.s, hello.s, factorial.s后续步骤
了解了立即数生成器的提取逻辑后,你可以进一步探究其输出如何被下游模块消费:
- 分享
立即数生成器 (
- ALU 设计 — 了解当
alu_src被置位时,imm值如何作为operand_b进入 ALU - 分支单元 — 理解分支条件是如何评估的,随后应用
imm偏移量 - PC 加法器与下一 PC 选择 — 追踪
imm如何参与分支、跳转和jalr目标计算 - 控制信号参考 — 查看哪些操作码设置
alu_src = 1以激活立即数通路 划线 写想法 提问 -
在Github README中添加Zread徽章添加徽章
来源
立即数生成器
-
rtl
-
datapath
- imm_gen.v
-
core
- riscv_core.v
- control.v
- pc_adder.v
-
-
programs/asm
- fibonacci.s
- hello.s
- factorial.s
Syntax error in textmermaid version 11.6.0
—
ALU 设计
⌘K
-
- 分享
算术逻辑单元 (ALU) 是 TinyRISCV 的计算核心——一个纯组合逻辑模块,在 4 位操作码的指引下,将两个 32 位操作数转换为计算结果。它被刻意设计得极其精简:十种操作,零状态,一个辅助标志。这种精简并非局限,而是设计理念的体现。通过将 ALU 严格限制为仅满足 RV32I 基础整数指令集的需求,TinyRISCV 实现了一条极其易于审查、自然可综合且足以支持单周期执行的数据通路。ALU 不评估分支条件——该职责属于专用的分支单元 ——它也不管理操作数的路由——那是由控制单元 和顶层模块 来协调的。它所做的,且擅长做的,就是计算。
来源: alu.v
模块接口与信号约定
ALU 提供了精简的五信号接口,清晰地区分了数据输入、控制输入和数据输出。两个 32 位操作数由数据通路的操作数选择逻辑馈入,4 位
alu_op操作码来自控制单元,该模块输出一个 32 位的result和一个 1 位的zero标志。所有信号均为组合逻辑——该模块内部没有时钟、没有复位、也没有推断出任何寄存器。 信号| 方向| 位宽| 描述 —|—|—|—operand_a| input| 32| 主操作数 (rs1 数据或 PC)operand_b| input| 32| 次操作数 (rs2 数据或立即数)alu_op| input| 4| 操作选择码result| output| 32| 计算结果zero| output| 1| 当结果为零时置位 接口约定十分直观:对于operand_a、operand_b和alu_op的任意组合,result和zero输出都会在一个组合逻辑传播延迟内稳定下来。这里没有延迟,没有流水线级,也没有需要处理的冒险。result被声明为reg纯粹是为了满足always @(*)块中 Verilog 的过程赋值语法——并不会推断出任何实际的状态元件。 来源: alu.v操作编码与 RV32I 映射
ALU 使用自定义的 4 位编码方案来选择其支持的十种操作。该编码本身不属于 RISC-V 规范的一部分;它是 ALU 与控制单元之间共享的内部约定。编码遵循逻辑分组模式:算术操作占据低位代码 (0x0–0x1),按位逻辑操作占据中间范围 (0x2–0x4),移词紧随其后 (0x5–0x7),比较操作位于顶部 (0x8–0x9)。
alu_op| 助记符| 类别| 操作| RV32I 指令 —|—|—|—|—4'b0000| ALU_ADD| Arithmetic|a + b| ADD, ADDI, LUI, AUIPC, Load, Store4'b0001| ALU_SUB| Arithmetic|a - b| SUB4'b0010| ALU_AND| Logical|a & b| AND, ANDI4'b0011| ALU_OR| Logical|a | b| OR, ORI4'b0100| ALU_XOR| Logical|a ^ b| XOR, XORI4'b0101| ALU_SLL| Shift|a << b[4:0]| SLL, SLLI4'b0110| ALU_SRL| Shift|a >> b[4:0]| SRL, SRLI4'b0111| ALU_SRA| Shift|a >>> b[4:0]| SRA, SRAI4'b1000| ALU_SLT| Compare|(signed a < signed b) ? 1 : 0| SLT, SLTI4'b1001| ALU_SLTU| Compare|(a < b) ? 1 : 0| SLTU, SLTIU 从指令字段到alu_op的映射是在控制单元中通过解码funct3和funct7[5]来完成的。对于 R 型指令,仅funct3就可以区分大多数操作,而funct7[5]用于消除共享编码的歧义:funct3=000解析为 ADD 还是 SUB,funct3=101解析为 SRL 还是 SRA。对于 I 型立即数指令,应用相同的基于funct3的查找逻辑,但绝不会生成 SUB(RV32I 中不存在与立即数相减的操作),并且移词歧义情况 (funct3=101) 使用funct7[5]来区分 SRLI 和 SRAI。 来源: alu.v, control.v, control.v组合逻辑实现
核心计算被实现为单个
always @(*)块,其中包含一个case语句,将每个alu_op值映射到其对应的 Verilog 表达式。这是教学处理器中 ALU 实现最简单且最常见的模式,它直接映射为硬件中的多路复用器树:综合工具构建一个选择器,通过由alu_op控制的 10 选 1 多路复用器,路由所有十个并行计算路径的输出。 VERILOG Copy code always @(*) begin case (alu_op) ALU_ADD: result = operand_a + operand_b; ALU_SUB: result = operand_a - operand_b; ALU_AND: result = operand_a & operand_b; ALU_OR: result = operand_a | operand_b; ALU_XOR: result = operand_a ^ operand_b; ALU_SLL: result = operand_a « operand_b[4:0]; ALU_SRL: result = operand_a » operand_b[4:0]; ALU_SRA: result = $signed(operand_a) »> operand_b[4:0]; ALU_SLT: result = ($signed(operand_a) < $signed(operand_b)) ? 32’b1 : 32’b0; ALU_SLTU: result = (operand_a < operand_b) ? 32’b1 : 32’b0; default: result = 32’b0; endcase end 有几个实现细节值得关注。移词操作 仅提取operand_b的低 5 位 (operand_b[4:0]) 作为移位量——这是 RV32I 规范强制要求的,该规范要求超过 31 的移位量在左移时产生零结果,在算术右移时产生符号扩展的结果。5 位提取本质上将移位范围限制在 0–31,这对于 32 位架构来说是正确的行为。算术右移 (ALU_SRA) 使用$signed()类型转换结合>>>运算符,确保在移位期间复制最高有效位(符号位),而不是用零填充。有符号比较 (ALU_SLT) 在<比较之前也对两个操作数使用了$signed()类型转换,正确处理了二进制补码语义,例如0xFFFFFFFF表示 -1 且小于0x00000001。默认情况 (default case) 返回零,为任何未定义的alu_op值提供了安全的后备方案。 来源: alu.v零标志
zero标志源自与 32’b0 的简单相等比较: VERILOG Copy code assign zero = (result == 32’b0); 只要 ALU 结果恰好为零,这个 1 位输出就会置位。在许多处理器设计中,零标志直接馈入分支评估逻辑。然而在 TinyRISCV 中,分支决策完全由独立的 分支单元 处理,它对寄存器堆的操作数执行自己的比较。zero信号在顶层核心中进行了连线,但在当前设计中并未被任何下游模块消费。它的存在具有架构上的前瞻性——它为未来的条件指令或通过波形查看器进行调试提供了所需的信号——而且除了一个 32 输入的 NOR 门之外,它不增加任何硬件成本。 来源: alu.v, riscv_core.v操作数选择:数据如何到达 ALU
ALU 本身并不关心其操作数来自何处——它只是对其输入端口上出现的任何内容进行计算。真正的路由逻辑位于顶层模块 中,在那里,两个多路复用器赋值决定了 ALU 接收什么值。 Syntax error in textmermaid version 11.6.0 操作数 A 根据 opcode 在
rs1_data和pc之间进行选择:当指令为 AUIPC (opcode == 7'b0010111) 时,当前程序计数器的值被路由到operand_a,以便 ALU 可以计算PC + upper_immediate。对于所有其他指令,operand_a接收从寄存器rs1读取的值。这种路由在核心模块中被实现为一个简单的三元赋值。 操作数 B 根据alu_src控制信号在rs2_data和imm之间进行选择。当alu_src置位时(针对 I 型、Load、Store、LUI、AUIPC 和 JALR 指令),来自立即数生成器 的经符号扩展或零扩展的立即数值被转发到 ALU。当alu_src未置位时(针对 R 型指令),则使用从寄存器rs2读取的值。 指令类型|operand_a|operand_b|alu_op| ALU 目的 —|—|—|—|— R-type| rs1_data| rs2_data| funct3/funct7| 算术/逻辑计算 I-type ALU| rs1_data| imm| funct3/funct7| 立即数算术/逻辑 LUI| rs1_data (x0=0)| imm (upper)| ADD| 加载上部立即数 (0 + upper) AUIPC| pc| imm (upper)| ADD| PC + 上部立即数 Load| rs1_data| imm| ADD| 基址 + 偏移地址计算 Store| rs1_data| imm| ADD| 基址 + 偏移地址计算 JALR| rs1_data| imm| ADD| 通过 rs1 + 偏移量的跳转目标 请注意,LUI 巧妙地复用了 ALU 的 ADD 操作:由于operand_a来自rs1_data,并且 LUI 指令格式将目标寄存器放在rd中,而rs1隐式读取的是x0(在寄存器堆 中硬连线为零),因此计算0 + upper_immediate自然会产生所需的结果。类似地,AUIPC 使用 PC 作为operand_a来计算PC + upper_immediate。 来源: riscv_core.v, control.v单周期数据通路上下文中的 ALU
理解 ALU 的角色需要将其视为更广泛的单周期数据通路中的一个节点。在 TinyRISCV 的架构中,每条指令在一个时钟周期内流经所有五个阶段——取指、译码、执行、访存、写回。ALU 位于执行阶段,消费在同一周期内组合产生的已译码控制信号和寄存器值。 Syntax error in textmermaid version 11.6.0 ALU 结果馈入两条下游路径。主路径 将
alu_result路由到数据存储器地址端口(用于 Load 和 Store 指令)以及写回多路复用器(用于 R 型和 I 型 ALU 指令)。写回多路复用器 根据mem_to_reg和jump控制信号,在alu_result、mem_read_data和pc_plus_4之间进行选择,决定将哪个值写回目标寄存器。ALU 的组合逻辑传播延迟通常是单周期处理器中的关键路径,因为其输出必须在数据存储器被访问之前、且在写回值被寄存之前稳定下来——所有这些都必须在一个时钟周期内完成。 在波形中调试 ALU 行为时,请首先追踪alu_op信号。错误的操作码几乎总是导致意外 ALU 结果的根本原因——ALU 本身太简单了,以至于很难发生故障。请验证控制单元的funct3/funct7解码是否为当前指令产生了预期的alu_op。 来源: riscv_core.v设计观察与权衡
ALU 的设计反映了几个值得理解的审慎权衡,特别是对于可能扩展或修改处理器的开发者而言。 操作码重复。 从
ALU_ADD到ALU_SLTU的 localparam 定义在 alu.v 和 control.v 中完全相同地出现了。这种重复避免了跨文件依赖,但引入了维护风险:如果在一个文件中更改了操作码而在另一个文件中没有更改,处理器将静默地发生故障。一种更健壮的方法是将这些定义集中在一个共享的包含文件(例如defines.vh)中,但 TinyRISCV 为了教学清晰度而优先考虑了文件级别的独立性。 ALU 外部的分支评估。 分支比较操作 (BEQ, BNE, BLT, BGE, BLTU, BGEU) 由分支单元 处理,而不是由 ALU 处理。这是一个审慎的架构选择:分支单元比较的是 原始寄存器值 (rs1_data,rs2_data),而 ALU 操作的是 可能不同的操作数 (例如 AUIPC 的pc,或 I 型的imm)。将分支评估合并到 ALU 中将需要额外的操作数路由复杂性,并且会将两个功能不同的任务耦合在一起。这种分离保持了两个模块的简洁及其接口的清晰。 无乘法或除法。 RV32I 基础整数规范不要求乘法或除法——它们属于 M 扩展。TinyRISCV 仅实现了基础 ISA,因此 ALU 没有 MUL 或 DIV 操作。programs/asm/factorial.s中的阶乘测试程序演示了软件如何通过重复加法来实现乘法,这正是一个极简 ISA 所期望的那种权衡。 默认情况的安全性。 ALU 的 case 语句中的default: result = 32'b0;子句确保未定义的alu_op值产生确定性、良性的输出,而不是锁存陈旧数据或创建无关项 (don’t-care) 传播。这是一个关键的安全网:在开发期间,当新的指令类型被添加到控制单元时,路由错误的alu_op将产生零结果——这是错误的,但至少是确定的且在仿真中可观察的。 设计选择| 收益| 代价 —|—|— 纯组合逻辑 (无流水线)| 零延迟,时序简单| 较长的关键路径 独立的分支单元| 关注点清晰分离| 少量的面积开销 4 位内部操作码| 16 种可能的操作,留有扩展空间| 重复的定义 SRA/SLT 使用$signed()类型转换| 正确的二进制补码语义| 综合工具必须推断有符号算术 提取 5 位移位量| 符合 RV32I 规范| 大于 31 的移位被静默忽略 在使用新 ALU 操作(例如用于 M 扩展)扩展 TinyRISCV 时,请将新的alu_oplocalparam 同时添加到alu.v和control.v中,然后在连接控制逻辑之前在 ALU 中添加 case 分支。这种双文件更新模式是最常见的集成 Bug 来源。 来源: alu.v, control.v, branch_unit.v, factorial.s实践示例:汇编中的 ALU 操作
TinyRISCV 附带的测试程序提供了 ALU 如何被调用的具体说明。
hello.s程序是最直接的演示,因为它在没有循环或内存复杂性的情况下使用 ALU 进行纯计算。 ASM Copy code li x1, 10 # ADDI: ALU_ADD(0, 10) → x1 = 10 li x2, 20 # ADDI: ALU_ADD(0, 20) → x2 = 20 add x3, x1, x2 # ADD: ALU_ADD(10, 20) → x3 = 30 addi x4, x3, 5 # ADDI: ALU_ADD(30, 5) → x4 = 35 sub x5, x4, x1 # SUB: ALU_SUB(35, 10) → x5 = 25 lui x6, 0x12345 # LUI: ALU_ADD(0, 0x12345000) → x6 = 0x12345000 每一行都映射到特定的 ALU 操作和操作数路由配置。li伪指令扩展为ADDI rd, x0, imm,它将立即数路由到operand_b(通过alu_src=1),将x0硬连线的零路由到operand_a,通过与零相加产生立即数值。add和sub指令在两个端口上都使用寄存器操作数 (alu_src=0)。lui指令利用了相同的零加立即数模式,但使用的是左移 12 位的 20 位上部立即数。 汇编| ALU 操作|operand_a|operand_b| 结果 —|—|—|—|—li x1, 10| ADD| 0 (x0)| 10| 10add x3, x1, x2| ADD| 10 (x1)| 20 (x2)| 30addi x4, x3, 5| ADD| 30 (x3)| 5| 35sub x5, x4, x1| SUB| 35 (x4)| 10 (x1)| 25lui x6, 0x12345| ADD| 0 (x0)| 0x12345000| 0x12345000fibonacci.s程序在循环上下文中演练 ALU,重复使用 ADD 进行斐波那契累加 (add x4, x1, x2) 和循环计数器递减 (addi x3, x3, -1)。factorial.s程序更进一步,通过重复加法实现乘法——这生动地演示了软件如何弥补 ALU 缺乏硬件乘法器的不足。 来源: hello.s, fibonacci.s, factorial.s后续步骤
ALU 是 TinyRISCV 中三个数据通路组件之一。要理解完整的执行流水线,请继续了解其他数据通路模块:
- 分享
算术逻辑单元 (ALU) 是 TinyRISCV 的计算核心——一个纯组合逻辑模块,在 4 位操作码的指引下,将两个 32 位操作数转换为计算结果。它被刻意设计得极其精简:十种操作,零状态,一个辅助标志。这种精简并非局限,而是设计理念的体现。通过将 ALU 严格限制为仅满足 RV32I 基础整数指令集的需求,TinyRISCV 实现了一条极其易于审查、自然可综合且足以支持单周期执行的数据通路。ALU 不评估分支条件——该职责属于专用的分支单元 ——它也不管理操作数的路由——那是由控制单元 和顶层模块 来协调的。它所做的,且擅长做的,就是计算。
来源: alu.v
- 寄存器堆 — 操作数如何获取以及结果如何存储
- 分支单元 — 为什么分支评估位于 ALU 之外
- 控制单元 — 如何从指令字段生成
alu_op和alu_src - 顶层模块集成 — 操作数多路复用和结果路由是如何连接在一起的 划线 写想法 提问
-
在Github README中添加Zread徽章添加徽章
来源
ALU 设计
-
rtl
-
datapath
- alu.v
- branch_unit.v
-
core
- control.v
- riscv_core.v
-
-
programs/asm
- factorial.s
- hello.s
-
fibonacci.s
寄存器堆
⌘K
-
- 分享
寄存器堆是处理器访问最频繁的存储元件——一个由 32 × 32 位寄存器组成的紧凑阵列,作为内核执行每条指令的主要工作区。在 TinyRISCV 的单周期微架构中,它每个时钟周期执行两次组合逻辑读和一次时序逻辑写,这使其成为译码级与执行级之间的结构枢纽。理解其设计可以揭示 RISC-V ISA 规范中“x0 恒为零”的约定是如何在硬件上强制执行的,为什么在单周期机器中先读后写的行为至关重要,以及寄存器堆在处理器关键时序路径上处于什么位置。
来源: regfile.v, riscv_core.v
模块接口与端口语义
寄存器堆提供了一个简洁的三端口接口——两个专用读端口和一个写端口——这是单发射 RISC 处理器的典型拓扑结构。每个端口的地址宽度为 5 位(寻址 2⁵ = 32 个寄存器),数据通路为完整的 RV32I 32 位宽度。 端口| 方向| 宽度| 连接至| 用途 —|—|—|—|—
clk| input| 1| 全局时钟| 写边沿同步rst_n| input| 1| 全局复位| 异步低电平有效复位read_addr1| input| 5| 来自译码器的rs1| 第一源寄存器索引read_addr2| input| 5| 来自译码器的rs2| 第二源寄存器索引write_addr| input| 5| 来自译码器的rd| 目标寄存器索引write_data| input| 32| 写回多路选择器| 要写入的数据write_enable| input| 1| 来自控制单元的reg_write| 写操作门控read_data1| output| 32| ALU 操作数 A,分支单元|registers[rs1]的值read_data2| output| 32| ALU 操作数 B (当alu_src=0时),DMEM 写数据|registers[rs2]的值 这两个读端口馈入不同的消费路径:read_data1驱动 ALU 的operand_a(以及可选的pc,通过内核中的多路选择器用于 AUIPC)和分支单元的operand_a,而read_data2驱动 ALU 的operand_b选择多路选择器和数据存储器的write_data输入。这种双读设计至关重要,因为像add x4, x1, x2这样的 R 型指令需要在同一周期内同时获取两个源操作数。 来源: regfile.v, riscv_core.v内部架构
寄存器堆的内部结构紧凑,却体现了几个深思熟虑的设计决策。一个
reg [31:0] registers [0:31]数组提供了 32 个 32 位寄存器,总共 1024 位的状态。该设计将组合读逻辑 与时序写逻辑 清晰地分离开来,这对时序和正确性具有重要意义。 Outputs 时序写 (posedge clk) 组合读 Inputs 在时钟边沿 寄存器阵列 — 32 × 32-bit x0 (硬连线为 0) x1 x2 … x31 read_addr1 (rs1, 5-bit) read_addr2 (rs2, 5-bit) write_addr (rd, 5-bit) write_data (32-bit) write_enable (reg_write) addr1 == 0 ? 0 : registers[addr1] addr2 == 0 ? 0 : registers[addr2] write_enable && write_addr != 0 read_data1 (32-bit) read_data2 (32-bit)组合读——零延迟访问
两个读操作都是通过包含内联 x0 保护逻辑的连续
assign语句实现的: VERILOG Copy code assign read_data1 = (read_addr1 == 5’b0) ? 32’b0 : registers[read_addr1]; assign read_data2 = (read_addr2 == 5’b0) ? 32’b0 : registers[read_addr2]; 这意味着读操作是组合逻辑 完成的——不需要时钟边沿。当地址线稳定后(在译码器从指令中提取出rs1/rs2之后),输出数据经过一个多路选择器的传播延迟即可生效。该三元运算符实现了 RISC-V 的规定:无论是否存在任何错误的写入尝试,寄存器 x0 的读取值始终为零。在综合时,这变成了每个读端口的一个 32:1 多路选择器,当地址为5'b0时选择恒零路径。时序写——边沿触发提交
写入操作在
always块中受双条件保护门的时钟门控: VERILOG Copy code always @(posedge clk or negedge rst_n) begin if (!rst_n) begin for (i = 0; i < 32; i = i + 1) registers[i] <= 32’b0; end else if (write_enable && write_addr != 5’b0) begin registers[write_addr] <= write_data; end end 双重条件write_enable && write_addr != 5'b0从两个独立的角度为 x0 提供了写保护 :控制单元的reg_write信号门控了 是否发生任何 写入(Store 和 Branch 指令会使其保持无效),而write_addr != 5'b0检查确保即使reg_write为高且rd碰巧是x0(如add x0, x1, x2,这在 RISC-V 中是合法的 NOP),写入也会被静默丢弃。这种纵深防御策略在硬件层面保证了 x0 恒为零的不变性。 来源: regfile.vx0 寄存器——软件约定的硬件强制执行
RISC-V 规定寄存器 x0 硬连线为零——读取它始终得到 0,写入它没有任何效果。TinyRISCV 通过两个独立的机制 来强制执行这一点,而不是仅靠一个: 机制| 位置| 保护内容 —|—|— 读侧多路选择器|
assign语句 (第 26–27 行)| x0 始终 读取 为零 写侧保护|write_addr != 5'b0(第 21 行)| x0 永远不会被 写入 为什么需要两者兼备?考虑一条像add x0, x1, x2的指令。译码器提取出rd = 5'b0,控制单元则断言reg_write = 1。如果没有写侧保护,寄存器堆会试图将 ALU 的结果写入registers[0]。虽然读侧多路选择器在随后的读取中仍会返回零,但底层存储已经被破坏——这对于调试可见性是个问题(波形检查中registers[0]会显示非零值),并且如果后续设计修改绕过了多路选择器,这也会成为一种隐患。双重执行策略彻底消除了这类 bug。 在调试期间检查波形时,你可以通过检查registers[0]是否永远不偏离其复位值32'b0来验证 x0 不变性。如果发生了偏离,则说明存在写路径旁路——这是一个需要尽早发现的关键 bug。 来源: regfile.v单周期模型中的先读后写行为
在 TinyRISCV 的单周期微架构中,寄存器堆在同一时钟周期内表现出明确定义的先读后写 行为。由于读操作是组合逻辑,写操作是边沿触发的,当一条指令读取并写入同一个寄存器(例如
add x1, x1, x2)时,读端口在当前周期返回 x1 的 旧 值,而新值仅在下一个时钟上升沿提交。 这不是 bug——这正是正确的 RISC-V 执行模型。考虑指令add x1, x1, x2:处理器必须使用 x1 的当前值作为 ALU 的输入,计算总和,然后将结果写回 x1。其时序自然而然地达成: Write-Back MuxALURegister FileDecoderClockWrite-Back MuxALURegister FileDecoderClock上升沿 — 新周期开始下一个上升沿 — 写入提交rs1=x1, rs2=x2, rd=x1read_data1 = 旧 x1 值 (组合逻辑)read_data2 = x2 值 (组合逻辑)alu_result = 旧 x1 + x2write_data = 旧 x1 + x2x1 ← 旧 x1 + x2 (时序逻辑) 在流水线设计中,同一条指令会产生数据冒险(写后读),需要转发逻辑来解决。但在单周期模型中,整条指令在一个周期内完成,因此读取旧值始终是架构上正确的选择。这是单周期方法最大的简化之一。 来源: regfile.v, riscv_core.v在处理器数据通路中的集成
寄存器堆位于数据通路的核心,接收来自指令译码器 和控制单元 的已译码指令字段,并将其输出馈送到 ALU 、分支单元 和数据存储器 。在顶层
riscv_core模块中,其实例化直接映射到处理器的架构意图: 寄存器堆端口| 核心信号| 来源 —|—|—read_addr1|rs1| 译码器提取instr[19:15]read_addr2|rs2| 译码器提取instr[24:20]write_addr|rd| 译码器提取instr[11:7]write_enable|reg_write| 控制单元基于操作码生成write_data|write_back_data| 多路选择器:ALU 结果 / DMEM 读取 / PC+4read_data1|rs1_data| 馈给 ALUoperand_a和分支单元read_data2|rs2_data| 馈给 ALU 操作数 B 多路选择器和 DMEM 写操作 写回数据通路特别值得注意。write_back_data信号由内核中的三路选择器选出: VERILOG Copy code assign write_back_data = jump ? pc_plus_4 : (mem_to_reg ? mem_read_data : alu_result); 这意味着寄存器堆可以根据指令类型从三个不同的来源接收数据:计算指令(R 型,I 型 ALU,LUI,AUIPC)对应的 ALU 结果 ,加载指令(当mem_to_reg = 1时)对应的数据存储器读出输出 ,或者跳转链接指令 JAL/JALR(当jump = 1时,用于存储返回地址)对应的 PC+4 。来自控制单元 的reg_write信号充当主门控——当它为低电平时(针对 Store、Branch 和 SYSTEM 指令),无论write_data上的数据是什么,都不会发生写入。 来源: riscv_core.v哪些指令会写入寄存器堆
并非每条指令都会访问寄存器堆的写端口。控制单元的
reg_write信号充当守门人,其值完全取决于指令的操作码。以下是完整的分类: 指令类型|reg_write| 写入目标| 写入数据源 —|—|—|— R 型 (ADD, SUB 等)| 1|rd| ALU 结果 I 型 ALU (ADDI, XORI 等)| 1|rd| ALU 结果 LUI| 1|rd| ALU 结果 (imm + 0) AUIPC| 1|rd| ALU 结果 (pc + imm) Load (LB, LH, LW 等)| 1|rd| 数据存储器读取 JAL| 1|rd| PC + 4 JALR| 1|rd| PC + 4 Store (SB, SH, SW)| 0| —| 无写入 Branch (BEQ, BNE 等)| 0| —| 无写入 SYSTEM (ECALL)| 0| —| 无写入 注意,Store 指令会从寄存器堆读取(它们需要rs2作为存储数据,rs1作为基址),但从不写回。类似地,Branch 指令读取两个寄存器进行比较,但不产生需要提交的结果。这种读写之间的不对称性——每条指令都会读取,但只有一部分指令会写入——是 RISC 的基本特征,寄存器堆的双读单写拓扑结构正反映了这一点。 来源: control.v, riscv_core.v复位行为与初始化
寄存器堆采用异步低电平有效复位 (
negedge rst_n),在rst_n的下降沿将所有 32 个寄存器清零,不受时钟影响。复位解除后,所有寄存器都从0x00000000开始,这意味着 x0 的零值在初始化时自然与其余寄存器阵列保持一致。 复位循环使用integer i变量遍历所有 32 个寄存器: VERILOG Copy code if (!rst_n) begin for (i = 0; i < 32; i = i + 1) registers[i] <= 32’b0; end 这是初始化寄存器阵列的常见 Verilog 惯用法。在仿真中,所有 32 个非阻塞赋值在复位事件时被并发求值,确保确定性的初始化。在综合中,工具会推断出一个同步复位分配网络。请注意,integer i是在模块作用域(第 15 行)声明的,而不是在always块内部,这是可综合代码中for循环迭代变量的 Verilog-2001 风格要求。 复位后,所有寄存器都为零——不仅仅是 x0。这意味着任何程序的前几条指令必须在使用寄存器之前显式地向其加载值。汇编测试程序通常以li(加载立即数)伪指令开始,正如 Fibonacci 程序的li x1, 0; li x2, 1; li x3, 10序列所示,该序列从一个干净的寄存器堆建立了循环的初始状态。 来源: regfile.v, fibonacci.s在关键路径上的位置
在 TinyRISCV 的单周期设计中,关键路径——决定最大时钟频率的最长组合逻辑链——流经寄存器堆: Copy code PC → IMEM → 译码器 → 寄存器堆 → ALU → DMEM → 写回多路选择器 → 寄存器堆 (写数据) 寄存器堆在此链路中出现两次:一次是读延迟 (地址译码 + 多路选择器传播以产生
read_data1/read_data2),另一次隐含为写数据建立时间 (计算出的结果必须在下一个时钟边沿之前稳定)。寄存器堆的读延迟直接延迟了 ALU 输入的可用性,使其成为整体周期时间的关键决定因素。 在流水线重新设计中,寄存器堆将被分割在 ID/EX 流水线边界上,并增加转发路径以解决数据冒险——但对于这种教学性质的单周期设计,组合读加上单时钟边沿写的简单性是最优权衡。 来源: architecture_zh.md寄存器堆实践——跟踪示例
为了将抽象设计落实为具体行为,考虑寄存器堆在复位后如何处理 Fibonacci 程序的前几条指令: 周期| PC| 指令| rs1| rs2| rd|
reg_write| 读数据| 写数据| 效果 —|—|—|—|—|—|—|—|—|— 1| 0x00|li x1, 0(ADDI)| x1| —| x1| 1| 0x00000000| 0x00000000| x1 ← 0 2| 0x04|li x2, 1(ADDI)| x0| —| x2| 1| 0x00000000| 0x00000001| x2 ← 1 3| 0x08|li x3, 10(ADDI)| x0| —| x3| 1| 0x00000000| 0x0000000A| x3 ← 10 4| 0x0C|beq x3, x0, done| x3| x0| —| 0| 0x0000000A / 0x0| —| 无写入;分支未发生 5| 0x10|add x4, x1, x2| x1| x2| x4| 1| 0x0 / 0x1| 0x00000001| x4 ← 1 在第 5 周期,双读能力得到了充分利用:read_data1(x1 = 0) 和read_data2(x2 = 1) 在同一周期内被 ALU 消耗以计算总和,然后将其写回 x4。read_data2端口还并行馈给分支单元——在第 4 周期期间,分支单元使用与 ALU 在计算指令中所用相同的寄存器堆输出,将 x3 与 x0 进行比较。 来源: fibonacci.s, riscv_core.v设计权衡与替代方案
寄存器堆当前的实现反映了适用于教学单周期处理器的几个深思熟虑的权衡: 决策| 当前选择| 替代方案| 权衡 —|—|—|— 读时序| 组合逻辑| 寄存输出(流水线)| 更简单的时序 vs. 更高的时钟频率 端口数量| 2R + 1W| 3R + 2W (超标量)| 足以单发射 vs. 支持多发射 x0 存储| 物理寄存器 + 多路选择器保护| 无存储,恒零输出| 更简单的 Verilog vs. 略少的存储逻辑 复位| 全阵列清零| 选择性清零 (仅非 x0)| 确定性启动 vs. 最小化复位逻辑 写冲突| 无旁路/转发| 写优先(旁路至读)| 单周期不需要 vs. 流水线需要 对未来演进影响最大的权衡是缺少写转发 (也称为“旁路”或“写优先”语义)。在当前设计中,如果在同一周期内读取和写入同一寄存器,读取将返回 旧 值——这对于单周期执行是正确的,但与写入发生在后续阶段的流水线设计不兼容。流水线将需要从写回阶段到译码阶段的转发路径,或者需要一个在同周期内读写地址匹配时返回新值的写优先寄存器堆。 来源: regfile.v, architecture_zh.md
后续步骤
寄存器堆的读输出直接流入以截然不同的方式消耗它们的两个执行单元。ALU 设计 页面详细介绍了
read_data1和read_data2如何成为计算指令的 ALU 操作数,而分支单元 页面解释了如何比较相同的寄存器值以决定分支结果。有关寄存器堆如何融入完整数据通路的更广阔视角,请参阅架构概述 。 划线 写想法 提问
- 分享
寄存器堆是处理器访问最频繁的存储元件——一个由 32 × 32 位寄存器组成的紧凑阵列,作为内核执行每条指令的主要工作区。在 TinyRISCV 的单周期微架构中,它每个时钟周期执行两次组合逻辑读和一次时序逻辑写,这使其成为译码级与执行级之间的结构枢纽。理解其设计可以揭示 RISC-V ISA 规范中“x0 恒为零”的约定是如何在硬件上强制执行的,为什么在单周期机器中先读后写的行为至关重要,以及寄存器堆在处理器关键时序路径上处于什么位置。
来源: regfile.v, riscv_core.v
-
在Github README中添加Zread徽章添加徽章
来源
寄存器堆
-
rtl
-
datapath
- regfile.v
-
core
- riscv_core.v
- control.v
-
-
programs/asm
- fibonacci.s
-
docs
-
architecture_zh.md
分支单元
⌘K
-
-
- 分享
分支单元 是一个专用的组合逻辑评估模块,用于决定条件分支指令是否应重定向程序流。在 TinyRISCV 的数据通路中,它作为与 ALU 并行的决策引擎——当 ALU 计算算术结果时,分支单元同时解析分支条件,产生一个单比特的
branch_taken信号,直接输入到下一 PC 选择逻辑中。这种架构上的分离确保了分支解析永远不会与 ALU 的计算路径发生竞争,从而保持了关键路径的短捷和设计的模块化。模块接口
分支单元提供了一个极简的三输入、单输出接口,这反映了其单一职责——根据
funct3编码的条件对两个寄存器操作数进行评估,并输出一个布尔判定结果: 端口| 方向| 位宽| 描述 —|—|—|—funct3| input| 3 bits| 来源于指令位 [14:12] 的分支条件选择器operand_a| input| 32 bits| rs1 的值(第一个源寄存器)operand_b| input| 32 bits| rs2 的值(第二个源寄存器)branch_taken| output| 1 bit| 当分支条件满足时置高电平有效 该接口被刻意设计得很精简:模块仅接收原始寄存器值和funct3条件码。它不需要了解程序计数器、分支偏移量或控制单元的branch信号。这种解耦意味着分支单元可以在完全隔离的环境下进行验证,并且无需修改即可在任何单发射 RISC-V 核心中复用。 来源: branch_unit.v支持的分支条件
RV32I 基础整数指令集定义了六种条件分支条件,所有这些条件都在一个由
funct3驱动的单一组合case语句中实现。两个未使用的编码(3'b010和3'b011)在规范中是保留的,它们映射到default子句,安全地将branch_taken信号置低。funct3| 助记符| 比较| 符号性 —|—|—|—3'b000| BEQ|operand_a == operand_b| —3'b001| BNE|operand_a != operand_b| —3'b100| BLT|$signed(operand_a) < $signed(operand_b)| 有符号3'b101| BGE|$signed(operand_a) >= $signed(operand_b)| 有符号3'b110| BLTU|operand_a < operand_b| 无符号3'b111| BGEU|operand_a >= operand_b| 无符号 一个关键的实现细节是在 BLT 和 BGE 中使用了 Verilog 的$signed()系统函数。如果没有这种类型转换,Verilog 默认会将 32 位的线网值视为无符号数,导致负的二进制补码整数被当作大的正数进行比较——这是 RISC-V 实现中典型且微妙的 Bug 来源。无符号变体 BLTU 和 BGEU 则刻意省略了该转换,从而应用自然无符号的线网比较语义。 来源: branch_unit.v数据通路集成
要理解分支单元的作用,需要了解它如何与核心的其他部分连接。下图展示了完整的分支解析数据流——从指令获取到条件评估,再到下一 PC 选择: funct3 opcode rs1, rs2 rs1_data rs2_data branch, jump, pc_src branch_taken imm pc pc_next Instruction\nMemory Decoder Branch Unit Control Unit Register File PC Adder Imm Gen PC Register 在 riscv_core.v 中,分支单元被实例化为
branch_eval,并直接连接到寄存器堆的读端口。值得注意的是,输入到分支单元的操作数(rs1_data和rs2_data)是原始寄存器值 ,而不是 ALU 多路选择的alu_operand_b路径。这意味着分支单元始终完全按照程序员的意图比较两个源寄存器——它不受 ALU 路径中替代rs2_data的alu_src多路选择器的影响。branch_taken输出随后路由到 PC 加法器 模块,在那里与控制单元的jump和pc_src信号组合,计算出pc_next。 来源: riscv_core.v, riscv_core.vPC 加法器中的分支解析逻辑
仅靠
branch_taken信号本身不会导致 PC 重定向——它必须被控制单元的pc_src信号限定 。PC 加法器模块按如下方式实现这种门控:pc_src| 来源| 重定向条件| 下一 PC —|—|—|—2'b00| PC+4| 总是(无分支)|pc + 42'b01| Branch/JAL|branch_taken || jump| 跳转时为pc + imm;否则为pc + 42'b10| JALR| 总是(无条件)|(rs1_data + imm) & ~1关键逻辑存在于 PC 加法器的PC_BRANCH情况中:if (branch_taken || jump)——来自控制单元 的jump信号充当 JAL 指令的无条件覆盖,JAL 指令与条件分支共享相同的pc_src编码,但应总是重定向。对于条件分支(BEQ/BNE/BLT/BGE/BLTU/BGEU),jump被置低,决策完全取决于branch_taken。branch_taken信号是纯组合逻辑输出——它没有经过时钟门控或锁存。这意味着它在一个传播延迟内稳定,并可用于同周期的 PC 计算,但这同时也意味着寄存器堆读端口上的任何毛刺都可能会瞬间影响pc_next。在这种单周期设计中这是无害的,但流水线扩展则需要对此信号进行寄存或流水线化。 来源: pc_adder.v, control.v控制单元调度
当解码器识别出分支操作码(
7'b1100011)时,控制单元 驱动两个信号来激活分支路径:branch = 1和pc_src = PC_BRANCH(2’b01)。branch信号本身不被分支单元消费——它是一个控制标志,指示当前指令是分支类型。实际的条件评估由分支单元使用funct3和寄存器操作数独立完成。这种清晰的分离意味着控制单元不需要理解各个分支条件的语义;它仅启用分支路径,并让分支单元决定是否应重定向 PC。 对于 JAL(7'b1101111),控制单元设置jump = 1和pc_src = PC_BRANCH,使 PC 加法器无条件重定向到pc + imm(jump标志覆盖了branch_taken)。对于 JALR(7'b1100111),它设置jump = 1和pc_src = PC_JALR,路由到寄存器间接路径(rs1_data + imm) & ~1。 来源: control.v对比:分支单元与基于 ALU 的分支解析
在极简 RISC-V 实现中,一种常见的替代方案是不 设置独立的分支单元,而是复用 ALU 的减法和零标志来判断分支结果。TinyRISCV 采用独立的分支单元代表了一种刻意的架构选择。下表对比了这两种方法: 方面| 专用分支单元| 仅 ALU 解析 —|—|— 条件覆盖| 原生支持所有 6 种分支类型| BEQ/BNE 通过零标志实现;有符号/无符号的 SLT/SLTU 需要额外的 ALU 周期或多路选择 ALU 可用性| ALU 在同一周期内可用于其他计算| ALU 被分支评估占用 时序| 与 ALU 并行——无竞争| ALU 必须在分支决策前完成计算 硬件开销| 6 个比较器 + 多路选择器| 复用现有的 ALU 逻辑 设计清晰度| 分支逻辑自包含且可独立测试| 分支逻辑与算术逻辑交织在一起 在像 TinyRISCV 这样的单周期核心中,并行评估策略是自然的选择——分支单元和 ALU 同时对同一指令的不同方面进行操作,关注点的清晰分离以及能够在与 ALU 完全隔离的情况下验证分支逻辑的能力,证明了这种小面积开销的合理性。 来源: branch_unit.v, alu.v
分支指令实践
随附的汇编测试程序展示了真实的分支使用模式。在 factorial.s 中,主循环顶部的
beq x1, x0, done检查计数器寄存器是否已达到零——如果是,分支单元将branch_taken置高,PC 加法器重定向到done标签,跳过后续迭代。类似地,内部乘法循环中的beq x4, x0, multiply_done使用相同的 BEQ 模式,在乘法计数器递减至零时退出。fibonacci.s 程序遵循相同的模式,使用beq x3, x0, done在十次迭代后终止。 这些程序独占地使用 BEQ,它映射到funct3 = 3'b000——这是最简单的分支条件,其中branch_taken = (operand_a == operand_b)。更全面的测试套件应演练 BNE(非零循环)、BLT/BGE(有符号数据的范围检查)以及 BLTU/BGEU(无符号地址比较),以验证由$signed()保护的有符号比较路径。 来源: factorial.s, fibonacci.s设计总结
分支单元体现了一种专注的设计哲学:单一职责,零状态,完全覆盖 。它是一个纯组合逻辑模块,没有寄存器,没有时钟,也没有复位——其输出是输入的即时函数。六种 RV32I 分支条件由一个直截了当的
case语句解析,并通过$signed()进行明确的有符号处理。其输出branch_taken由 PC 加法器与控制单元的jump信号共同限定,形成一条完整的分支解析链,干净利落地将“什么条件”的问题(分支单元)与“是否重定向”的问题(PC 加法器 + 控制单元)分离开来。 当将 TinyRISCV 扩展为流水线架构时,分支单元的组合逻辑输出将成为关键路径的考量因素。一种常见策略是在branch_taken上插入流水线寄存器,并在执行阶段解析分支,接受预测错误时的一个周期惩罚。现有的简洁接口——三个输入,一个输出——使得这种插入非常直接,无需重构分支单元本身。 有关分支解析如何与 PC 管理交互的完整图景,请参见 PC 加法器与下一 PC 选择 。有关启用分支路径的控制信号,请参阅控制单元 和控制信号参考 。有关如何从指令中提取分支偏移立即数的详细信息,请参见立即数生成器 。 划线 写想法 提问
- 分享
分支单元 是一个专用的组合逻辑评估模块,用于决定条件分支指令是否应重定向程序流。在 TinyRISCV 的数据通路中,它作为与 ALU 并行的决策引擎——当 ALU 计算算术结果时,分支单元同时解析分支条件,产生一个单比特的
-
在Github README中添加Zread徽章添加徽章
来源
分支单元
-
rtl
-
datapath
- branch_unit.v
- alu.v
-
core
- riscv_core.v
- pc_adder.v
- control.v
-
-
programs/asm
- factorial.s
-
fibonacci.s
指令存储器
⌘K
-
- 分享
指令存储器 (
imem)是处理器的只读存储器,每个执行周期都从这里开始。在 TinyRISCV 的哈佛架构中,指令获取和数据访问通过物理上独立的存储子系统进行——这意味着imem专门用于向译码阶段传送 32 位指令字,不会与数据存储器产生结构冒险。尽管这个模块只有 15 行 Verilog 代码,但它围绕地址映射、初始化策略和访问语义作出了几个刻意的设计决策,值得深入理解。 来源:imem.v, riscv_core.v模块接口与信号作用
imem模块提供了一个极简的双信号接口——一个地址输入和一个指令输出。没有时钟、没有写端口、也没有控制信号。这是因为单周期处理器中的指令存储器本质上是只读且组合的 :任意时刻出现的 PC 值通过简单的数组查找直接生成对应的指令字,没有寄存器延迟。 信号| 方向| 位宽| 描述 —|—|—|—addr| input| 32 位| 来自程序计数器的字节地址instr| output| 32 位| 该地址处的 32 位指令字addr输入由 PC 寄存器 riscv_core.v 的pc驱动,instr输出分别扇出至指令译码器 和立即数生成器 ,构成了流水线中获取与译码阶段之间的桥梁。 来源:imem.v, riscv_core.v内部架构:存储阵列与地址映射
imem的核心是一个 1024 项 × 32 位的寄存器阵列,声明为reg [31:0] memory [0:1023],总容量为 4 KB (1024 个字 × 4 字节/字)。该阵列通过一条assign语句进行组合读取: VERILOG Copy code assign instr = memory[addr[11:2]]; 这一行代码包含了一个关键的地址转换——我们来拆解一下。PC 是一个字节地址 (RV32I 规范要求),但memory阵列是按字号 索引的。从 32 位字节地址中提取[11:2]位同时实现了两件事:
- 分享
指令存储器 (
- 除以 4 :舍弃最低两位(
[1:0])相当于将字节地址除以 4,将其转换为字索引。这之所以可行,是因为 RV32I 指令始终是 32 位对齐的,意味着任何有效指令地址的最低两位总是00。 - 10 位索引 :
[11:2]位构成了一个 10 位索引(范围 0–1023),与 1024 项的阵列完美匹配。地址的[31:12]位被直接忽略,这意味着 4 KB 范围(0x000–0xFFF)之外的任何地址都会悄无声息地别名映射回该阵列内部。 下图说明了在对存储阵列进行索引时,32 位 PC 地址是如何分解的: 32-bit Byte Address (PC) 0 → memory[0] 1 → memory[1] … 1023 → memory[1023] 31:12 Ignored 11:2 Word Index (10 bits) 1:0 00 (always) memory[0:1023] 1024 × 32-bit words 4 KB total instr[31:0] 来源:imem.v初始化:从汇编到存储器
指令存储器在仿真开始之前 通过 Verilog 系统任务
$readmemh进行填充。该任务在展开阶段读取十六进制文本文件,并逐项填充memory阵列: VERILOG Copy code initial begin $readmemh(“program.hex”, memory); endinitial块在 0 时刻执行一次——不需要时钟沿。十六进制文件program.hex必须位于仿真工作目录中(详见仿真与波形调试 )。从手写汇编到填充imem的完整工具链路径如下所示: riscv32-unknown-elf-as riscv32-unknown-elf-ld -T linker.ld riscv32-unknown-elf-objcopy -O verilog $readmemh .s source (assembly) .o object .elf executable .hex (Verilog hex) memory[0:1023] (imem array) 每个步骤都有其特定目的: 步骤| 工具| 目的 —|—|— 汇编|riscv32-unknown-elf-as| 将助记符翻译为机器码,解析标签 链接|riscv32-unknown-elf-ld| 使用linker.ld分配最终地址(基地址0x00000000) 转换|riscv32-unknown-elf-objcopy| 提取原始二进制文件并格式化为 Verilog 十六进制文本 加载|$readmemh| 在展开阶段填充memory阵列 链接脚本 linker.ld 确保了.text段从地址0x00000000开始,这与 PC 寄存器0x00000000的复位值完美对齐。这意味着复位后获取的第一条指令始终是memory[0]。 切换测试程序时,你必须将所需的.hex文件复制到sim/program.hex并重新运行仿真。$readmemh的路径是相对于仿真启动目录的,而不是项目根目录。 来源:imem.v, compile.sh, linker.ld, pc_register.v组合读取语义与时序
由于
imem使用连续assign语句而非时钟控制的always块,因此每当 PC 发生变化时,指令输出就会瞬时 更新。在地址输入与数据可用之间不存在单周期延迟。这是单周期处理器设计的决定性特征:整个获取-译码-执行-存储-写回序列在一个时钟周期内完成,指令存储器必须在同一组合路径中产生其输出。 在 TinyRISCV 的数据流中,指令字在imem产生后通过两条并行组合链路传播: addr instr[31:0] instr[31:0] PC Register (clocked) imem (combinational) Decoder (combinational) Imm Gen (combinational) Control Unit (combinational) 关键的时序意义在于,imem的读取延迟直接增加了从 PC 寄存器输出、经过译码、控制、ALU,再返回到 PC 寄存器输入的组合路径延迟。在 FPGA 实现中,该寄存器阵列通常映射为块 RAM,这可能会引入单周期读取延迟——从而需要对架构进行修改。但在仿真和教学场景中,组合模型因其清晰性而堪称理想之选。 来源:imem.v, riscv_core.v指令存储器与数据存储器:对比
TinyRISCV 采用哈佛架构,具有两个物理上独立的存储模块。虽然两者的容量均为 4 KB,但其设计因功能角色不同而存在显著差异: 属性| 指令存储器 (
imem)| 数据存储器 (dmem) —|—|— 容量| 4 KB (1024 × 32 位字)| 4 KB (4096 × 8 位字节) 访问| 只读| 读写 读取类型| 组合 (assign)| 组合 (always @*中的组合读取) 写入类型| 不支持| 时钟控制 (always @(posedge clk)) 粒度| 仅字 (32 位)| 字节 / 半字 / 字 控制信号| 无|mem_read,mem_write,funct3初始化| 展开时通过$readmemh初始化| 未初始化 (初始值为x) 地址映射|addr[11:2]→ 字索引|addr[11:0]→ 字节索引 最根本的区别在于访问粒度 。指令存储器只支持字对齐的 32 位读取,因为 RV32I 指令始终为 32 位宽。相比之下,数据存储器必须支持字节和半字访问,以实现LB/LH/LBU/LHU/SB/SH指令,这就是为什么dmem被组织为带有由funct3控制的符号扩展逻辑的字节可寻址阵列。imem的字索引方案(addr[11:2])默认每条指令地址的最低两位为零。如果跳转或分支目标未对齐(不是 4 的倍数),处理器将获取错误的指令而不会引发任何异常——RV32I 强制要求 32 位对齐,但 TinyRISCV 并未在硬件中强制执行此检查。 来源:imem.v, dmem.v地址空间与别名行为
指令存储器占据了 TinyRISCV 存储映射中的地址范围
0x00000000–0x00000FFF。然而,由于在索引计算中完全忽略了addr[31:12],任何共享相同[11:2]位的地址都将映射到同一个存储字。例如,0x00000100和0x10000100都会索引到memory[64]。这种别名现象在教学处理器中是一种常见的简化,只要程序停留在 4 KB 地址空间内就不会产生问题。 存储映射上下文如下: Copy code 0x00000000 ┌──────────────────┐ │ Instruction │ │ Memory (4 KB) │ ← imem: 1024 × 32-bit, read-only 0x00000FFF └──────────────────┘ … 0x10000000 ┌──────────────────┐ │ Data │ │ Memory (4 KB) │ ← dmem: 4096 × 8-bit, read/write 0x10000FFF └──────────────────┘ 由于链接脚本将代码放置在0x00000000,且 PC 复位至同一地址,程序自然驻留在非别名区域。如需深入了解完整的地址布局,请参阅存储映射与地址布局 。 来源:imem.v, linker.ld, architecture_zh.md总结
指令存储器模块可以用一条架构真理来概括:它是一个 4 KB 的只读查找表,以字对齐的 PC 作为索引,在展开阶段通过十六进制文件初始化,并在产生 PC 的同一周期内进行组合读取 。这种设计非常适合单周期教学处理器,在这里清晰性胜过运行频率。其权衡之处——不支持运行时写入、不支持子字访问、不进行对齐检查——是对简单性的刻意让步,使得获取阶段变得透明且易于推理。 要了解
imem输出指令字 之后 发生的事情,请继续阅读指令译码器 和立即数生成器 。如需了解互补的可写存储器,请参阅数据存储器 。要追踪输入到imem的 PC 地址是如何生成的,请参考 PC 寄存器 和 PC 加法器与下一 PC 选择 。 划线 写想法 提问 -
在Github README中添加Zread徽章添加徽章
来源
指令存储器
-
rtl
-
memory
- imem.v
- dmem.v
-
core
- riscv_core.v
- pc_register.v
-
-
programs
- linker.ld
- compile.sh
-
docs
-
architecture_zh.md
数据存储器
⌘K
-
-
- 分享
数据存储器模块是 TinyRISCV 的运行时数据读写存储器——它是处理器计算核心与指令执行过程中持久状态之间的桥梁。与纯组合逻辑 ROM 的指令存储器 不同,数据存储器是一个同步写、组合读 的 SRAM,支持所有五种 RV32I 加载变体和三种存储变体,并具备完整的小端字节寻址能力。它占用 4 KB 的地址空间,并且是数据通路中唯一一个
funct3直接控制 ALU 之外硬件行为的模块,它在每次事务中同时控制访问宽度和符号扩展语义。模块接口与信号映射
数据存储器公开了一个简洁的六输入、一输出接口,连接到三个不同的数据通路元件:ALU 提供地址,寄存器堆 提供写入数据,控制单元 通过
mem_read/mem_write限定符协调时序。funct3字段——由指令译码器 直接从指令中译码得出——用于选择子字访问模式。 端口| 方向| 位宽| 核心来源| 用途 —|—|—|—|—clk| input| 1| 全局时钟| 同步写边沿addr| input| 32|alu_result| 字节级存储器地址write_data| input| 32|rs2_data| 待存储数据 (SW/SH/SB)mem_read| input| 1| 控制单元| 读使能 (Load 指令)mem_write| input| 1| 控制单元| 写使能 (Store 指令)funct3| input| 3| 译码器| 访问宽度 + 符号扩展read_data| output| 32| —| 加载至写回复用器的数据 在riscv_core.v中的集成将 ALU 结果直接作为地址连线,将寄存器堆的rs2_data作为存储负载。这意味着每次加载或存储的有效地址 由 ALU 计算为rs1 + imm——即 RV32I 规定的标准基址加偏移寻址模式。 来源: dmem.v, riscv_core.v存储架构
存储阵列被声明为
reg [7:0] memory [0:4095]——一个字节可寻址 的 4 KB 阵列,包含 4096 个可独立写入的 8 位条目。对于必须支持在地址空间内任意对齐的字节、半字和字访问的处理器而言,这是最灵活的表示方式。地址通过wire [11:0] byte_addr = addr[11:0]截断至低 12 位,这自然映射到 4096 个条目的范围,并与0x1000_0000 – 0x1000_0FFF处的存储映射区域对齐。 4 KB 存储阵列 32位地址 12位索引 addr[31:12] 未使用的高位 addr[11:0] byte_addr memory[0] memory[1] … memory[4095] 地址的高 20 位被静默丢弃。在当前的单核、单存储器设计中,这是无害的——核心的链接脚本将.data和.bss段放置在 4 KB 窗口内——但这确实意味着0x1000_0000 ± 4 KB范围之外的地址会别名化到相同的物理阵列中。量产设计会添加地址范围检查或更复杂的存储映射;完整的地址规划请参见存储映射与地址布局 。 来源: dmem.v, linker.ld写路径:同步存储操作
所有写事务均在时钟上升沿边沿触发 ,并由
mem_write门控。funct3字段决定提交write_data中的多少字节,遵循小端约定,即最低有效字节驻留在最低地址 : 存储指令|funct3| 写入字节数| 地址偏移 —|—|—|— SB (Store Byte)|3'b000| 1|[byte_addr + 0]←write_data[7:0]SH (Store Half)|3'b001| 2|[byte_addr + 0]←write_data[7:0],[byte_addr + 1]←write_data[15:8]SW (Store Word)|3'b010| 4|[byte_addr + 0..3]←write_data[7:0],write_data[15:8],write_data[23:16],write_data[31:24]字节分解是显式的——write_data的每个 8 位切片被赋值给连续的存储位置。例如,对于地址0x100处的存储字,字节 0(第 7:0 位)存入memory[256],字节 1 存入memory[257],字节 2 存入memory[258],字节 3(第 31:24 位)存入memory[259]。这是教科书级别的小端布局,与 RISC-V 规范对小端字节排序的要求一致。 SB (000) 和 SH (001) 的funct3编码分别与 LB 和 LH 重叠。这是安全的,因为加载和存储指令是互斥的——控制单元永远不会同时置位mem_read和mem_write。funct3的解释依赖于上下文:当mem_write为高电平时,000代表 SB;当mem_read为高电平时,000代表 LB。 来源: dmem.v, control.v读路径:组合加载操作
读事务是组合逻辑 的——当
mem_read、addr或存储器内容发生变化时,read_data会瞬时更新。这对单周期设计至关重要:加载值必须在同一个时钟周期内可用,以便在下一个上升沿之前流经写回复用器并进入寄存器堆。funct3字段选择五种加载模式之一,每种模式具有不同的符号扩展行为: 加载指令|funct3| 读取字节数| 符号扩展| 输出构造 —|—|—|—|— LB (Load Byte)|3'b000| 1| 符号扩展|, mem[addr]}LH (Load Half)|3'b001| 2| 符号扩展|, mem[addr+1], mem[addr]}LW (Load Word)|3'b010| 4| 无 (完整字)|{mem[addr+3], mem[addr+2], mem[addr+1], mem[addr]}LBU (Load Byte Unsigned)|3'b100| 1| 零扩展|{24'b0, mem[addr]}LHU (Load Byte Unsigned)|3'b101| 2| 零扩展|{16'b0, mem[addr+1], mem[addr]}有符号与无符号加载之间的差异在体系结构上具有重要意义。对于 LB,获取字节的最高有效位(第 7 位)被复制 24 次以填充 32 位结果的高半部分——这是 Verilog 的惯用语法, memory[byte_addr]}。对于 LBU,高 24 位被硬连线为零。相同的模式也适用于 LH 与 LHU 的半字级别,其中符号位取自字节 1(半字的高字节)。对于任何未定义的funct3值,default分支返回32'b0,提供安全的回退机制。 当mem_read为低电平时,read_data被无条件驱动为32'b0。这可以防止未定义(X)状态在非加载指令期间传播到写回复用器,这一点至关重要,因为mem_to_reg在alu_result和read_data之间进行选择——悬空总线会破坏 ALU 结果路径。 来源: dmem.v, riscv_core.v数据通路集成:存储器阶段
数据存储器位于 TinyRISCV 单周期流水线中 MEM 阶段的核心。控制单元为所有 Load 类型指令(操作码
0000011)生成mem_read,为所有 Store 类型指令(操作码0100011)生成mem_write。这些信号永远不会被同时置位 ,从而消除了对读写冒险逻辑的需要。下图展示了通过存储器阶段的完整信号流: 写回 存储器阶段 执行阶段 addr write_data mem_read/mem_write funct3 read_data alu_result ALU alu_result RegFile rs2 rs2_data Control mem_read / mem_write Decoder funct3 Data Memory dmem mem_to_reg Mux RegFile Write write_back_datariscv_core.v中的写回复用器逻辑——write_back_data = jump ? pc_plus_4 : (mem_to_reg ? mem_read_data : alu_result)——揭示了存储器阶段在更广泛的数据通路中的作用。当mem_to_reg被置位时(Load 指令),从数据存储器读取的值将覆盖 ALU 结果,作为寄存器堆的写回数据来源。对于 Store 指令,控制单元撤销置位reg_write,因此read_data被直接忽略。 来源: riscv_core.v, control.v实践中的小端字节排序
小端约定对多字节值在存储器中的布局方式以及读取时的重构方式具有具体影响。考虑通过 SW 将 32 位值
0xDEADBEEF存储到地址0x100: 地址| 存储索引| 存储字节| 位来源 —|—|—|—0x100|memory[256]|0xEF|write_data[7:0]0x101|memory[257]|0xBE|write_data[15:8]0x102|memory[258]|0xDE|write_data[23:16]0x103|memory[259]|0xAD|write_data[31:24]通过 LW 将其读回时,会以相反的顺序重新组装字节来重构原始值:{memory[259], memory[258], memory[257], memory[256]}={0xAD, 0xDE, 0xBE, 0xEF}——但这种拼接产生了原始的0xDEADBEEF,因为最高有效字节(存储在最高地址)被放置在了 32 位结果的最高有效位置。这种往返一致性是正确的小端实现的标志性特征。 来源: dmem.v设计权衡与观察
同步写 + 组合读 是单周期处理器的自然选择。写入必须经过时钟同步以持久保持状态,而读取必须是组合逻辑的,以便加载的值能在同一周期内用于写回。这种不对称性意味着当地址改变时,
read_data会立即改变——没有读延迟——但这同时意味着存储阵列馈送了一条组合逻辑路径,该路径构成了整个处理器的关键路径。 未实现对齐检查 。RV32I 规范允许未对齐的访问触发陷阱,但 TinyRISCV 无论对齐方式如何都会执行访问——对奇数地址的存储字将毫无阻碍地写入四个连续字节。对于教学型处理器而言,这是一种可接受的简化,但真实的软件应确保自然对齐的访问,以保证正确性和可移植性。 子字存储与加载 funct3 重叠 在构造上是安全的。由于mem_read和mem_write是互斥的控制信号,加载和存储操作之间共享的funct3命名空间永远不会引起歧义。控制单元保证了这一不变量:Load 设置{mem_read=1, mem_write=0},而 Store 设置{mem_read=0, mem_write=1}。 由于读路径是组合逻辑的,并在mem_read为低电平时将read_data驱动为32'b0,数据存储器永远不会向写回复用器注入 X 状态。这是一个微妙但重要的设计选择——如果读逻辑中没有else分支,非加载指令将使read_data保持为未定义的值,即使mem_to_reg选择了 ALU 输出,这仍可能破坏 ALU 结果路径,因为仿真工具可能会通过复用器传播 X 状态。 来源: dmem.v, control.v后续内容
在存储子系统完整记录之后,下一个合乎逻辑的步骤是检查决定接下来从存储器中取哪条指令的 PC 逻辑 ——保存当前程序计数器的 PC 寄存器 ,以及计算下一条指令地址的 PC 加法器与 Next-PC 选择 逻辑。要全面了解所有模块如何互连,请参见顶层模块集成 ;要查阅完整的信号字典,请参阅控制信号参考 。 划线 写想法 提问
- 分享
数据存储器模块是 TinyRISCV 的运行时数据读写存储器——它是处理器计算核心与指令执行过程中持久状态之间的桥梁。与纯组合逻辑 ROM 的指令存储器 不同,数据存储器是一个同步写、组合读 的 SRAM,支持所有五种 RV32I 加载变体和三种存储变体,并具备完整的小端字节寻址能力。它占用 4 KB 的地址空间,并且是数据通路中唯一一个
-
在Github README中添加Zread徽章添加徽章
来源
数据存储器
-
rtl
-
memory
- dmem.v
-
core
- riscv_core.v
- control.v
-
-
programs
-
linker.ld
PC 寄存器
⌘K
-
-
- 分享
程序计数器 (PC) 寄存器 是任何处理器的心跳——它保存着当前正在执行指令的内存地址,在每个时钟周期,它要么前进到下一条指令,要么跳转到一个新位置。在 TinyRISCV 中,PC 寄存器刻意保持极简:一个带有异步复位和暂停机制的 32 位寄存器。这种简单性并非偶然;关于 PC 下一步走向 何处 的所有复杂性,都被委派给了配套的 PC 加法器与下一 PC 选择 模块,从而保持寄存器本身是一个纯粹且易于验证的时序元件。
接口与端口映射
pc_register模块仅暴露五个端口——三个输入和两个输出(一根线网,一个寄存器)。这种紧凑的接口反映了它的单一职责:存储当前 PC 并在每个周期原子性地更新它 。 端口| 方向| 位宽| 描述 —|—|—|—clk| input| 1| 系统时钟——PC 在上升沿更新rst_n| input| 1| 低电平有效的异步复位——将 PC 清零为0x00000000pc_next| input| 32| 下一个 PC 值,由pc_adder外部计算halt| input| 1| 冻结信号——当为高电平时,PC 保持当前值pc| output| 32| 当前程序计数器值(声明为output reg) 来源: pc_register.v内部逻辑:三态更新
PC 寄存器的核心是一个具有清晰三路优先级结构的单一
always块。理解此优先级链对于推断复位和程序终止期间的处理器行为至关重要。 VERILOG Copy code always @(posedge clk or negedge rst_n) begin if (!rst_n) begin pc <= 32’h00000000; end else if (!halt) begin pc <= pc_next; end end 敏感列表posedge clk or negedge rst_n确立了异步复位 ——一旦rst_n变低,PC 便会立即清零,而与时钟无关。这是最高优先级的路径。当rst_n为高电平(正常操作)时,该块在每个时钟上升沿进行评估:如果halt为低电平,PC 加载pc_next;如果halt为高电平,则不进行赋值,因此寄存器通过 Verilog 时序逻辑中的隐式锁存行为保持其先前值 (reg根本没有改变)。 在!halt之后缺少显式的else分支是刻意为之的——它创造了一个“保持”条件,即pc维持其原值。这不是锁存器 Bug;在时序always @(posedge clk)块中,未赋值的reg会保留其上次赋的值,这正是halt = 1时所期望的冻结行为。 来源: pc_register.v状态转换图
下图捕获了 PC 寄存器可能发生的每次转换。请注意,
halt仅在正常的时钟驱动操作中起作用——它无法覆盖复位。 Syntax error in textmermaid version 11.6.0 来源: pc_register.v暂停机制
halt信号源自顶层riscv_core模块,它直接由指令操作码推导而来: VERILOG Copy code assign halt = (opcode == 7’b1110011); 操作码7'b1110011对应于 RV32I SYSTEM 指令类型,其中包括ECALL和EBREAK。在 TinyRISCV 的编程模型中,ECALL指令标志着程序终止——处理器将永久冻结 PC(直到下一次复位)。当halt = 1时,PC 寄存器直接停止更新,由于无法获取新指令,这实质上使得整个流水线停顿。 来源: riscv_core.v为什么暂停逻辑属于 PC 寄存器
你可能好奇为什么暂停逻辑位于 PC 寄存器内部,而不是在顶层通过门控时钟或多路复用
pc_next来处理。这一设计选择意义重大:将冻结机制置于寄存器内部消除了对外部多路复用逻辑的需求 ,并避免了 PC 漂移到未定义状态的任何风险。寄存器变得自包含——它要么更新,要么不更新——这使得验证变得极其简单,并且免除了外部基于多路复用器停顿可能产生的毛刺隐患。核心数据流中的 PC 寄存器
PC 寄存器位于处理器数据流链的最前端。其输出
pc扇出至三个消费者,而其输入pc_next由单一源产生。这种扇出模式使得 PC 寄存器成为当前执行位置的唯一事实来源 。 Syntax error in textmermaid version 11.6.0 让我们追踪这三个消费者路径: 1. 指令获取 (imem) — PC 被直接送入指令存储器的addr端口。在imem内部,字对齐的索引addr[11:2]从 1024 项数组中选择一条 32 位指令。这意味着 PC 必须始终是 4 的倍数(字对齐);未对齐的 PC 将获取错误的指令。 2. AUIPC 操作数 —AUIPC指令(将上限立即数加到 PC)需要将当前 PC 值作为 ALU 输入。在riscv_core.v中,当操作码为7'b0010111(AUIPC) 时,多路复用器选择pc作为alu_operand_a,否则选择rs1_data。 3. 返回地址 (pc + 4) — 对于跳转指令(JAL和JALR),返回地址pc + 4在核心中计算并写回目标寄存器。这不是在 PC 寄存器内部计算的——它是顶层的组合加法。 来源: riscv_core.v, imem.v, riscv_core.v, riscv_core.v复位行为与启动地址
复位时,PC 被初始化为
32'h00000000。这定义了启动地址 ——处理器退出复位后获取的第一条指令。在 TinyRISCV 内存映射中,地址0x00000000映射到指令存储器的首个条目 (memory[0]),该条目在仿真时从program.hex加载。 条件| PC 值| 效果 —|—|—rst_n = 0(异步)|0x00000000| 立即、独立于时钟的复位rst_n = 1,halt = 0(clk 上升沿)|pc_next| 正常的顺序或分支更新rst_n = 1,halt = 1(clk 上升沿)| 不变| 处理器冻结在当前指令 异步复位意味着 PC 在rst_n下降的 瞬间 清零,而不是在下一个时钟沿。这对仿真至关重要:测试台在释放rst_n之前会将其保持为 0 持续 20 ns(两个时钟周期),以确保在首次指令获取发生前 PC 稳定在0x00000000。 来源: pc_register.v, riscv_core_tb.v在仿真中观察 PC
测试台通过
riscv_core的pc_out端口暴露 PC 值,这是一个直接的线网赋值: VERILOG Copy code assign pc_out = pc; 在每个时钟正沿(复位释放后),测试台会打印当前 PC 和正在执行的指令: Copy code PC = 0x00000000, Instruction = 0x…….. PC = 0x00000004, Instruction = 0x…….. … 当halt信号变高时,最终显示为:Program halted at PC = 0x...。此时,PC 已冻结在ECALL指令的地址处——除非再次触发复位,否则它不会继续前进。 来源: riscv_core.v, riscv_core_tb.v, riscv_core_tb.v设计原理:存储与计算的分离
PC 寄存器最引人注目的设计特征在于它不做什么 ——它不计算
pc_next。所有的下一 PC 逻辑(顺序递增、分支偏移加法、JALR 目标计算)都驻留在独立的 PC 加法器与下一 PC 选择 模块中。这种分离带来了切实的好处: 方面| 组合设计| 分离设计 (TinyRISCV) —|—|— 单模块复杂度| 较高——一个模块承担两项职责| 较低——每个模块职责单一 验证| 必须在一处测试所有 PC 路径| 寄存器:仅测试保持/复位;加法器:测试所有路径 可复用性| 与控制信号紧密耦合| 寄存器是通用的;加法器是特定于 ISA 的 调试波形| 难以隔离存储与计算| 信号边界清晰——pc对比pc_next这是单一职责原则 在硬件设计中的刻意应用:寄存器负责存储,加法器负责计算。当你追踪波形并看到pc_next改变而pc未更新时,你立刻就能知道halt处于激活状态——无需深入挖掘寄存器内部的组合逻辑。 来源: pc_register.v, pc_adder.v后续内容
PC 寄存器的输出
pc只是故事的一半——另一半是pc_next是如何确定的。当你准备好了解从“我在哪里”到“下一步去哪里”的完整流程时,请继续阅读 PC 加法器与下一 PC 选择 ,该部分涵盖了三个下一 PC 来源(PC+4、分支偏移和 JALR 寄存器间接目标)以及由控制单元pc_src信号驱动的多路复用逻辑。如果你想了解 PC 如何馈送到获取阶段,请回顾 指令存储器 ;若要查看更广泛的架构全貌,请参阅 架构概述 。 划线 写想法 提问
- 分享
程序计数器 (PC) 寄存器 是任何处理器的心跳——它保存着当前正在执行指令的内存地址,在每个时钟周期,它要么前进到下一条指令,要么跳转到一个新位置。在 TinyRISCV 中,PC 寄存器刻意保持极简:一个带有异步复位和暂停机制的 32 位寄存器。这种简单性并非偶然;关于 PC 下一步走向 何处 的所有复杂性,都被委派给了配套的 PC 加法器与下一 PC 选择 模块,从而保持寄存器本身是一个纯粹且易于验证的时序元件。
-
在Github README中添加Zread徽章添加徽章
来源
PC 寄存器
-
rtl
-
core
- pc_register.v
- riscv_core.v
- pc_adder.v
-
memory
- imem.v
-
-
tb
-
riscv_core_tb.v
PC 加法器与下一 PC 选择
⌘K
-
-
- 分享
pc_adder 模块是处理器的下一地址解析器——一个纯组合逻辑电路,用于决定程序计数器在下一个时钟沿应指向何处。它接收来自控制单元 的路由指令、来自分支单元 的条件评估结果,以及来自寄存器堆 的寄存器数据,随后生成一个单一的
pc_next信号,该信号将反馈回PC 寄存器 。尽管该模块代码简短(仅 37 行),却封装了 TinyRISCV 设计中最关键的架构决策之一:如何将三种根本不同的地址计算模式——顺序寻址、PC 相对寻址和寄存器间接寻址——统一到一条单一的多路复用路径中。 来源: pc_adder.v, riscv_core.v模块接口与信号映射
pc_adder模块暴露了六个输入和一个输出。在研究内部选择逻辑之前,理解每个信号的来源和用途至关重要。 信号| 位宽| 方向| 来源模块| 描述 —|—|—|—|—pc| 32| input| pc_register| 当前程序计数器的值imm| 32| input| imm_gen| 当前指令经符号扩展的立即数rs1_data| 32| input| regfile| 从寄存器 rs1 读取的值(仅用于 JALR)pc_src| 2| input| control| 主路径选择器:00=+4,01=分支/跳转,10=JALRbranch_taken| 1| input| branch_unit| 条件分支评估结果jump| 1| input| control| 无条件跳转标志 (JAL/JALR)pc_next| 32| output| —| 计算出的下一个 PC 值,馈入 pc_registerpc_src信号是主路由控制 ——它选择激活三条计算路径中的哪一条。branch_taken和jump信号在PC_BRANCH路径中充当次要限定符 ,决定是否真正应用分支偏移量还是回退到 PC+4。 来源: pc_adder.v, riscv_core.v三路径下一 PC 架构
该模块实现了三条不同的地址计算路径,由
pc_src信号进行选择。下图展示了数据如何从各个来源流经 pc_adder 以生成pc_next: Syntax error in textmermaid version 11.6.0 每条路径对应 RV32I ISA 中的一种独立寻址模式。下表总结了各路径所执行的算术运算及其服务的指令类型: 路径|pc_src| 计算| 适用指令| 激活条件 —|—|—|—|— 顺序寻址|2'b00|pc + 4| R-type, I-type ALU, Load, Store, LUI, AUIPC, SYSTEM| 总是(默认) PC 相对寻址|2'b01|pc + imm或pc + 4| BEQ, BNE, BLT, BGE, BLTU, BGEU, JAL| 当branch_taken || jump时为pc+imm;否则为pc+4寄存器间接寻址|2'b10|(rs1_data + imm) & ~1| JALR| 当pc_src = 2'b10时总是激活 来源: pc_adder.v, control.v逐路径深入剖析
顺序路径:PC + 4
默认路径显然是
pc + 4,这反映了 RV32I 固定的 4 字节指令宽度。当控制单元解码出非改变控制流的指令(R-type 计算、内存访问、LUI、AUIPC)时,pc_src保持其默认值2'b00,执行推进到内存中的下一条指令。当条件分支未发生跳转时,该路径也作为 PC_BRANCH 路径中的回退方案 ——处理器只是简单地“顺序执行”,如同分支从未存在过一样。 来源: pc_adder.v, control.vPC 相对路径:分支与 JAL 的统一
这是 TinyRISCV 在 PC 逻辑中做出的最值得注意的架构决策。该设计并没有为条件分支(
B-type)和无条件跳转(JAL)分别实现独立的路径,而是将它们合并为一条单一的 PC_BRANCH 路径 ,由复合条件branch_taken || jump控制: Copy code PC_BRANCH: begin if (branch_taken || jump) begin pc_next = pc + imm; // 分支跳转 / JAL 跳转 end else begin pc_next = pc + 4; // 分支未跳转 —— 顺序执行 end end 对于条件分支 (BEQ/BNE/BLT/BGE/BLTU/BGEU),控制单元设置pc_src = PC_BRANCH且branch = 1,但jump = 0。分支单元 评估rs1_data和rs2_data之间的比较,产生branch_taken信号。如果条件成立,则pc_next = pc + imm——来自立即数生成器 的经符号扩展且已左移 1 位的立即数会产生正确的分支目标。如果条件不成立,branch_taken为 0 且jump也为 0,因此表达式的计算结果为pc + 4。 对于 JAL (无条件跳转并链接),控制单元设置pc_src = PC_BRANCH且jump = 1。因为jump无条件为 1,所以branch_taken || jump表达式总是评估为真 ,而与branch_taken无关。结果是:pc_next = pc + imm,即将 J-type 立即数(符号扩展并左移 1 位)与当前 PC 相加。这种复用消除了专用的 JAL 路径,以一个单 OR 门的代价节省了多路复用器的宽度和布线复杂度。jump信号在 TinyRISCV 中发挥了双重作用:它强制 PC_BRANCH 路径总是采用偏移量,并且 它控制写回(在 riscv_core.v 中,write_back_data = jump ? pc_plus_4 : ...),将 PC+4 存入链接寄存器 rd。这种双角色设计意味着 JAL 和 JALR 是仅有的保存返回地址的指令。 来源: pc_adder.v, control.v, riscv_core.v寄存器间接寻址路径:JALR
PC_JALR路径是 TinyRISCV 中实现间接跳转 的唯一机制。它计算pc_next = (rs1_data + imm) & ~32'b1,其中与~1进行按位与操作会清除最低有效位。这种最低有效位清零是 RV32I 规范强制要求的:JALR 的目标必须是半字对齐的(偶数地址),规范明确规定,无论加法结果如何,计算目标的最低有效位始终设置为零。 操作数来自不同的来源:rs1_data来自寄存器堆,而imm来自 I-type 立即数字段(符号扩展的 12 位)。这支持了两种关键模式:函数返回 (jalr x0, 0(ra),其中rs1_data = ra且imm = 0)和间接调用 (jalr ra, offset(rs1),两者共同构成目标地址)。 与 PC_BRANCH 路径不同,JALR 路径没有条件门控 ——当pc_src = PC_JALR时,计算总是被执行。这是合理的,因为 JALR 本质上是无条件的;RV32I 中控制流的“条件”方面完全由 B-type 指令处理。 来源: pc_adder.v, control.vPC 选择的控制信号推导
pc_src信号由控制单元 根据解码的opcode生成。下表准确展示了每种指令类别如何映射到其pc_src值以及伴随信号branch和jump: 指令类别| Opcode|pc_src|branch|jump| 对 pc_adder 的影响 —|—|—|—|—|— R-type (ADD, SUB, …)|0110011|00| 0| 0| 顺序寻址:pc + 4I-type ALU (ADDI, …)|0010011|00| 0| 0| 顺序寻址:pc + 4LUI|0110111|00| 0| 0| 顺序寻址:pc + 4AUIPC|0010111|00| 0| 0| 顺序寻址:pc + 4Load|0000011|00| 0| 0| 顺序寻址:pc + 4Store|0100011|00| 0| 0| 顺序寻址:pc + 4Branch (BEQ, BNE, …)|1100011|01| 1| 0| 条件寻址:跳转时为pc + imm,否则为pc + 4JAL|1101111|01| 0| 1| 无条件寻址:pc + imm(总是跳转) JALR|1100111|10| 0| 1| 间接寻址:(rs1 + imm) & ~1SYSTEM (ECALL, EBREAK)|1110011|00| 0| 0| 顺序寻址(停机) 控制单元组合逻辑块中的默认情况在 opcode case 语句之前初始化了pc_src = PC_PLUS4,branch = 0,jump = 0,确保任何无法识别的指令都能安全地落入顺序执行,而不是产生未定义的 PC 行为。 来源: control.v在核心数据路径中的集成
pc_adder 位于处理器数据路径的反馈环路闭合点 。其输出
pc_next馈入PC 寄存器 ,后者在下一个上升沿锁存该值(除非停机),然后锁存的pc值驱动指令存储器,从而完成循环。下图展示了从控制信号生成、经过下一 PC 计算到 PC 更新的完整信号链: Syntax error in textmermaid version 11.6.0 在 pc_adder 与 riscv_core.v 中的写回逻辑 之间存在一个值得注意的交互。虽然 pc_adder 计算下一个 PC,但核心单独计算pc_plus_4 = pc + 4(第 122 行)用于写回多路复用器:write_back_data = jump ? pc_plus_4 : (mem_to_reg ? mem_read_data : alu_result)。这意味着 PC+4 被计算了两次 ——一次在 pc_adder 内部,一次在核心层。这种冗余存在是因为 pc_adder 内部的pc + 4并没有作为单独的输出暴露;它被封装在了模块的选择逻辑中。对于一款教学型处理器而言,这种清晰的封装权衡是有意为之的——它以增加一个 32 位加法器为代价,保持了 pc_adder 的独立性。 AUIPC 指令不 使用 pc_adder 进行其 PC 相对计算。相反,当opcode == 7'b0010111时,riscv_core.v 将pc直接路由到 ALU 作为alu_operand_a,然后由 ALU 计算pc + imm。这意味着 AUIPC 的结果流经 ALU 数据路径,而 JAL 的 PC 相对目标流经 pc_adder——这是“使用 PC 计算值”(AUIPC → ALU)与“使用偏移量改变 PC”(JAL → pc_adder)之间的刻意分离。 来源: riscv_core.v, pc_adder.v立即数值准备
到达 pc_adder 的
imm输入已由立即数生成器 进行了预处理,其格式因指令类型而异。这种预处理至关重要,因为 pc_adder 本身不执行任何移位或编码——它只是简单地将imm加到pc(或rs1_data)上: 指令| 立即数格式| imm_gen 中的关键位操作| pc_adder 接收的内容 —|—|—|— B-type (BEQ, …)| B-format| 符号扩展,左移 1 位 (bit 0 = 0)|pc + sign_ext(offset<<1)JAL| J-format| 符号扩展,左移 1 位 (bit 0 = 0)|pc + sign_ext(offset<<1)JALR| I-format| 仅符号扩展(无左移)|(rs1 + sign_ext(offset)) & ~1针对 B-type 和 J-type 立即数的左移 1 位操作是由 imm_gen 模块执行的(在 imm_gen.v 的第 27 和 35 行追加到 LSB 的1'b0),而不是由 pc_adder 执行。这种设计选择使 pc_adder 保持为纯算术/多路复用单元,而不包含特定格式的知识,从而维持了清晰的关注点分离。 来源: imm_gen.v, pc_adder.v设计权衡与备选方案
TinyRISCV 的 pc_adder 反映了几项深思熟虑的架构选择,每项都有可量化的权衡: 决策| 理由| 权衡 —|—|— 将 JAL 合并到 PC_BRANCH 路径| 节省专用的多路复用器输入;JAL 只是无条件分支| 即使对于 JAL 也会计算
branch_taken信号(在 branch_unit 中浪费了比较操作) 将 pc+4 封装在 pc_adder 内| 自包含模块;接口清晰| PC+4 被计算两次(一次在 pc_adder 中,一次在 riscv_core 中用于写回) 纯组合逻辑设计| 单周期处理器;无需流水线寄存器| 从 PC 经 imem → 解码器 → 控制单元 → pc_adder 再返回到 PC 的长组合路径 无分支预测| 教学简洁性;在同一周期内完成分支解析| 每次发生的跳转无额外开销(单周期),但关键路径包含了 branch_unit 评估 JALR 使用寄存器端口| 利用现有的寄存器堆读取端口| JALR 目标依赖于 rs1_data,将寄存器堆读取添加到了 PC 计算的关键路径中 其中最重要的是 JAL/分支统一 。在流水线处理器中,这种合并会带来问题,因为分支解析通常在执行阶段进行,而 JAL 目标计算可以更早发生(在解码阶段)。但在 TinyRISCV 的单周期模型中,两者同时解决,使得共享路径既正确又高效。 来源: pc_adder.v, control.v, riscv_core.v后续内容
随着 PC 逻辑的完整记录,处理器的控制和数据路径组件现已齐备。接下来的自然步骤是探索这些模块共同实现的完整指令集,或者检查集成核心在仿真中的行为:
- 分享
pc_adder 模块是处理器的下一地址解析器——一个纯组合逻辑电路,用于决定程序计数器在下一个时钟沿应指向何处。它接收来自控制单元 的路由指令、来自分支单元 的条件评估结果,以及来自寄存器堆 的寄存器数据,随后生成一个单一的
- RV32I 指令参考 —— 所有 40 条支持指令到其 opcode、funct3、funct7 编码及行为的完整映射
- 控制信号参考 —— 每种指令类型对应的每个控制信号值的详尽表格
- 顶层模块集成 —— 所有模块如何在
riscv_core.v中连线,包括完整的信号互连 划线 写想法 提问 -
在Github README中添加Zread徽章添加徽章
来源
PC 加法器与下一 PC 选择
-
rtl
-
core
- pc_adder.v
- riscv_core.v
- control.v
-
datapath
-
imm_gen.v
RV32I 指令参考
⌘K
-
-
-
- 分享
TinyRISCV 实现了 RV32I 基础整数指令集 的一个重要子集——即 RISC-V 规范定义的基础 32 位指令架构。本参考文档编录了该处理器实际支持的每一条指令,将它们逐一映射到贯穿译码器、控制单元、ALU 和分支单元的硬件实现路径,并着重标明了少数被刻意省略的标准 RV32I 指令。理解本参考文档对于编写正确的汇编程序,以及在波形调试期间沿着处理器的数据通路追踪指令执行过程至关重要。
指令编码格式
所有 RV32I 指令的位宽均为 32 位,并属于六种编码格式之一。译码器 模块从每条指令的固定位位置提取公共字段——
opcode、rd、rs1、rs2、funct3和funct7——而与格式无关。操作码决定了指令格式,控制单元和立即数生成器则利用该信息正确路由其余位。 格式| 第 31–25 位| 第 24–20 位| 第 19–15 位| 第 14–12 位| 第 11–7 位| 第 6–0 位 —|—|—|—|—|—|— R 型| funct7| rs2| rs1| funct3| rd| opcode I 型| imm[11:0]| —| rs1| funct3| rd| opcode S 型| imm[11:5]| rs2| rs1| funct3| imm[4:0]| opcode B 型| imm[12|10:5]| rs2| rs1| funct3| imm[4:1|11]| opcode U 型| imm[31:12]| —| —| —| rd| opcode J 型| imm[20|10:1|11|19:12]| —| —| —| rd| opcode 译码器执行的是纯粹基于位位置的提取,不包含任何条件逻辑:opcode = instr[6:0]、rd = instr[11:7]、funct3 = instr[14:12]、rs1 = instr[19:15]、rs2 = instr[24:20]以及funct7 = instr[31:25]。对于缺少某些字段的格式(例如,I 型没有 rs2 或 funct7),这些位则承载立即数——译码器仍然会提取它们,但控制单元和立即数生成器会根据操作码对它们进行不同的解析。 来源:decoder.v,control.v按操作码分类指令
控制单元通过 7 位操作码识别指令类别。每个操作码触发一组独特的控制信号组合来引导数据通路——在寄存器操作数和立即数操作数之间进行选择、启用内存读取或写入,以及确定下一个 PC 值。下表汇总了 TinyRISCV 识别的所有操作码。 操作码| 十六进制| 格式| 类别| 描述 —|—|—|—|—
0110011| 0x33| R 型| 算术/逻辑 (reg-reg)| 寄存器-寄存器操作0010011| 0x13| I 型| 算术/逻辑 (reg-imm)| 寄存器-立即数操作0110111| 0x37| U 型| 上位立即数| 加载上位立即数0010111| 0x17| U 型| 上位立即数| 将上位立即数加到 PC0000011| 0x03| I 型| 加载| 内存加载 (字节/半字/字)0100011| 0x23| S 型| 存储| 内存存储 (字节/半字/字)1100011| 0x63| B 型| 分支| 条件分支1101111| 0x6F| J 型| 跳转| 跳转并链接1100111| 0x67| I 型| 跳转| 跳转并链接寄存器1110011| 0x73| I 型| 系统| ECALL (停机) 操作码字段是整个处理器中最重要的决策点。它决定了激活哪些数据通路元件、立即数如何进行符号扩展,以及结果是否写回寄存器——所有这些都在单个时钟周期内完成。 来源:control.vR 型指令 (操作码 0x33)
R 型指令执行寄存器到寄存器的操作。两个源操作数均来自寄存器堆 (rs1 和 rs2),结果写回 rd。funct3 字段选择操作类别,而对于移位和加/减操作,funct7 字段提供最终的区分——具体而言,
funct7[5]区分了 SUB 与 ADD,以及 SRA 与 SRL。控制单元为 R 型设置alu_src = 0,确保 ALU 接收 rs2_data 而非立即数。 指令| funct3| funct7| ALU 操作| 汇编语法| 行为 —|—|—|—|—|— ADD| 000| 0000000| ALU_ADD|add rd, rs1, rs2| rd = rs1 + rs2 SUB| 000| 0100000| ALU_SUB|sub rd, rs1, rs2| rd = rs1 − rs2 SLL| 001| 0000000| ALU_SLL|sll rd, rs1, rs2| rd = rs1 « rs2[4:0] SLT| 010| 0000000| ALU_SLT|slt rd, rs1, rs2| rd = (rs1 < rs2) ? 1 : 0 (有符号) SLTU| 011| 0000000| ALU_SLTU|sltu rd, rs1, rs2| rd = (rs1 < rs2) ? 1 : 0 (无符号) XOR| 100| 0000000| ALU_XOR|xor rd, rs1, rs2| rd = rs1 ⊕ rs2 SRL| 101| 0000000| ALU_SRL|srl rd, rs1, rs2| rd = rs1 » rs2[4:0] (逻辑) SRA| 101| 0100000| ALU_SRA|sra rd, rs1, rs2| rd = rs1 »> rs2[4:0] (算术) OR| 110| 0000000| ALU_OR|or rd, rs1, rs2| rd = rs1 | rs2 AND| 111| 0000000| ALU_AND|and rd, rs1, rs2| rd = rs1 & rs2 移位量取自rs2[4:0](低 5 位),产生 0–31 的范围——适合对 32 位值进行移位。ALU 直接实现了这一点:对于 SLL,result = operand_a << operand_b[4:0],SRL 和 SRA 的逻辑类似。对于 SLT 中的有符号比较,ALU 使用$signed(operand_a) < $signed(operand_b),而 SLTU 使用无符号比较。 来源:control.v,alu.vI 型指令 (操作码 0x13)
I 型算术/逻辑指令对一个寄存器操作数 (rs1) 和一个 12 位符号扩展的立即数进行操作。控制单元设置
alu_src = 1,将来自imm_gen的立即数路由到 ALU 的 operand_b 输入端,而不是 rs2_data。可用的操作与 R 型集合完全对应,但有两个显著区别:没有 SUBI(与立即数相减——使用带负立即数的 ADDI 可达到相同结果),并且移位立即数指令使用完整的 funct7 字段来编码移位类型,而不是作为寄存器标识符。 指令| funct3| funct7[5]| ALU 操作| 汇编语法| 行为 —|—|—|—|—|— ADDI| 000| —| ALU_ADD|addi rd, rs1, imm| rd = rs1 + imm SLLI| 001| 0| ALU_SLL|slli rd, rs1, shamt| rd = rs1 « shamt SLTI| 010| —| ALU_SLT|slti rd, rs1, imm| rd = (rs1 < imm) ? 1 : 0 (有符号) SLTIU| 011| —| ALU_SLTU|sltiu rd, rs1, imm| rd = (rs1 < imm) ? 1 : 0 (无符号) XORI| 100| —| ALU_XOR|xori rd, rs1, imm| rd = rs1 ⊕ imm SRLI| 101| 0| ALU_SRL|srli rd, rs1, shamt| rd = rs1 » shamt (逻辑) SRAI| 101| 1| ALU_SRA|srai rd, rs1, shamt| rd = rs1 »> shamt (算术) ORI| 110| —| ALU_OR|ori rd, rs1, imm| rd = rs1 | imm ANDI| 111| —| ALU_AND|andi rd, rs1, imm| rd = rs1 & imm 对于移位立即数指令 (SLLI, SRLI, SRAI),移位量 (shamt) 占据instr[24:20],这与 R 型编码中的 rs2 位域相同。funct7[5]位区分了 SRAI 和 SRLI,正如在 R 型中区分 SRA 和 SRL 一样。立即数生成器为所有 I 型指令产生 12 位符号扩展的值:imm = , instr[31:20]}——这意味着对于算术操作,立即数范围是 −2048 到 +2047,而由于 ALU 仅使用低 5 位,移位量实际上被限制在 0–31 之间。 ADDI 是典型 RISC-V 程序中最频繁使用的指令。它身兼三职:与立即数相加、相减(通过负立即数实现,如addi x4, x4, -1)以及寄存器移动(addi x3, x2, 0等价于mv x3, x2)。汇编伪指令li、mv和nop均编译为 ADDI 的变体。 来源:control.v,imm_gen.v,alu.v加载指令 (操作码 0x03)
加载指令将数据从内存读入寄存器。它们使用 I 型格式:12 位立即数经符号扩展后与 rs1 相加形成有效地址。控制单元激活
mem_read = 1和mem_to_reg = 1,将数据内存输出路由至写回多路选择器,而非 ALU 结果。funct3 字段选择访问宽度和符号扩展行为。 指令| funct3| 宽度| 符号扩展| 汇编语法| 行为 —|—|—|—|—|— LB| 000| 字节 (8 位)| 是|lb rd, offset(rs1)| rd = SignExt(mem[addr], 8) LH| 001| 半字 (16 位)| 是|lh rd, offset(rs1)| rd = SignExt(mem[addr], 16) LW| 010| 字 (32 位)| —|lw rd, offset(rs1)| rd = mem[addr] (完整字) LBU| 100| 字节 (8 位)| 否|lbu rd, offset(rs1)| rd = ZeroExt(mem[addr], 8) LHU| 101| 半字 (16 位)| 否|lhu rd, offset(rs1)| rd = ZeroExt(mem[addr], 16) 数据内存模块将可按字节寻址的存储实现为一个 4096 字节的数组 (reg [7:0] memory [0:4095])。对于 LB,所获取字节的符号位 (memory[byte_addr][7]) 被复制 24 次以填充高位。对于 LBU,高 24 位用零填充。LH 和 LHU 以小端序读取两个连续字节(低字节位于低地址)。LW 读取四个连续字节,将它们组装为{memory[addr+3], memory[addr+2], memory[addr+1], memory[addr]}。 来源:control.v,dmem.v存储指令 (操作码 0x23)
存储指令将数据从寄存器写入内存。它们使用 S 型格式,其中 12 位立即数被拆分为两个不连续的字段:高 7 位在
instr[31:25],低 5 位在instr[11:7](与 rd 字段位置重叠)。立即数生成器将其重新组装:imm = , instr[31:25], instr[11:7]}。控制单元激活mem_write = 1并设置reg_write = 0(存储操作绝不写回寄存器堆)。 指令| funct3| 宽度| 汇编语法| 行为 —|—|—|—|— SB| 000| 字节 (8 位)|sb rs2, offset(rs1)| mem[addr] = rs2[7:0] SH| 001| 半字 (16 位)|sh rs2, offset(rs1)| mem[addr] = rs2[7:0]; mem[addr+1] = rs2[15:8] SW| 010| 字 (32 位)|sw rs2, offset(rs1)| mem[addr..addr+3] = rs2[7:0..31:24] 存储按小端字节顺序写入数据——最低有效字节存入最低地址。数据内存的写端口接收rs2_data作为写入数据源,如在核心实例化中所见:.write_data(rs2_data)。仅修改相关的字节:SB 触及一个字节,SH 触及两个,SW 触及四个。 来源:control.v,dmem.v,imm_gen.v分支指令 (操作码 0x63)
分支指令执行条件控制转移。它们使用带有 13 位立即数的 B 型格式(始终为偶数,因此有效范围为 ±4 KiB)。立即数散布在指令中,其位排列较为复杂,立即数生成器将其重新组装为:
imm = , instr[31], instr[7], instr[30:25], instr[11:8], 1'b0}。分支单元 通过比较 rs1_data 和 rs2_data 来评估条件,并将结果馈入 PC 加法器的下一 PC 选择逻辑。 指令| funct3| 比较| 汇编语法| 分支成立条件 —|—|—|—|— BEQ| 000| 相等|beq rs1, rs2, offset| rs1 == rs2 BNE| 001| 不等|bne rs1, rs2, offset| rs1 ≠ rs2 BLT| 100| 有符号小于|blt rs1, rs2, offset| rs1 < rs2 (有符号) BGE| 101| 有符号大于等于|bge rs1, rs2, offset| rs1 ≥ rs2 (有符号) BLTU| 110| 无符号小于|bltu rs1, rs2, offset| rs1 < rs2 (无符号) BGEU| 111| 无符号大于等于|bgeu rs1, rs2, offset| rs1 ≥ rs2 (无符号) 控制单元为所有分支指令设置branch = 1和pc_src = PC_BRANCH。随后 PC 加法器进行评估:若branch_taken为真,下一 PC 变为pc + imm;否则,执行落到pc + 4。关键在于,分支单元直接从寄存器堆接收 rs1_data 和 rs2_data——而非 ALU 输出——因此分支条件的评估与 ALU 操作并行进行,从而实现单周期分支解析。 来源:control.v,branch_unit.v,imm_gen.v,pc_adder.v跳转指令
跳转指令执行无条件控制转移并保存返回地址。两者均将
pc + 4(下一条指令的地址)写入 rd,从而支持子程序返回。写回逻辑专门处理了这一点:write_back_data = jump ? pc_plus_4 : (mem_to_reg ? mem_read_data : alu_result)。JAL — 跳转并链接 (操作码 0x6F)
JAL 使用带有 21 位立即数的 J 型格式(始终为偶数,提供 ±1 MiB 的范围)。该立即数是所有格式中散布最为复杂的:
imm = , instr[31], instr[19:12], instr[20], instr[30:21], 1'b0}。控制单元设置jump = 1和pc_src = PC_BRANCH,使得当跳转信号有效时,PC 加法器计算pc_next = pc + imm。 字段| 位宽| 来源 —|—|— imm[20]| 1 位| instr[31] imm[19:12]| 8 位| instr[19:12] imm[11]| 1 位| instr[20] imm[10:1]| 10 位| instr[30:21] imm[0]| 1 位| 始终为 0 汇编语法:jal rd, offset→ rd = pc + 4,然后 pc = pc + offset。JALR — 跳转并链接寄存器 (操作码 0x67)
JALR 使用带有 12 位符号扩展立即数的 I 型格式。目标地址计算为
(rs1 + imm) & ~1——最低有效位始终被清零以确保对齐。控制单元设置pc_src = PC_JALR,这激活了 PC 加法器中的一条独立路径:pc_next = (rs1_data + imm) & ~32'b1。这是唯一使用PC_JALR下一 PC 路径的指令类型。 汇编语法:jalr rd, rs1, offset→ rd = pc + 4,然后 pc = (rs1 + offset) & ~1。 来源:control.v,imm_gen.v,pc_adder.v,riscv_core.v上位立即数指令
上位立即数指令分两步构建大型 32 位常量。它们使用 U 型格式,其中立即数占据指令的高 20 位,并左移 12 位——实际上将其放置在 32 位立即数值的第 31–12 位,低 12 位清零。
LUI — 加载上位立即数 (操作码 0x37)
LUI 将 20 位上位立即数放入 rd 的高 20 位,将低 12 位置零。立即数生成器产生:
imm = {instr[31:12], 12'b0}。控制单元设置alu_src = 1和alu_op = ALU_ADD,因此 ALU 计算rs1_data + imm。由于 LUI 不使用 rs1,operand_a 默认为 0(寄存器堆中的 x0 硬连线为零),结果即为0 + imm = imm——这正确地将上位立即数放入了 rd。 汇编语法:lui rd, upper_imm→ rd = upper_imm « 12。AUIPC — 将上位立即数加到 PC (操作码 0x17)
AUIPC 将上位立即数加到当前 PC 值上。这是唯一一条 ALU 的 operand_a 来自 PC 而非 rs1_data 的指令。核心通过一个专用多路选择器实现这一点:
assign alu_operand_a = (opcode == 7'b0010117) ? pc : rs1_data。使用了相同的alu_src = 1和alu_op = ALU_ADD配置,但以 PC 作为 operand_a 而非寄存器值。 汇编语法:auipc rd, upper_imm→ rd = pc + (upper_imm « 12)。 LUI 和 AUIPC 协同工作以构建任意 32 位地址。LUI 设置高 20 位,然后通过 ADDI 或 JALR 填充低 12 位。hello.s 示例演示了 LUI:lui x6, 0x12345将值 0x12345000 加载到寄存器 x6 中。 来源:control.v,imm_gen.v,riscv_core.vSYSTEM 指令 (操作码 0x73)
TinyRISCV 仅实现了一条 SYSTEM 指令——ECALL ——并将其重新用作停机信号 。当控制单元译码出操作码
0x73时,它不会发出任何控制信号(reg_write、mem_read、mem_write、branch 和 jump 均保持为 0)。核心的停机检测逻辑非常简单:assign halt = (opcode == 7'b1110011)。当 halt 被置位时,PC 寄存器冻结:else if (!halt) begin pc <= pc_next; end,从而有效地停止处理器。 所有三个示例程序均以ecall结束:
- 分享
TinyRISCV 实现了 RV32I 基础整数指令集 的一个重要子集——即 RISC-V 规范定义的基础 32 位指令架构。本参考文档编录了该处理器实际支持的每一条指令,将它们逐一映射到贯穿译码器、控制单元、ALU 和分支单元的硬件实现路径,并着重标明了少数被刻意省略的标准 RV32I 指令。理解本参考文档对于编写正确的汇编程序,以及在波形调试期间沿着处理器的数据通路追踪指令执行过程至关重要。
factorial.s:使用重复加法计算 5!,以ecall停机fibonacci.s:计算 10 个斐波那契数,以ecall停机hello.s:执行基础算术和 LUI,以ecall停机 来源:control.v,riscv_core.v,pc_register.v,factorial.s,fibonacci.s,hello.s指令执行流程
下图说明了每种指令类别如何流经处理器的数据通路。每条指令都遵循相同的高级路径——从指令内存取指、译码字段、生成控制信号、在 ALU 或分支单元中执行,以及可选的写回——但控制信号会激活不同的子路径。 WriteBack Memory Execute Decode Fetch rs1_data, rs2_data rs1_data, rs2_data imm imm branch_taken alu_result alu_result read_data write_back_data 指令内存 instr = memory[pc[11:2]] 译码器 opcode, rd, rs1, rs2, funct3, funct7 立即数生成器 I / S / B / U / J 格式 控制单元 reg_write, alu_src, alu_op, mem_read, mem_write, mem_to_reg, branch, jump, pc_src 寄存器堆 x0–x31 ALU ADD SUB AND OR XOR SLL SRL SRA SLT SLTU 分支单元 BEQ BNE BLT BGE BLTU BGEU 数据内存 4096 字节,可按字节寻址 写回多路选择器 jump → pc+4 mem_to_reg → mem_data default → alu_result PC 加法器 来源:riscv_core.v
未实现的 RV32I 指令
TinyRISCV 刻意省略了完整 RV32I 规范中的几条指令。这些省略反映了处理器的教学设计目标——在覆盖汇编编程练习最常用指令类型的同时,最大程度地降低复杂性。 指令| 操作码| 省略原因 —|—|— FENCE| 0x0F| 在没有缓存的单核设计中无需考虑内存排序问题 FENCE.I| 0x0F| 指令内存不可自我修改;无需流水线刷新 CSRRW| 0x73| 未实现 CSR;无特权级别 CSRRS| 0x73| 未实现 CSR;无特权级别 CSRRC| 0x73| 未实现 CSR;无特权级别 CSRRWI| 0x73| 未实现 CSR;无特权级别 CSRRSI| 0x73| 未实现 CSR;无特权级别 CSRRCI| 0x73| 未实现 CSR;无特权级别 EBREAK| 0x73| 无调试器集成;ECALL 作为唯一的停机机制 FENCE 指令是不必要的,因为 TinyRISCV 拥有单条顺序执行流水线,没有数据缓存或指令缓存——内存操作始终按程序顺序可见。CSR 指令被省略是因为处理器仅在机器模式下运行,除了停机机制外没有任何控制和状态寄存器。EBREAK 可以通过扩展 SYSTEM 操作码处理并增加 funct3 检查来添加,但在没有附加调试器的情况下它毫无用处。 来源:control.v
常用伪指令
RISC-V 汇编器支持将伪指令转换为真实硬件指令。它们并非独立的机器指令——而是汇编期的替换,旨在提高代码可读性。TinyRISCV 将它们作为底层真实指令来执行。 伪指令| 转换| 真实指令| 用法示例 —|—|—|—
mv rd, rs|addi rd, rs, 0| ADDI|mv x3, x2→addi x3, x2, 0li rd, imm|lui+addi序列| LUI + ADDI|li x1, 5→addi x1, x0, 5nop|addi x0, x0, 0| ADDI| 无操作 (写入 x0 被丢弃)j offset|jal x0, offset| JAL| 无链接的无条件跳转jal offset|jal x1, offset| JAL| 跳转并在 x1 中保存返回地址ret|jalr x0, x1, 0| JALR| 返回至保存的地址beqz rs1, offset|beq rs1, x0, offset| BEQ| 寄存器为零时分支bnez rs1, offset|bne rs1, x0, offset| BNE| 寄存器不为零时分支bgt rs1, rs2, offset|blt rs2, rs1, offset| BLT| 大于时分支 (有符号)ble rs1, rs2, offset|bge rs2, rs1, offset| BGE| 小于等于时分支 (有符号) factorial 和 fibonacci 程序大量使用li来加载常量,使用mv进行寄存器移动。例如,li x1, 5汇编为addi x1, x0, 5,因为立即数 5 可以容纳在 12 位内;更大的值将需要 LUI + ADDI 序列。 来源:factorial.s,fibonacci.s,regfile.v指令快速参考卡
下表提供了 TinyRISCV 中实现的每条指令的紧凑完整列表,按操作码排序,方便在汇编编程或波形调试期间快速查阅。 指令| 操作码| funct3| funct7[5]| 格式| rd| rs1| rs2/imm| ALU 操作 —|—|—|—|—|—|—|—|— ADD| 0x33| 000| 0| R| ✓| ✓| rs2| ADD SUB| 0x33| 000| 1| R| ✓| ✓| rs2| SUB SLL| 0x33| 001| 0| R| ✓| ✓| rs2| SLL SLT| 0x33| 010| 0| R| ✓| ✓| rs2| SLT SLTU| 0x33| 011| 0| R| ✓| ✓| rs2| SLTU XOR| 0x33| 100| 0| R| ✓| ✓| rs2| XOR SRL| 0x33| 101| 0| R| ✓| ✓| rs2| SRL SRA| 0x33| 101| 1| R| ✓| ✓| rs2| SRA OR| 0x33| 110| 0| R| ✓| ✓| rs2| OR AND| 0x33| 111| 0| R| ✓| ✓| rs2| AND ADDI| 0x13| 000| —| I| ✓| ✓| imm12| ADD SLLI| 0x13| 001| 0| I| ✓| ✓| shamt| SLL SLTI| 0x13| 010| —| I| ✓| ✓| imm12| SLT SLTIU| 0x13| 011| —| I| ✓| ✓| imm12| SLTU XORI| 0x13| 100| —| I| ✓| ✓| imm12| XOR SRLI| 0x13| 101| 0| I| ✓| ✓| shamt| SRL SRAI| 0x13| 101| 1| I| ✓| ✓| shamt| SRA ORI| 0x13| 110| —| I| ✓| ✓| imm12| OR ANDI| 0x13| 111| —| I| ✓| ✓| imm12| AND LB| 0x03| 000| —| I| ✓| ✓| imm12| ADD LH| 0x03| 001| —| I| ✓| ✓| imm12| ADD LW| 0x03| 010| —| I| ✓| ✓| imm12| ADD LBU| 0x03| 100| —| I| ✓| ✓| imm12| ADD LHU| 0x03| 101| —| I| ✓| ✓| imm12| ADD SB| 0x23| 000| —| S| ✗| ✓| rs2+imm| ADD SH| 0x23| 001| —| S| ✗| ✓| rs2+imm| ADD SW| 0x23| 010| —| S| ✗| ✓| rs2+imm| ADD BEQ| 0x63| 000| —| B| ✗| ✓| rs2| — BNE| 0x63| 001| —| B| ✗| ✓| rs2| — BLT| 0x63| 100| —| B| ✗| ✓| rs2| — BGE| 0x63| 101| —| B| ✗| ✓| rs2| — BLTU| 0x63| 110| —| B| ✗| ✓| rs2| — BGEU| 0x63| 111| —| B| ✗| ✓| rs2| — JAL| 0x6F| —| —| J| ✓| —| imm21| — JALR| 0x67| 000| —| I| ✓| ✓| imm12| ADD LUI| 0x37| —| —| U| ✓| —| imm20| ADD AUIPC| 0x17| —| —| U| ✓| —| imm20| ADD ECALL| 0x73| 000| —| I| ✗| —| —| — 来源:control.v,alu.v,branch_unit.v
-
- * 在完整指令集映射完成之后,下一步合乎逻辑的是了解每条指令激活的控制信号——请参阅 控制信号参考 以获取详细的信号级分解。关于实际使用,编写汇编测试程序 将指导你创建用于练习这些指令的程序,而仿真与波形调试 则向你展示如何逐周期追踪它们的执行过程。 划线 写想法 提问
-
在Github README中添加Zread徽章添加徽章
来源
RV32I 指令参考
-
rtl
-
decoder
- decoder.v
-
core
- control.v
- pc_adder.v
- riscv_core.v
- pc_register.v
-
datapath
- alu.v
- imm_gen.v
- branch_unit.v
- regfile.v
-
memory
- dmem.v
-
-
programs/asm
- factorial.s
- fibonacci.s
-
hello.s
控制信号参考
⌘K
-
- 分享
TinyRISCV 处理器采用集中式控制信号架构 ,由单个组合逻辑
control模块将指令的 opcode、funct3 和 funct7 字段解码为一组离散信号,以统筹所有的数据通路多路选择器、寄存器堆写使能、存储器访问以及 PC 下一值的选择。本文档编录了每一个控制信号、其编码、其在内核中的传播路径,以及针对每种 RV32I 指令类型发出的精确信号组合——旨在为仿真波形调试信号异常或通过新指令扩展 ISA 时提供权威的查阅依据。信号生成架构
控制信号源自一个两级流水线:解码器 从 32 位指令字中提取原始位字段,控制单元 将这些字段映射为实际的控制信号。这种关注点分离意味着解码器是一个纯布线层(连续赋值),而控制单元则将所有决策逻辑封装在一个带有默认安全输出的单一
always @(*)块中。 Datapath Consumers Control Unit Decoder instr[31:0] opcode[6:0] funct3[2:0] funct7[6:0] Combinational Decision Logic 8 Control Signals reg_write → RegFile alu_src → ALU B Mux mem_read / mem_write → DMem mem_to_reg / jump → WB Mux branch / jump / pc_src → PC Adder alu_op → ALU 解码器的字段提取遵循标准的 RV32I 编码:从第 [6:0] 位提取opcode,[11:7] 位提取rd,[14:12] 位提取funct3,[19:15] 位提取rs1,[24:20] 位提取rs2,[31:25] 位提取funct7。控制单元仅消耗opcode、funct3和funct7——寄存器地址直接路由至寄存器堆和立即数生成器,无需控制干预。 来源:decoder.v, control.v完整信号目录
控制单元发出九个不同的信号 (七个 1 位标志,一个 4 位 ALU 操作码,以及一个 2 位 PC 源选择器)。所有信号在组合块顶部、
case (opcode)语句之前,均默认处于“非活跃”或“无操作”状态,这意味着任何无法识别的 opcode 都会产生一个安全的 NOP——无寄存器写入、无存储器访问,PC 自增 4。 信号| 位宽| 默认值| 用途| 直接消费者 —|—|—|—|—reg_write| 1 位|0| 使能寄存器堆写入|regfile.write_enablemem_read| 1 位|0| 启动数据存储器读取|dmem.mem_readmem_write| 1 位|0| 启动数据存储器写入|dmem.mem_writealu_src| 1 位|0| 选择 ALU 操作数 B 的来源|riscv_core中的alu_operand_b多路选择器mem_to_reg| 1 位|0| 选择写回数据:ALU 结果还是存储器数据|riscv_core中的write_back_data多路选择器branch| 1 位|0| 指示条件分支指令|pc_adder(与branch_taken组合)jump| 1 位|0| 指示无条件跳转(JAL/JALR)|pc_adder+write_back_data多路选择器alu_op| 4 位|0000(ADD)| 选择 ALU 操作|alu.alu_oppc_src| 2 位|00(PC+4)| 选择下一 PC 计算模式|pc_adder.pc_src尽管branch和jump信号都会影响 PC 流向,但它们的作用截然不同。branch控制来自分支单元的 条件 branch_taken 结果,而jump则无条件强制选择 PC 偏移路径, 并 选择pc+4作为链接寄存器的写回值。对于单条指令而言,它们绝不会同时处于活跃状态。 来源:control.v, riscv_core.vALU 操作编码
alu_op信号是一个 4 位代码,直接驱动 ALU 的操作多路选择器。该编码在控制单元和 ALU 模块中均被定义为localparam常量——它们必须保持同步。从 RV32I 的funct3/funct7字段到alu_op的映射,是 R 型和 I 型 opcode 处理器的主要职责。alu_op[3:0]| 助记符| 操作| R 型触发条件| I 型触发条件 —|—|—|—|—0000| ADD|a + b|funct3=000, funct7[5]=0|funct3=0000001| SUB|a - b|funct3=000, funct7[5]=1| —0010| AND|a & b|funct3=111|funct3=1110011| OR|a | b|funct3=110|funct3=1100100| XOR|a ^ b|funct3=100|funct3=1000101| SLL|a << b[4:0]|funct3=001|funct3=0010110| SRL|a >> b[4:0](逻辑)|funct3=101, funct7[5]=0|funct3=101, funct7[5]=00111| SRA|a >>> b[4:0](算术)|funct3=101, funct7[5]=1|funct3=101, funct7[5]=11000| SLT|(signed)a < (signed)b ? 1 : 0|funct3=010|funct3=0101001| SLTU|(unsigned)a < (unsigned)b ? 1 : 0|funct3=011|funct3=011funct7[5] 消歧义 位仅在funct3=000(ADD 与 SUB)和funct3=101(SRL 与 SRA)时被参考。对于所有其他的 funct3 值,控制单元会忽略 funct7——ALU 操作仅由 funct3 决定。这与 RV32I 规范一致,在规范中,funct7 用于区分共享同一 funct3 代码的操作变体。 来源:control.v, alu.vPC 源编码
pc_src信号选择pc_adder模块执行哪种计算来确定下一个程序计数器的值。它是一个 2 位代码,与branch和jump信号协同工作,以解析最终的pc_next输出。pc_src[1:0]| 助记符| 行为| 使用者 —|—|—|—00| PC_PLUS4|pc_next = pc + 4| 所有非分支、非跳转指令的默认值01| PC_BRANCH|pc_next = branch_taken || jump ? pc + imm : pc + 4| 分支指令与 JAL10| PC_JALR|pc_next = (rs1_data + imm) & ~1| JALR11| (未使用)| 回退到默认值:pc + 4| — 当pc_src = PC_BRANCH时,实际的分支解析是一个两级门控 :控制单元断言branch=1(条件)或jump=1(无条件),而pc_adder检查branch_taken(来自分支单元)或jump来决定是选择pc+imm还是pc+4。对于 JAL,jump=1保证了走偏移路径。对于条件分支,分支单元的比较结果(branch_taken)充当最终仲裁者。 来源:control.v, pc_adder.vOpcode 到信号的映射
这是核心参考表,展示了每种 RV32I opcode 类型产生的确切控制信号值。每一行代表控制单元组合逻辑中的一个
case分支。行中未列出的信号值保持其默认状态(全零,alu_op=ADD,pc_src=PC_PLUS4)。 Opcode| 助记符|reg_write|mem_read|mem_write|alu_src|mem_to_reg|branch|jump|alu_op|pc_src—|—|—|—|—|—|—|—|—|—|—0110011| R 型| 1| 0| 0| 0| 0| 0| 0| funct3/7|000010011| I 型 ALU| 1| 0| 0| 1| 0| 0| 0| funct3/7|000110111| LUI| 1| 0| 0| 1| 0| 0| 0| ADD|000010111| AUIPC| 1| 0| 0| 1| 0| 0| 0| ADD|000000011| LOAD| 1| 1| 0| 1| 1| 0| 0| ADD|000100011| STORE| 0| 0| 1| 1| 0| 0| 0| ADD|001100011| BRANCH| 0| 0| 0| 0| 0| 1| 0| ADD| 011101111| JAL| 1| 0| 0| 0| 0| 0| 1| ADD| 011100111| JALR| 1| 0| 0| 1| 0| 0| 1| ADD| 101110011| SYSTEM| 0| 0| 0| 0| 0| 0| 0| ADD|00从该表中可以得出关键模式:alu_src在所有使用立即数作为 ALU 第二操作数的指令类型中均被置为有效(I 型、LUI、AUIPC、LOAD、STORE、JALR)。mem_to_reg为 LOAD 指令所独有——这是唯一一种写回数据来自存储器而非 ALU 的指令。reg_write仅在 STORE、BRANCH 和 SYSTEM 指令中被置为无效——这三种指令类型不产生寄存器结果。 来源:control.v信号传播与多路选择逻辑
虽然控制单元发出规范化的信号值,但
riscv_core中的两个关键多路选择决策在原始控制信号 之上 叠加了额外的逻辑。理解这些组合路径对于波形调试至关重要,因为在仿真中观察到的实际多路选择线可能与控制单元的输出不同。ALU 操作数 A 选择
ALU 的操作数 A 由一个隐式多路选择器选择,该选择器不受专用控制信号控制。相反,内核直接比较 opcode: Copy code alu_operand_a = (opcode == OP_AUIPC) ? pc : rs1_data 这意味着对于 AUIPC 指令,ALU 接收当前 PC 作为操作数 A(同时
alu_src=1将高位置立即数作为操作数 B 送入),计算PC + imm以产生 PC 相对地址。对于所有其他指令,操作数 A 来自寄存器堆的读取端口 1。此逻辑位于控制单元之外——它是riscv_core中硬连线的 opcode 比较逻辑。 来源:riscv_core.v写回数据选择
写回多路选择器是一个三路选择器 ,由
jump和mem_to_reg组合控制: Copy code write_back_data = jump ? pc_plus_4 : (mem_to_reg ? mem_read_data : alu_result)jump|mem_to_reg| 写回来源| 指令类型 —|—|—|— 1| X|pc + 4(返回地址)| JAL, JALR 0| 1|mem_read_data| LOAD 0| 0|alu_result| R 型, I 型, LUI, AUIPC 在此多路选择器中,jump信号具有最高优先级——当其有效时,mem_to_reg将被忽略。这在架构上是正确的,因为跳转指令总是将pc+4(返回地址)写入rd,且没有哪条跳转指令同时是存储器加载指令。ALU 操作数 B 选择
alu_src信号直接控制一个 2 选 1 多路选择器: Copy code alu_operand_b = alu_src ? imm : rs2_dataalu_src| 操作数 B 来源| 指令类型 —|—|— 0|rs2_data(寄存器)| R 型, BRANCH 1|imm(立即数)| I 型, LUI, AUIPC, LOAD, STORE, JALR 请注意,BRANCH 指令的alu_src=0——它们不会将立即数送入 ALU。分支偏移量仅供pc_adder模块使用,而分支单元则直接比较rs1_data和rs2_data。 来源:riscv_core.v分支解析信号流
条件分支机制需要控制单元、分支单元和 PC 加法器三个模块的协调,这是处理器中最复杂的信号路径。下图追踪了条件分支指令的完整解析链: Register FilePC AdderBranch UnitControl UnitRegister FilePC AdderBranch UnitControl UnitBRANCH opcode detectedEvaluates funct3 comparisonalt[branch_taken = 1(condition met)][branch_taken = 0(condition not met)]branch=1, pc_src=PC_BRANCHrs1data, rs2_datars1_data (unused for branch)branch_taken = 1pc_next = pc + imm (offset taken)branch_taken = 0pc_next = pc + 4 (fall through) 关键见解在于控制单元并不决定分支是否被采纳 ——它仅通过设置
branch=1和pc_src=PC_BRANCH来 _使能 分支路径。实际的采纳/不采纳决策被委托给分支单元的branch_taken输出,PC 加法器将其作为条件使用。这种分离保持了控制单元的简洁,并允许分支单元封装所有的比较语义(有符号、无符号、相等)。 来源:control.v, branch_unit.v, pc_adder.vLUI 与 AUIPC 信号交互
LUI 和 AUIPC 从控制单元接收相同的控制信号值(
reg_write=1, alu_src=1, alu_op=ADD),但由于riscv_core中 ALU 操作数 A 的选择逻辑不同,它们产生了根本不同的结果。这是控制单元之外的多路选择器在没有任何控制信号变化的情况下,产生指令级行为差异的唯一情况。 方面| LUI (0110111)| AUIPC (0010111) —|—|—alu_src| 1| 1alu_op| ADD| ADDalu_operand_a|rs1_data(= x0 = 0)|pcalu_operand_b|imm(高 20 位,左移 12 位)|imm(高 20 位,左移 12 位) 结果|0 + imm = imm|pc + imm用途| 加载高位立即数| PC 相对高位立即数 对于 LUI,寄存器堆的读取端口 1 返回零(因为rs1通常是 x0),因此0 + upper_imm = upper_imm有效地将 20 位立即数加载到目标寄存器的高半部分。对于 AUIPC,操作数 A 的多路选择器用pc覆盖了rs1_data,从而产生 PC 相对地址。imm_gen模块为两种 opcode 生成相同的位模式{instr[31:12], 12'b0}——区分完全在于操作数 A 的多路选择器。 来源:control.v, riscv_core.v, imm_gen.vSYSTEM Opcode 与停机行为
SYSTEM opcode(
1110011)从控制单元接收全默认信号 ——无寄存器写入、无存储器访问、除了默认的 ADD 之外无 ALU 操作,且pc_src=PC_PLUS4。然而,riscv_core直接将该 opcode 用于一个特殊目的:停机信号 。 Copy code halt = (opcode == 7’b1110011) 当halt被置为有效时,pc_register模块停止更新,将处理器冻结在原地。这是 TinyRISCV 的程序终止机制——ECALL 指令(或任何 SYSTEM 类指令)会触发停机。请注意,与完整的 RISC-V 特权架构相比,这是一种简化,后者使用 SYSTEM 指令进行 CSR 访问和环境调用。在 TinyRISCV 中,所有 SYSTEM 指令都被视为单一的停机事件,不再通过 funct3 或 funct7 进行区分。 来源:control.v, riscv_core.vFunct3 到 ALU 操作的推导
对于 R 型和 I 型指令,控制单元执行二次
case (funct3)分发以确定 ALU 操作。下表展示了完整的映射,包括适用的 funct7[5] 消歧义逻辑。funct3| R 型操作| I 型操作| funct7[5] 检查| R 型alu_op| I 型alu_op—|—|—|—|—|—000| ADD/SUB| ADDI| 是 (0→ADD, 1→SUB)| ADD 或 SUB| ADD001| SLL| SLLI| 否| SLL| SLL010| SLT| SLTI| 否| SLT| SLT011| SLTU| SLTIU| 否| SLTU| SLTU100| XOR| XORI| 否| XOR| XOR101| SRL/SRA| SRLI/SRAI| 是 (0→SRL, 1→SRA)| SRL 或 SRA| SRL 或 SRA110| OR| ORI| 否| OR| OR111| AND| ANDI| 否| AND| AND funct3 分发逻辑对于 R 型和 I 型 opcode 是完全相同的 ——两个分支中出现了相同的case结构。唯一的区别是 I 型的funct3=000总是产生 ADD(RV32I 中没有 SUB 立即数),而 R 型必须检查 funct7[5] 以区分 ADD 和 SUB。 来源:control.v信号波形调试快速参考
在 GTKWave 或其他波形查看器中追踪控制信号时,请使用以下检查表来诊断常见问题。所有信号均可作为
riscv_core测试台实例下的分层路径进行访问。 症状| 首要检查信号| 预期有效状态| 常见接线错误 —|—|—|— ALU 操作后寄存器未写入|reg_write| R/I 型为1| 指令被误判为 STORE ALU 结果错误|alu_op[3:0]| 匹配上文的 funct3 表| SUB/SRA 未检查 funct7[5] 使用了立即数而非寄存器|alu_src| R 型为0| Opcode 被解码为 I 型 存储器数据未加载到寄存器|mem_to_reg| LOAD 为1|mem_read未与其一起置为有效 预期分支未采纳|branch_taken(branch_unit 输出)| 条件为真时为1|branch控制信号未置为有效 跳转写入了错误的返回地址|jump| JAL/JALR 为1|pc_src必须分别为01或10AUIPC 返回立即数而非 PC+offset| core 中的alu_operand_a| 应等于pc| AUIPC 多路选择器的 opcode 比较失败 处理器意外挂起|halt| 正常执行期间为0| 过早执行了 SYSTEM 指令 详细的波形分析方法论,请参阅 仿真与波形调试 。 来源:control.v, riscv_core.v扩展控制单元
当添加新的 RV32I 指令(如 M 扩展的乘除法或 F 扩展的浮点)时,得益于其默认安全模式 ,控制单元的架构使得扩展变得非常直接。新的 opcode 只需添加一个新的
case分支,而新的 ALU 操作只需在localparam定义和 ALU 的操作多路选择器中添加条目。需要保持的关键不变量是,每个信号都必须在 case 语句 之前 被赋予一个默认值,这样任何未处理的 opcode 都会自动产生一个安全的 NOP。 扩展工作流遵循三个步骤:(1) 在control.v中为 opcode 及任何新的alu_op代码定义新的localparam,并在alu.v中提供匹配的定义;(2) 添加一个新的case分支,设置所需的信号组合;(3) 更新 ALU 的case(alu_op)以实现新操作。对于需要新数据通路多路选择(例如第三个写回源)的指令,riscv_core.v中相应的多路选择逻辑也必须使用控制单元输出的新控制信号进行扩展。 关于此集中式控制设计背后的架构考量,请参阅 设计决策与权衡 。关于驱动这些信号的完整指令集,请参阅 RV32I 指令参考 。 划线 写想法 提问
- 分享
TinyRISCV 处理器采用集中式控制信号架构 ,由单个组合逻辑
-
在Github README中添加Zread徽章添加徽章
来源
控制信号参考
-
rtl
-
decoder
- decoder.v
-
core
- control.v
- riscv_core.v
- pc_adder.v
-
datapath
- alu.v
- branch_unit.v
-
imm_gen.v
内存映射与地址布局
⌘K
-
-
- 分享
内存映射 定义了处理器的地址空间如何划分——哪些地址对应哪些物理存储,以及软件读写特定位置时会发生什么。在 TinyRISCV 中,内存映射由两个基本设计选择决定:采用独立指令内存和数据内存的哈佛架构 ,以及以扁平且紧耦合的地址空间为代价来保持硬件简洁的最小化地址解码 。在编写加载或存储数据的汇编程序之前,理解该映射至关重要,同时它也解释了为什么相同的地址
0x00000000可以指代两个完全不同的物理内存,这取决于处理器核心是在取指还是在执行加载操作。 来源: imem.v, dmem.v, riscv_core.v, linker.ld哈佛架构与物理内存分离
TinyRISCV 采用哈佛架构 ,这意味着指令取指和数据访问通过独立的路径访问独立的物理内存。这不是基于地址的区分,而是结构性 的区分。当处理器核心取指时,PC(程序计数器)直接驱动
imem模块;当处理器核心执行加载或存储时,ALU(算术逻辑单元)结果直接驱动dmem模块。没有共享总线,没有仲裁,也没有同时存放代码和数据的单一内存。其实际后果很简单:从处理器的角度来看,指令内存是只读的(它在仿真开始前通过$readmemh加载),而数据内存在运行时是完全可读写的。 instr[31:0] read_data[31:0] write_data[31:0] PC Register addr[31:0] Instruction Memory imem.v 1024 × 32-bit words ALU Result addr[31:0] Data Memory dmem.v 4096 × 8-bit bytes RISC-V Core 来源: riscv_core.v, riscv_core.v, imem.v, dmem.v完整地址映射
下表总结了 TinyRISCV 的整个可寻址空间。由于地址解码仅使用完整 32 位地址的一个子集,有效地址范围非常紧凑——每块内存恰好跨越 4 KB,高位地址被硬件直接忽略。 区域| 基地址| 结束地址| 大小| 访问权限| 物理存储| 使用的地址位 —|—|—|—|—|—|— 指令内存|
0x00000000|0x00000FFF| 4 KB| 只读| 1024 × 32位字|addr[11:2](字索引) 数据内存|0x00000000|0x00000FFF| 4 KB| 读 / 写| 4096 × 8位字节|addr[11:0](字节索引) 由于 TinyRISCV 缺少地址解码逻辑,只要 32 位地址的低 12 位落在0x000–0xFFF范围内,数据内存就会响应 任何 此类地址。写入地址0xDEAD_BEEF会将数据存储在数据内存内偏移量为0xEFf的字节处——高 20 位会被静默丢弃。这意味着不存在触发故障的“未映射”区域;每个地址都是有效的。 数据内存范围上的星号表示,虽然架构文档在概念上将数据内存的起始位置设定为0x10000000,但实际的 RTL 实现并未强制这一点——链接脚本将.text和.data均放置在地址0x00000000,而硬件仅使用地址的相关低位。 Copy code Address Content ────────────── ──────────────────────────── 0x0000_0000 ┌──────────────────────────────┐ │ │ │ Instruction Memory (IMEM) │ ← PC 驱动此路径 │ 1024 words × 4 bytes │ │ = 4096 bytes (4 KB) │ │ │ 0x0000_0FFF └──────────────────────────────┘ 0x0000_0000 ┌──────────────────────────────┐ │ │ │ Data Memory (DMEM) │ ← ALU 结果驱动此路径 │ 4096 bytes (4 KB) │ │ │ 0x0000_0FFF └──────────────────────────────┘ Note: IMEM 和 DMEM 占用重叠的地址范围, 但在物理上是独立的内存。 来源: imem.v, dmem.v, linker.ld, architecture_zh.md指令内存寻址
指令内存被实现为一个包含 1024 个条目 的寄存器数组,每个条目宽 32 位。处理器核心每个时钟周期通过向
imem提供当前 PC 来取一条指令,imem随后返回该位置的 32 位字。关键细节在于 32 位 PC 地址如何转换为字索引: VERILOG Copy code reg [31:0] memory [0:1023]; // 1024 个字 assign instr = memory[addr[11:2]]; // 位 11:2 构成字索引 地址的[11:2]位构成 10 位字索引 (2¹⁰ = 1024 个条目),而[1:0]位被丢弃,因为 RV32I 指令始终是 32 位对齐 的——任何有效 PC 的最低两位始终为00。[31:12]位被完全忽略,这意味着 4 KB 的指令内存在 32 位地址空间中每 4 KB 边界就会重复一次。实际上,复位后 PC 总是从0x00000000开始并按 4 递增,因此永远不会遇到这种别名现象。 地址组成部分| 位| 用途 —|—|— 字索引|[11:2]| 选择 1024 个指令字之一 字节偏移|[1:0]| 对齐指令始终为00(忽略) 高位|[31:12]| 硬件未使用(无地址解码) 指令内存通过$readmemh("program.hex", memory)在仿真开始时初始化一次,该操作加载由编译脚本生成的 hex 文件。加载后,该内存实际上是只读 的——没有写端口,也不可能实现自修改代码。 来源: imem.v, pc_register.v, compile.sh数据内存寻址
数据内存被实现为一个包含 4096 个条目 的寄存器数组,每个条目宽 8 位(按字节寻址)。与指令内存不同,数据内存同时支持读和写,并且它处理子字访问 ——字节(8 位)、半字(16 位)和字(32 位)——由加载/存储指令的
funct3字段控制。 VERILOG Copy code reg [7:0] memory [0:4095]; // 4096 个字节 wire [11:0] byte_addr = addr[11:0]; // 位 11:0 构成字节索引 ALU 结果的[11:0]位构成 12 位字节索引 (2¹² = 4096 字节),而[31:12]位被丢弃。数据内存地址来自 ALU 结果 ——对于加载和存储,均计算为rs1_data + immediate——而非来自 PC。加载操作(读)
指令|
funct3| 宽度| 符号扩展| 行为 —|—|—|—|—LB|000| 1 字节| 有符号| 字节符号扩展至 32 位LH|001| 2 字节| 有符号| 半字符号扩展至 32 位LW|010| 4 字节| 不适用| 完整 32 位字LBU|100| 1 字节| 无符号| 字节零扩展至 32 位LHU|101| 2 字节| 无符号| 半字零扩展至 32 位存储操作(写)
指令|
funct3| 宽度| 行为 —|—|—|—SB|000| 1 字节| 将write_data[7:0]写入byte_addrSH|001| 2 字节| 将write_data[15:8]和write_data[7:0]写入连续字节SW|010| 4 字节| 按小端顺序写入全部四个字节 数据内存采用小端 字节顺序,与 RISC-V 规范一致。对于字节地址0x100处的字存储,布局为:memory[0x100]← 字节 0 (LSB),memory[0x101]← 字节 1,memory[0x102]← 字节 2,memory[0x103]← 字节 3 (MSB)。 来源: dmem.v, riscv_core.v链接脚本如何连接软件与硬件
链接脚本
linker.ld是你编写的软件与硬件内存映射之间的桥梁。它告诉汇编器和链接器在地址空间中的何处放置编译程序的各个节: Copy code SECTIONS { . = 0x00000000; ← 位置计数器从地址 0 开始 .text : { *(.text) } ← 代码节位于 0x00000000 .data : { *(.data) } ← 数据节紧跟在 .text 之后 .bss : { *(.bss) } ← BSS 节紧跟在 .data 之后 } 因为 TinyRISCV 采用哈佛架构,即使链接器为.text节(代码)和.data节(数据)分配了从0x00000000开始的连续地址,它们也驻留在物理上独立的内存 中。.text的内容被提取到program.hex中,并通过$readmemh加载到指令内存,而如果启动代码将.data和.bss的初始值复制到数据内存中,它们将被加载到数据内存。 当前的链接脚本将.data紧接在.text之后放置在连续地址上(例如,如果.text是 24 字节,则.data从0x00000018开始)。然而,数据内存的字节索引仅使用addr[11:0],指令内存仅使用addr[11:2]。如果程序的数据地址与指令地址重叠,哈佛架构的分离特性确保它们仍然访问正确的物理内存——但你必须意识到,数据内存不会 自动包含.data变量的初始值。需要运行时复制例程将数据内存从 hex 文件中进行初始化。 对于本仓库中的示例程序(hello.s,factorial.s,fibonacci.s),这不是问题,因为它们仅使用基于寄存器的计算,没有.data节——所有值都是通过立即数指令(如li,其扩展为ADDI或LUI+ADDI)加载的。 来源: linker.ld, compile.sh, hello.s, factorial.s, fibonacci.s地址转换总结:从 32 位地址到物理位置
下图精确追踪了 32 位地址如何针对指令取指和数据访问转换为物理内存位置。这是理解硬件行为最重要的结论。 Instruction Fetch (PC → IMEM) Data Access (ALU Result → DMEM) LB/LBU (byte) LH/LHU (half) LW (word) SB (byte) SH (half) SW (word) 32-bit Address (PC or ALU Result) Access Type? Extract bits [11:2] → 10-bit word index Extract bits [11:0] → 12-bit byte index memory[word_index] → 32-bit instruction funct3 determines access width Read 1 byte at byte_addr Read 2 bytes at byte_addr, byte_addr+1 Read 4 bytes at byte_addr..byte_addr+3 Write 1 byte at byte_addr Write 2 bytes at byte_addr, byte_addr+1 Write 4 bytes at byte_addr..byte_addr+3 参数| 指令内存| 数据内存 —|—|— 存储类型|
reg [31:0] memory [0:1023]|reg [7:0] memory [0:4095]总容量| 4 KB (1024 × 4 字节)| 4 KB (4096 × 1 字节) 地址来源| PC 寄存器| ALU 结果 使用的地址位|[11:2](10 位)|[11:0](12 位) 可寻址单元| 字 (32 位)| 字节 (8 位) 读行为| 组合逻辑 (即时)| 组合逻辑 (即时) 写行为| 不可写| 时序逻辑 (受时钟控制) 初始化| 在 0 时刻通过$readmemh初始化| 未初始化 (全为x) 来源: imem.v, dmem.v对程序员的实际影响
为 TinyRISCV 编写汇编程序时,其内存映射带来了一些与完整 RISC-V 系统不同的限制和约定。 默认无栈。 典型的 RISC-V 程序使用
x2(sp) 作为指向数据内存某个区域的栈指针。在 TinyRISCV 中,你必须手动将栈指针初始化为数据内存范围内的地址。常见的做法是将sp设置为0x00001000(数据内存末尾的后一个地址)并让栈向下增长,或者简单地使用0x00000F00以留出一些空间。因为数据内存仅使用addr[11:0],无论高位是什么,有效的栈地址将是0xF00。 无内存映射 I/O。 映射中没有 UART、定时器或外设地址。观察程序输出的唯一方法是通过仿真结束时的寄存器文件状态,或者通过 GTKWave 中的波形跟踪。ECALL指令会停止处理器(操作码7'b1110011触发halt信号),但它不会陷入操作系统——没有陷入向量,没有 CSR,也没有特权模式。 数据内存初始状态未定义。 与指令内存(从program.hex加载)不同,数据内存在仿真开始时包含未知值 (x)。任何先写入前就从数据内存读取的程序都将读取到未定义的值。这就是本仓库中所有示例程序仅使用立即数到寄存器操作的原因。 无地址越界错误检测。 由于高位地址被忽略,没有机制来检测越界访问。对地址0xFFFF_FFFC的存储将静默地写入数据内存中偏移量为0xFFC的字节。从地址0x0000_1000取指将由于字索引别名(0x1000的[11:2]位为0x000)而读取memory[0]。这对教学处理器来说可以接受,但在生产系统中将是一个漏洞。 来源: riscv_core.v, pc_register.v, control.v, architecture_zh.md下一步
现在你已经了解了地址如何映射到物理内存,下一步合乎逻辑的做法是将此知识付诸实践,编写编写汇编测试程序 ,在数据内存范围内正确使用加载和存储指令。若要深入了解各个内存模块的实现,请参阅指令内存 和数据内存 。要了解 PC 如何生成驱动指令取指的地址,请参阅 PC 寄存器 和 PC 加法器与下一 PC 选择 。 划线 写想法 提问
- 分享
内存映射 定义了处理器的地址空间如何划分——哪些地址对应哪些物理存储,以及软件读写特定位置时会发生什么。在 TinyRISCV 中,内存映射由两个基本设计选择决定:采用独立指令内存和数据内存的哈佛架构 ,以及以扁平且紧耦合的地址空间为代价来保持硬件简洁的最小化地址解码 。在编写加载或存储数据的汇编程序之前,理解该映射至关重要,同时它也解释了为什么相同的地址
-
在Github README中添加Zread徽章添加徽章
来源
内存映射与地址布局
-
rtl
-
memory
- imem.v
- dmem.v
-
core
- riscv_core.v
- pc_register.v
- control.v
-
-
programs
- linker.ld
- compile.sh
-
asm
- hello.s
- factorial.s
- fibonacci.s
-
docs
-
architecture_zh.md
编写汇编测试程序
⌘K
-
-
- 分享
为 TinyRISCV 编写汇编测试程序是验证处理器正确性的主要机制。与拥有丰富框架和断言的高级软件测试不同,测试裸机处理器要求你将 激励 和 预期结果 编码为原始机器指令,然后通过仿真波形观察寄存器和内存状态。本页面提供了一份系统的指南,用于编写有效的测试程序——从理解执行环境到构建全面的指令覆盖测试套件。
执行环境约束
在编写任何一条指令之前,你必须内化定义程序能做什么和不能做什么的硬件边界。TinyRISCV 是一款单周期哈佛架构处理器,具有独立的指令存储器和数据存储器,这意味着你的代码和数据占据着具有不同特性的独立地址空间。 属性| 指令存储器| 数据存储器 —|—|— 基地址|
0x00000000|0x10000000(高位被掩码) 大小| 4 KB (1024 × 32位字)| 4 KB (4096字节) 寻址方式| 字对齐 (addr[11:2])| 字节寻址 (addr[11:0]) 访问权限| 只读(取指)| 读/写(加载/存储) 加载方式|$readmemh("program.hex", memory)| 复位时未初始化 最大程序大小| ~1024条指令| — 三大约束主导着程序设计。第一 ,指令存储器是按字索引的——硬件提取addr[11:2]来索引这1024个条目的数组,这意味着无论你提供什么地址,每次指令取指本质上都是字对齐的。第二 ,数据存储器按字节寻址且为小端序;向地址0x10000000执行SW操作会将字节[31:24]写入偏移量 3,[23:16]写入偏移量 2,[15:8]写入偏移量 1,[7:0]写入偏移量 0。第三 ,程序计数器复位到0x00000000,你的_start标签必须解析到该地址——链接脚本通过将.text放置在起始地址来强制执行这一点。 停机机制 尤为重要:控制单元通过匹配操作码7'b1110011来检测ecall,并置位halt信号,从而冻结 PC 寄存器。如果没有ecall,处理器将无限期执行(直到测试平台在 1000 ns 时超时),这使得ecall成为每个测试程序中唯一必需的指令。 来源:imem.v, dmem.v, linker.ld, riscv_core.v, pc_register.v汇编程序结构
每个 TinyRISCV 测试程序都遵循源自链接脚本和处理器复位行为的固定骨架结构。
.section .text伪操作将代码放入文本段,而.globl _start导出入口点,以便链接器能将其解析到地址0x00000000。 ASSEMBLY Copy code .section .text .globl _start _start: li x1,li x2, — 执行:运行被测指令 —
x3, x1, x2 # --- 验证:将结果存储到数据内存以供检查 --- li x10, 0x10000000 sw x3, 0(x10) # --- 终止:停机处理器 --- ecall 三阶段模式——**设置** 、**执行** 、**验证** ——反映了适用于寄存器级观察的经典单元测试方法。代码库中现有的程序以不同的复杂程度演示了这种模式。`hello.s` 是最简单的实例:它加载两个立即数,执行算术运算,然后停机。`fibonacci.s` 通过添加循环计数器和迭代计算对此进行了扩展。`factorial.s` 则更进一步,由于 RV32I 基础 ISA 缺少硬件乘法指令,它通过嵌套循环实现了软件乘法。 `li`(加载立即数)伪指令会扩展为单条 `ADDI`(适用于适合 12 位的小有符号值)或 `LUI` \+ `ADDI` 组合(用于更大的值)。当专门测试 `LUI` 时,请使用显式的 `lui x1, 0x12345` 形式,以避免汇编器将其优化为不同的编码。 来源:[hello.s](/programs/asm/hello.s#L1-L13), [fibonacci.s](/programs/asm/fibonacci.s#L1-L19), [factorial.s](/programs/asm/factorial.s#L1-L27), [linker.ld](/programs/linker.ld#L1-L8) ## 构建流水线 将汇编源代码转换为可加载的内存镜像需要一个三阶段的工具链流水线。理解每个阶段对于诊断编译失败和解释输出至关重要。 riscv32-unknown-elf-as -march=rv32i -mabi=ilp32 riscv32-unknown-elf-ld -T linker.ld riscv32-unknown-elf-objcopy -O verilog $readmemh `foo.s` 汇编源文件 `foo.o` 可重定位目标文件 `foo.elf` 链接后的ELF文件 `foo.hex` Verilog十六进制文件 指令存储器 1024 × 32位字 每个阶段都有不同的目的。**汇编器** (`as`)将助记符翻译成机器码,生成带有未解析符号引用的可重定位目标文件。**链接器** (`ld`)根据链接脚本解析符号——关键是将 `.text` 放置在地址 `0x00000000`——并生成完整的 ELF 二进制文件。**objcopy** 工具提取原始二进制内容,并将其格式化为与 Verilog `$readmemh` 兼容的十六进制文件,其中每一行代表一个 32 位的内存字。 阶段| 命令| 输入| 输出| 关键标志 ---|---|---|---|--- 汇编| `riscv32-unknown-elf-as`| `.s`| `.o`| `-march=rv32i -mabi=ilp32` 链接| `riscv32-unknown-elf-ld`| `.o`| `.elf`| `-T linker.ld` 提取| `riscv32-unknown-elf-objcopy`| `.elf`| `.hex`| `-O verilog` `compile.sh` 脚本为 `asm/` 目录下的所有 `.s` 文件自动执行此流水线。`-march=rv32i` 标志将汇编器限制为仅使用基础整数 ISA——如果你不小心使用了 M 扩展中的指令(如 `MUL`),汇编器将在此阶段拒绝它。`-mabi=ilp32` 标志指定了 ABI 契约:32位整数、32位长整型、32位指针,确保一致的寄存器调用约定。 来源:[compile.sh](/programs/compile.sh#L1-L30), [linker.ld](/programs/linker.ld#L1-L8), [imem.v](/rtl/memory/imem.v#L8-L10) ## 循序渐进:编写、编译和运行测试 从空白文件到观察结果的完整工作流程遵循一个可预测的顺序。本节将介绍为 `SLT`(小于则置位)指令创建测试的过程——这是一项非平凡的 R 型操作,它同时测试了 ALU 的有符号比较逻辑和寄存器文件的写入路径。 否 是 否 是 Unsupported markdown: list Unsupported markdown: list 编译 成功? 检查汇编器错误 \- 仅限 RV32I? \- 寄存器名称有效? Unsupported markdown: list Unsupported markdown: list 输出中检测到 停机? 缺少 ecall 或 出现无限循环 Unsupported markdown: list Unsupported markdown: list **步骤 1 — 编写测试程序:** ASSEMBLY Copy code .section .text .globl _start _start: # 测试 SLT:有符号小于比较 li x1, -5 # 0xFFFFFFFB (负数) li x2, 3 # 正数 slt x3, x1, x2 # 预期 x3 = 1 (-5 < 3 有符号比较) # 测试 SLTU:无符号小于比较 sltu x4, x1, x2 # 预期 x4 = 0 (0xFFFFFFFB > 3 无符号比较) # 存储结果以供验证 lui x10, 0x10000 # x10 = 0x10000000 sw x3, 0(x10) # mem[0x10000000] = 1 sw x4, 4(x10) # mem[0x10000004] = 0 ecall **步骤 2 — 编译:** BASH Copy code cd programs ./compile.sh # 输出: "Compiling slt_test... Generated hex/slt_test.hex" **步骤 3 — 部署与仿真:** BASH Copy code cd ../sim cp ../programs/hex/slt_test.hex program.hex make simulate **步骤 4 — 验证结果:** BASH Copy code python3 ../tools/vcd_viewer.py riscv_core.vcd VCD 查看器输出显示了 PC 值和原始指令编码的按时间顺序的轨迹。要验证寄存器值,请使用波形查看器(如 <https://vc.drom.io> 上的在线工具)在每条 `SLT`/`SLTU` 指令执行后的周期检查 `uut.register_file.registers[3]` 和 `uut.register_file.registers[4]`。 来源:[compile.sh](/programs/compile.sh#L17-L27), [riscv_core_tb.v](/tb/riscv_core_tb.v#L22-L38), [vcd_viewer.py](/tools/vcd_viewer.py#L73-L132), [testing_guide.md](/docs/testing_guide.md#L76-L100) ## 按指令类别划分的测试模式 不同的指令类别需要不同的测试策略。“试一个值就继续”的朴素方法会遗漏边缘情况,而这恰恰是硬件 Bug 藏身之处。以下模式源自处理器的实际实现——每个表将测试场景映射到被测试的特定硬件路径。 ### R 型算术与逻辑指令 R 型指令使用两个寄存器操作数,并在 `funct3` \+ `funct7` 中编码操作。关键的测试向量针对 `ADD`/`SUB` 和 `SRL`/`SRA` 之间 `funct7[5]` 的消歧,这是 `funct7` 影响控制逻辑的唯一位置。 指令| 测试用例| 输入 A| 输入 B| 预期结果| 硬件路径 ---|---|---|---|---|--- `ADD`| 正向溢出| `0x7FFFFFFF`| `1`| `0x80000000`| ALU_ADD,无 funct7 `SUB`| 负数结果| `1`| `5`| `0xFFFFFFFC`| ALU_SUB,funct7[5]=1 `SLL`| 全位移位| `1`| `31`| `0x80000000`| ALU_SLL,shift = rs2[4:0] `SRL`| 逻辑右移| `0xFFFFFFFF`| `1`| `0x7FFFFFFF`| ALU_SRL,无符号扩展 `SRA`| 算术右移| `0x80000000`| `1`| `0xC0000000`| ALU_SRA,有符号扩展 `SLT`| 有符号比较| `-1`| `1`| `1`| ALU_SLT,$signed 比较 `SLTU`| 无符号比较| `-1`| `1`| `0`| ALU_SLTU,无符号比较 `SUB` 与 `ADD` 的消歧尤其微妙:对于 R 型指令,控制单元在 `funct3 == 3'b000` 内检查 `funct7[5]`。如果你只测试 `ADD`,你永远不会测试到选择 `ALU_SUB` 的 `funct7[5]` 路径。同样的逻辑也适用于 `funct3 == 3'b101` 下的 `SRL`/`SRA`。 ### I 型立即数操作 I 型指令嵌入一个 12 位的有符号立即数,立即数生成器会将其符号扩展为 32 位。符号扩展逻辑是 Bug 的主要来源——具体来说,是正立即数(第 11 位 = 0)和负立即数(第 11 位 = 1)之间的边界。 测试重点| 指令| 立即数| 验证的行为 ---|---|---|--- 零扩展边界| `ADDI x1, x0, 2047`| `0x7FF`| 最大正值:符号扩展为 `0x000007FF` 符号扩展| `ADDI x1, x0, -1`| `0xFFF`| 负数:符号扩展为 `0xFFFFFFFF` 移位量| `SLLI x1, x2, 5`| `0x005`| 仅 `imm[4:0]` 用于移位计数 算术移位| `SRAI x1, x2, 3`| `0x403`| `imm[11:5] = 0x20` 为 SRA 设置 funct7[5] 当编写 `ADDI x1, x0, -1` 时,汇编器将立即数编码为 `0xFFF`(-1 的 12 位二进制补码表示)。立即数生成器将其符号扩展为 `0xFFFFFFFF`。在每个 I 型测试中,务必至少使用一个负立即数来验证符号扩展行为。 ### 分支与跳转指令 分支指令测试分支单元的比较逻辑和 PC 加法器的目标计算。每个 `funct3` 变体测试不同的比较器,而 `branch_taken` 信号控制 PC 是跟随分支目标还是继续执行 PC+4。 指令| 比较类型| 有符号?| 关键测试:跳转| 关键测试:不跳转 ---|---|---|---|--- `BEQ`| 相等| —| `x1 == x2` → 跳转| `x1 != x2` → 继续执行 `BNE`| 不等| —| `x1 != x2` → 跳转| `x1 == x2` → 继续执行 `BLT`| 小于| 是| `-5 < 3` → 跳转| `3 < -5` → 继续执行 `BGE`| 大于等于| 是| `3 >= -5` → 跳转| `-5 >= 3` → 继续执行 `BLTU`| 无符号小于| 否| `1 < 0xFFFFFFFB` → 跳转| `0xFFFFFFFB < 1` → 继续执行 `BGEU`| 无符号大于等于| 否| `0xFFFFFFFB >= 1` → 跳转| `1 >= 0xFFFFFFFB` → 继续执行 `BLTU`/`BGEU` 与 `BLT`/`BGE` 的区别是最有启发性的测试用例:`-5`(编码为 `0xFFFFFFFB`)在有符号比较中 _小于_ `3`,但在无符号比较中 _大于_ `3`。如果测试只对正操作数使用 `BLT`,将永远无法捕获分支单元在应该执行有符号比较时却执行无符号比较的 Bug。 对于跳转指令,`JAL` 将 `PC + 4` 存入 `rd` 并跳转至 `PC + imm`,而 `JALR` 将 `PC + 4` 存入 `rd` 并跳转至 `(rs1 + imm) & ~1`。`PC + 4` 的写回由写回多路复用器中的 `jump` 信号控制,因此必须验证 `rd` 是否确实接收到了正确的返回地址。 ### 加载与存储操作 加载和存储指令测试数据存储器模块,该模块通过 `funct3` 支持五种寻址模式。字节级的内存组织和符号扩展行为是关键的验证目标。 数据存储器是一个由 `addr[11:0]` 索引的 4096 字节数组。存储操作按小端序写入 1、2 或 4 个字节。加载操作根据 `funct3` 通过符号扩展(`LB`,`LH`)或零扩展(`LBU`,`LHU`)重建 32 位值。一次彻底的加载/存储测试会写入一个已知模式,然后以每种访问宽度将其读回: ASSEMBLY Copy code .section .text .globl _start _start: # 设置:写入一个 32 位模式 lui x5, 0x10000 # 基地址 0x10000000 li x1, 0x12345678 sw x1, 0(x5) # 存储字 # 验证 LW lw x2, 0(x5) # x2 应为 0x12345678 # 验证 LB(偏移量 0 处的有符号字节 = 0x78) lb x3, 0(x5) # x3 = 0x00000078(正数,无符号扩展) # 验证 LB(偏移量 3 处的有符号字节 = 0x12) lb x4, 3(x5) # x4 = 0x00000012(正数,无符号扩展) # 验证 LBU(偏移量 0 处的无符号字节 = 0x78) lbu x6, 0(x5) # x6 = 0x00000078 # 使用负数字节测试符号扩展 li x1, 0x000000AB # 字节 0xAB 的第 7 位被置位 sb x1, 4(x5) # 在偏移量 4 处存储字节 lb x7, 4(x5) # x7 = 0xFFFFFFAB(符号扩展!) lbu x8, 4(x5) # x8 = 0x000000AB(零扩展) ecall 来源:[control.v](/rtl/core/control.v#L53-L81), [alu.v](/rtl/datapath/alu.v#L20-L34), [branch_unit.v](/rtl/datapath/branch_unit.v#L15-L25), [imm_gen.v](/rtl/datapath/imm_gen.v#L16-L42), [dmem.v](/rtl/memory/dmem.v#L24-L69), [riscv_core.v](/rtl/core/riscv_core.v#L122-L124) ## 分析测试结果 仿真完成后,你有两个互补的验证渠道:来自 `vcd_viewer.py` 的**文本执行轨迹** 和来自 VCD 查看器的**完整波形** 。它们各有用途。 Python VCD 查看器提取 `pc_out`、`instr` 和 `halt` 信号,以生成显示时间、PC、指令编码和停机状态的按时间顺序的轨迹。这是你的首轮验证——确认程序停机且 PC 进程与预期的控制流匹配。如果程序未能停机,轨迹会揭示 PC 在何处偏离预期。 对于寄存器和内存验证,你需要一个完整的波形查看器。需要检查的关键信号有: 信号路径| 用途 ---|--- `uut.pc`| 当前程序计数器 `uut.instr`| 当前指令字 `uut.register_file.registers[N]`| 寄存器 xN 的值 `uut.alu_result`| ALU 输出(写回前) `uut.mem_read_data`| 数据存储器读取结果 `uut.halt`| 停机标志 为了快速反汇编验证,可以在 ELF 文件上使用 `objdump`: BASH Copy code riscv32-unknown-elf-objdump -d programs/hex/mytest.elf 这会与你的汇编代码一起显示精确的机器码编码,允许你确认伪指令是否正确扩展,以及分支偏移量是否按预期计算。 来源:[vcd_viewer.py](/tools/vcd_viewer.py#L73-L132), [riscv_core_tb.v](/tb/riscv_core_tb.v#L41-L45), [testing_guide.md](/docs/testing_guide.md#L115-L129) ## 常见陷阱与故障排除 即使是有经验的 RISC-V 开发人员,在面向像 TinyRISCV 这样的极简处理器时也会遇到问题。下表列出了最常见的问题、其根本原因及诊断步骤。 症状| 可能原因| 诊断方法| 修复方案 ---|---|---|--- 程序从不停机| 缺少 `ecall` 或无限循环| 检查 VCD 轨迹中的 PC 模式| 在每个退出路径添加 `ecall` 汇编器错误:"illegal instruction"| 使用了 M 扩展或压缩指令| 检查 `-march=rv32i` 标志| 用软件例程替换 `MUL`/`DIV` 寄存器 x0 被修改| 写入 `x0`——硬件会静默忽略| 检查 objdump 中的 `rd=0`| 使用 `x1`–`x31` 作为目标 `LBU`/`LHU` 上符号扩展错误| 使用了 `LB`/`LH` 而不是无符号变体| 比较波形中的 `funct3`| 对无符号数据使用 `LBU`/`LHU` 分支在不该跳转时跳转| 有符号与无符号比较混淆| 用 `0xFFFFFFFF` 对比 `1` 测试| 对无符号比较使用 `BLTU`/`BGEU` `LI` 伪指令使用了意外的编码| 大立即数需要 `LUI`+`ADDI`| 检查 objdump 中的指令计数| 为清晰起见,使用显式的 `LUI`/`ADDI` 加载返回零| 数据内存基地址不正确| 验证地址在 `0x10000000` 范围内| 使用 `LUI x10, 0x10000` 作为数据基地址 仿真超时| 程序超过 1000 ns 没有 `ecall`| 检查测试平台超时值| 减少循环迭代或添加提前的 `ecall` 最常见的错误是忘记**`x0` 是硬连线到零的**。寄存器文件在 `read_addr` 为零时显式返回 `32'b0`,并在 `write_addr` 为零时静默丢弃写入。这意味着像 `ADD x0, x1, x2` 这样的指令会无错执行,但不会产生任何可观察的结果——ALU 计算了总和,但寄存器文件将其丢弃了。 来源:[regfile.v](/rtl/datapath/regfile.v#L21-L27), [control.v](/rtl/core/control.v#L128-L129), [riscv_core_tb.v](/tb/riscv_core_tb.v#L30-L31), [testing_guide.md](/docs/testing_guide.md#L133-L146) ## 构建全面的指令覆盖测试 单独的测试程序验证特定的指令,而**覆盖测试** 则验证所有 38 条 RV32I 指令是否能正确交互。factorial.s 程序演示了如何通过嵌套循环实现软件乘法——这种从原始指令构建更高级操作的相同模式正是覆盖测试的关键。 其策略是将测试构建为一系列独立的验证块,每个块测试一种指令类别,并将通过/失败指示器写入已知的数据内存地址。最后的总结遍会读回所有指示器: 块 1: R 型 ADD/SUB/AND/OR/XOR SLL/SRL/SRA/SLT/SLTU 块 2: I 型 ADDI/ANDI/ORI/XORI SLLI/SRLI/SRAI/SLTI/SLTIU 块 3: 加载/存储 LW/LH/LB/LHU/LBU SW/SH/SB 块 4: 分支 BEQ/BNE/BLT/BGE BLTU/BGEU 块 5: 跳转 JAL/JALR 块 6: 高位立即数 LUI/AUIPC 最后: 读取所有 结果地址 并 ecall 每个块将 `1`(通过)或 `0`(失败)写入连续的数据内存地址。所有块完成后,位于 `0x10000000`–`0x10000018` 的结果区域包含一个指令类别通过/失败状态的位域,你可以在波形查看器中检查它。 在构建覆盖测试时,请注意指令存储器大小所施加的 1024 条指令限制。对全部 38 条指令每条都有多个测试向量的完整覆盖测试很容易达到此限制。应优先考虑边界值测试而非穷举枚举,并使用参数化循环(如 `factorial.s` 中的乘法循环)来减少代码大小。 现有的测试程序为覆盖测试的构建提供了可重用的模式。`hello.s` 演示了基本的寄存器初始化和算术运算。`fibonacci.s` 提供了带有基于分支终止的循环模板。`factorial.s` 展示了如何实现嵌套计算循环。将这些模式——设置、循环、比较、存储、停机——结合起来,以系统地覆盖处理器支持的每一条指令。 来源:[hello.s](/programs/asm/hello.s#L1-L13), [fibonacci.s](/programs/asm/fibonacci.s#L1-L19), [factorial.s](/programs/asm/factorial.s#L1-L27), [control.v](/rtl/core/control.v#L16-L25), [imem.v](/rtl/memory/imem.v#L6-L7), [testing_guide.md](/docs/testing_guide.md#L193-L204) ## 下一步 掌握了编写、编译和验证汇编测试程序的能力后,你已经具备了执行任何 TinyRISCV 模块针对性验证的条件。自然的进展是将你的测试程序连接到仿真基础设施——[仿真与波形调试 ](/build-your-own-x-with-ai/TinyRISCV/18-simulation-and-waveform-debugging)涵盖了完整的波形分析工作流,而 [RV32I 指令参考 ](/build-your-own-x-with-ai/TinyRISCV/14-rv32i-instruction-reference)提供了构建精确测试向量所需的完整编码细节。为了更广泛地了解在测试程序执行期间处理器组件如何交互,请参阅[架构概述 ](/build-your-own-x-with-ai/TinyRISCV/3-architecture-overview)。 划线 写想法 提问
- 分享
为 TinyRISCV 编写汇编测试程序是验证处理器正确性的主要机制。与拥有丰富框架和断言的高级软件测试不同,测试裸机处理器要求你将 激励 和 预期结果 编码为原始机器指令,然后通过仿真波形观察寄存器和内存状态。本页面提供了一份系统的指南,用于编写有效的测试程序——从理解执行环境到构建全面的指令覆盖测试套件。
-
在Github README中添加Zread徽章添加徽章
来源
编写汇编测试程序
-
rtl
-
memory
- imem.v
- dmem.v
-
core
- riscv_core.v
- pc_register.v
- control.v
-
datapath
- alu.v
- branch_unit.v
- imm_gen.v
- regfile.v
-
-
programs
- linker.ld
-
asm
- hello.s
- fibonacci.s
- factorial.s
- compile.sh
-
tb
- riscv_core_tb.v
-
tools
- vcd_viewer.py
-
docs
-
testing_guide.md
仿真与波形调试
⌘K
-
-
- 分享
仿真是对 TinyRISCV 的主要验证机制——这是一个单周期核心,没有片上调试硬件,没有 JTAG 端口,也没有 printf。要判断处理器行为是否正确,必须通过观察 Verilog 仿真中的信号并检查生成的波形来获取所有线索。本页将介绍完整的仿真流程:从编译汇编程序、运行 Icarus Verilog,到使用 GTKWave 及其他替代查看器解读 VCD 输出,并提供一套系统的方法论,用于诊断最常见的 RTL 缺陷类别。
仿真工具链概述
TinyRISCV 依赖一套轻量级的开源仿真工具栈:Icarus Verilog 将 RTL 和测试平台编译为中间 VVP 格式,VVP 执行仿真并生成 VCD 波形转储文件,而 GTKWave (或替代查看器)则渲染该 VCD 文件以供交互式信号检查。整个流程由
sim/目录下的 Makefile 统筹,该文件提供了四个渐进式链接的目标:compile→simulate→wave。 riscv32-as ld + objcopy cp iverilog vvp gtkwave / viewer Assembly (.s) ELF (.o) Hex (.hex) program.hex VVP (.vvp) VCD (.vcd) Waveform 十六进制文件必须命名为program.hex并放置在sim/目录中,因为指令存储模块通过相对路径$readmemh("program.hex", memory)加载它——仿真的工作目录必须是sim/才能正确解析该路径。 来源: Makefile, imem.v测试平台:结构与 VCD 生成
tb/riscv_core_tb.v中的测试平台在设计上极其精简——它例化核心、驱动时钟和复位,并将所有信号转储到 VCD。它 不 执行自检断言;验证过程是可视化且手动的,因此理解其结构和输出对于有效调试至关重要。 时钟运行在 100 MHz(周期 = 10 ns,#5半周期翻转)。复位序列将rst_n拉低保持 20 ns(两个完整时钟周期),然后释放。仿真在复位后运行 1000 ns,随后检查halt信号——如果程序在该时间窗口内未停止,则报告超时。复位后的每个时钟上升沿,测试平台都会将当前的 PC 和指令打印到控制台,在 VCD 波形数据之外提供基于文本的执行轨迹。 信号| 方向| 位宽| 用途 —|—|—|—clk| input (reg)| 1| 100 MHz 时钟,10 ns 周期rst_n| input (reg)| 1| 低电平有效复位,拉低保持 2 个周期halt| output (wire)| 1| 当opcode == 7'b1110011(ECALL) 时为高电平pc_out| output (wire)| 32| 当前程序计数器,在顶层可见 测试平台使用了$dumpvars(0, riscv_core_tb)——深度参数0表示转储 所有 层级。这对于调试alu_result或reg_write等内部信号至关重要,但也会产生较大的 VCD 文件。对于长时间仿真,可考虑将深度更改为1,以仅捕获顶层端口。 来源: riscv_core_tb.v运行仿真
所有仿真命令均在
sim/目录下执行。Makefile 提供了四个目标,每个目标均建立在前一个目标之上: Make 目标| 依赖| 执行操作 —|—|—compile| 无| 将所有 RTL + 测试平台编译为riscv_core.vvpsimulate| compile| 运行 VVP,生成riscv_core.vcdwave| simulate| 使用预配置的wave.gtkw打开 GTKWaveclean| 无| 删除.vvp、.vcd及生成的十六进制产物 从汇编到波形的完整工作流如下: BASH Copy code cd programs && ./compile.sh && cd ..2. 将所需的十六进制文件拷贝至仿真目录
cp programs/hex/hello.hex sim/program.hex
3. 运行仿真(编译 + 执行)
cd sim && make simulate
4. 查看波形
make wave 此外,
run_sim.sh脚本封装了步骤 3——它只需调用vvp riscv_core.vvp并确认 VCD 文件已生成即可。view_wave.sh脚本则通过平台感知的 GTKWave 检测来处理步骤 4:它首先在 macOS 上搜索 Homebrew-cask 安装路径(/opt/homebrew/Caskroom/gtkwave),若未找到则回退至系统全局的gtkwave二进制文件。 如果你使用的是 Apple Silicon macOS,GTKWave 会在 Rosetta 下运行,并可能在字体渲染时崩溃。请使用python3 ../tools/vcd_viewer.py riscv_core.vcd获取基于文本的轨迹,或者将 VCD 文件拖入 vc.drom.io 进行基于浏览器的查看。 来源: Makefile, run_sim.sh, view_wave.sh理解波形:信号层级
VCD 文件捕获了设计层级中的每一个信号。GTKWave 保存文件
wave.gtkw为单周期 RISC-V 调试会话预选了最重要的信号。理解该层级结构是高效浏览波形的关键。 riscv_core_tb clk rst_n halt pc_out[31:0] riscv_core_tb.uut (riscv_core) instr[31:0] opcode[6:0] Control Signals Datapath Signals reg_write mem_read mem_write rs1_data[31:0] rs2_data[31:0] alu_result[31:0] write_back_data[31:0] pc_next[31:0]wave.gtkw中预配置的信号经过了刻意筛选,旨在完整呈现单条指令在一个时钟周期内的执行故事。在任意时钟沿从左到右读取,你可以得到:时钟/复位 → PC (当前处于哪条指令)→ 指令字 + 操作码 (指令类型是什么)→ reg_write (是否将写入寄存器)→ rs1_data / rs2_data (操作数是什么)→ alu_result (ALU 计算了什么)→ write_back_data (什么数据被写回)→ mem_read / mem_write (是否访问了内存)→ pc_next (执行流下一步去向何方)。 信号组| 信号| 揭示的信息 —|—|— 时钟|clk,rst_n| 时序参考;验证复位序列 取指|pc_out[31:0],instr[31:0],opcode[6:0]| 正在执行哪条指令及其类型 译码/控制|reg_write,mem_read,mem_write| 控制单元对该指令作出了何种决策 执行|rs1_data,rs2_data,alu_result| 操作数值与计算结果 写回|write_back_data| 实际写入寄存器堆的值 下一 PC|pc_next[31:0]| 是否发生分支/跳转或 PC+4 来源: wave.gtkw, riscv_core.v调试方法论:系统化阅读波形
当程序产生错误结果时,请抵制住随机扫描波形的诱惑。相反,应遵循与处理器自身执行流水线相映射的结构化分诊流程:取指 → 译码 → 执行 → 写回 。
步骤 1:验证复位序列
在检查任何指令之前,请确认
rst_n恰好在 20 ns 后变为高电平,并且 PC 从0x00000000开始。PC 寄存器在rst_n的下降沿复位为零 pc_register.v,因此如果复位后 PC 为垃圾值,则说明复位极性或时序有误。步骤 2:逐条指令追踪
对于复位后的每个时钟周期,请按顺序验证以下内容: 1. 取指 :当前
pc_out处的instr是否与预期的编码匹配?与objdump输出(riscv32-unknown-elf-objdump -d programs/hex/hello.elf)进行比对。如果指令字错误,则说明十六进制文件未正确加载或内存寻址有误——回想一下,imem按addr[11:2](字对齐)进行索引,因此字节地址需右移 2 位。 2. 译码 :opcode是否正确识别了指令类型?reg_write/mem_read/mem_write的组合是否与控制单元应为该操作码产生的信号一致?请参考 控制信号参考 获取预期映射。 3. 执行 :rs1_data和rs2_data是否为正确的寄存器值?alu_result是否为正确的计算结果?对于立即数指令,检查alu_operand_b是否等于符号扩展的立即数(你可能需要将imm信号添加到 GTKWave 视图中来进行此检查)。 4. 写回 :write_back_data是否是发送给寄存器堆的正确值?对于加载指令,该值应为mem_read_data(由mem_to_reg门控);对于跳转指令,该值应为pc + 4;对于其他指令,则应为alu_result。 5. 下一 PC :pc_next是否正确?对于顺序执行,应为pc + 4。对于发生的分支,应为pc + imm。对于 JALR,应为(rs1_data + imm) & ~1。步骤 3:定位错误阶段
一旦你发现第一个偏离预期行为的周期,请确定是 哪个阶段 产生了错误的值。错误几乎总是起源于某个模块,然后向前传播: 现象| 可能出错的模块| 检查内容 —|—|— 取指指令错误|
imem| 十六进制文件路径、地址对齐(addr[11:2]) 译码操作码错误|decoder| 位域提取(instr[6:0]) 控制信号错误|control| 操作码 → 信号映射、funct3/funct7逻辑 立即数值错误|imm_gen| 按操作码类型进行的符号扩展与位放置 ALU 结果错误|alu|alu_op选择、操作数路由(alu_src多路选择器) 分支决策错误|branch_unit| 比较逻辑、BEQ/BNE/BLT/BGE 的funct3下一 PC 错误|pc_adder|pc_src选择、branch_taken+jump逻辑 写回数据错误|riscv_core(多路选择器)|mem_to_reg和jump多路选择器逻辑 来源: riscv_core.v, control.v, pc_register.v自定义波形视图
wave.gtkw文件是一个纯文本的 GTKWave 配置文件,你可以直接编辑它以添加默认视图中未包含的信号。这在调试特定指令类型时尤为有用。向 wave.gtkw 添加信号
GTKWave 保存文件使用简单的格式。信号列在
@格式说明符之后。@28说明符表示二进制(单比特),而@22表示十六进制(多比特)。要添加信号,请插入一行包含其完整层级路径的文本: TEXT Copy code @22 riscv_core_tb.uut.imm[31:0] riscv_core_tb.uut.alu_operand_b[31:0] riscv_core_tb.uut.alu_zero riscv_core_tb.uut.branch_taken riscv_core_tb.uut.mem_read_data[31:0] riscv_core_tb.uut.funct3[2:0] riscv_core_tb.uut.funct7[6:0] riscv_core_tb.uut.rd[4:0] riscv_core_tb.uut.rs1[4:0] riscv_core_tb.uut.rs2[4:0]针对调试的特定信号集
不同的缺陷需要不同的信号可见性。以下是针对常见调试场景推荐的信号添加方案: 调试场景| 添加这些信号| 原因 —|—|— 立即数编码缺陷|
imm[31:0],alu_operand_b[31:0],opcode[6:0]| 验证按指令类型进行的符号扩展与位放置 分支/跳转缺陷|branch_taken,pc_src[1:0],imm[31:0],pc_next[31:0]| 追踪分支解析与下一 PC 选择 加载/存储缺陷|mem_read_data[31:0],funct3[2:0],alu_result[31:0]| 验证地址计算与内存数据路由 寄存器写入缺陷|rd[4:0],write_back_data[31:0],reg_write| 确认正确的寄存器被写入了正确的值 ALU 操作缺陷|alu_op[3:0],alu_operand_a,alu_operand_b,alu_result| 判断是否选择了错误的操作或操作数有误 来源: wave.gtkw替代波形查看器
虽然 GTKWave 是传统选择,但也存在几种替代方案——其中一些更适合特定的平台或工作流。 查看器| 安装方式| 优势| 局限性 —|—|—|— vcd_viewer.py| 内置 (
tools/vcd_viewer.py)| 基于文本,无需 GUI,显示带指令计数的执行轨迹| 无图形化波形,信号集仅限于pc_out/instr/haltvc.drom.io| 浏览器 (https://vc.drom.io)| 零安装,拖拽操作,交互式| 需要网络,信号搜索功能受限 Surfer|cargo install surfer| 原生 Rust 性能,现代 UI,可在 Apple Silicon 上运行| 需要 Rust 工具链,仍在完善中 GTKWave|brew install --cask gtkwave| 功能全面,.gtkw保存/恢复,信号分组| 由于 Rosetta + 字体渲染问题,在 Apple Silicon macOS 上会崩溃 内置的vcd_viewer.py对于快速验证特别有用:它解析 VCD 文件,提取 PC 和指令值,并打印显示时间、PC、指令和停止状态的表格化执行轨迹。它还会报告执行的总指令数,这是一个快速的健全性检查——如果你的斐波那契程序执行了 0 条指令,那么十六进制文件或复位序列肯定存在根本性的问题。 BASH Copy code快速基于文本的轨迹
cd sim python3 ../tools/vcd_viewer.py riscv_core.vcd 对于指令较多的程序(阶乘程序包含大量循环),文本轨迹可能会很长。使用停止检测来确认程序已终止,然后切换到图形化查看器以在特定时钟周期进行详细的信号检查。 来源: vcd_viewer.py, view_wave.sh
常见调试模式
在 TinyRISCV 的多次迭代开发中,某些缺陷模式反复出现。在波形中识别这些模式可以大幅加快诊断速度。
模式 1:程序永不停止
如果仿真触发超时(”Program did not halt within timeout”)且
halt信号从未变高,则 PC 很可能在指令间循环,且永远无法到达 ECALL。在波形中,观察pc_out是卡在单个值上(PC 寄存器未更新——检查是否因操作码误译码导致halt卡在高电平),还是在相同的地址范围内循环(汇编程序中的无限循环——检查分支偏移量和跳转目标)。模式 2:算术运算后寄存器值错误
如果 ADD 或 ADDI 产生错误结果,请按此顺序检查:(1)
rs1_data和rs2_data是否正确?如果不正确,则寄存器堆读取有误——检查译码器输出的rs1/rs2。(2)alu_operand_b是否正确?如果是立即数指令,alu_src必须为高电平,且该值应等于imm。(3)alu_op是否正确?对于 ADD,应为4'b0000;对于 SUB,应为4'b0001。模式 3:预期分支未发生
分支解析涉及三个模块:
branch_unit评估条件,control单元设置branch和pc_src,而pc_adder在 PC+4 和 PC+imm 之间进行选择。在波形中,验证branch_taken为高电平,pc_src == 2'b01(PC_BRANCH),且imm具有正确的分支偏移量。一个常见错误是funct3被误路由,导致分支单元评估了错误的比较(例如,将 BEQ 评估成了 BLT)。模式 4:加载返回错误数据
加载操作涉及的模块交互最多:ALU 计算地址(
alu_result),dmem读取数据,而mem_to_reg多路选择器将其路由至write_back_data。在波形中,检查:(1)alu_result是否为正确的内存地址,(2)mem_read是否为高电平,(3)funct3是否与加载宽度匹配(LB/LH/LW/LBU/LHU),以及 (4)write_back_data是否等于mem_read_data(而非alu_result)。如果加载的值看起来像是预期值的字节交换版本,则原因可能是dmem中的小端字节序——内存将字节单独存储在连续地址上。 来源: riscv_core.v, dmem.v, pc_adder.v, branch_unit.v控制台输出解读
测试平台产生的控制台输出可作为轻量级的执行轨迹。复位后的每个时钟上升沿,它都会打印: Copy code PC = 0x00000000, Instruction = 0x00500093 PC = 0x00000004, Instruction = 0x01400113 … Program halted at PC = 0x00000018 每一行均显示 PC 值和原始的 32 位指令字。将指令十六进制值与你的 objdump 反汇编结果进行交叉对照,以确认正在取指的指令是否正确。如果指令字与 objdump 在该地址显示的内容不匹配,则说明十六进制文件加载有误——请确保
program.hex是最新的且位于sim/目录中。 最后一行报告程序是否停止以及在哪个 PC 处停止。ecall指令映射到opcode == 7'b1110011,这会设置halt信号。停止 PC 将始终是 ECALL 指令本身的地址,而不是其后的指令,因为当halt为高电平时pc_register会冻结 PC。 来源: riscv_core_tb.v, riscv_core.v端到端调试演练
为了将所有内容串联起来,以下是调试产生错误结果程序的完整工作流: No Yes No Yes Yes No Yes No Run: make simulate Console: Did program halt? Check VCD: Is PC cycling or stuck? PC stuck → reset/halt issue PC cycling → infinite loop or branch bug Run: vcd_viewer.py Count instructions Instruction count matches expectation? Open waveform: Check PC sequence + branch_taken Branch taken incorrectly → branch_unit / pc_adder Branch not taken → branch_unit / control Open waveform: Find first wrong alu_result or write_back_data Wrong operands (rs1data/rs2_data)? Check register file writes from previous cycles Wrong alu_op selection? Check control unit opcode/funct3/funct7 → alu_op Check imm_gen / alu_operand_b mux 关键的洞察在于始终找到出错的第一个周期 。在单周期处理器中,错误只会向前传播而不会向后传播——一旦错误的值被写入寄存器堆,随后每条读取该寄存器的指令也将随之出错。通过找到 _第一个 偏差,你是在隔离根本原因,而不是在追逐下游的症状。 调试完成后,请使用
make clean清理生成的产物,然后再将更改提交至版本控制。clean 目标会删除sim/中的.vvp和.vcd文件,以及programs/hex/中的.o、.elf和.hex文件。 若要继续探索该设计,请参阅 顶层模块集成 以了解所有模块如何在riscv_core.v中连接,或参阅 验证与测试平台策略 以深入了解测试方法论。作为调试时的参考材料,控制信号参考 和 RV32I 指令参考 提供了预期的信号与编码表。 划线 写想法 提问
- 分享
仿真是对 TinyRISCV 的主要验证机制——这是一个单周期核心,没有片上调试硬件,没有 JTAG 端口,也没有 printf。要判断处理器行为是否正确,必须通过观察 Verilog 仿真中的信号并检查生成的波形来获取所有线索。本页将介绍完整的仿真流程:从编译汇编程序、运行 Icarus Verilog,到使用 GTKWave 及其他替代查看器解读 VCD 输出,并提供一套系统的方法论,用于诊断最常见的 RTL 缺陷类别。
-
在Github README中添加Zread徽章添加徽章
来源
仿真与波形调试
-
sim
- Makefile
- run_sim.sh
- view_wave.sh
- wave.gtkw
-
rtl
-
memory
- imem.v
- dmem.v
-
core
- riscv_core.v
- pc_register.v
- control.v
- pc_adder.v
-
datapath
- branch_unit.v
-
-
tb
- riscv_core_tb.v
-
tools
-
vcd_viewer.py
顶层模块集成
⌘K
-
-
- 分享
riscv_core模块是唯一的集成节点 ,所有九个子模块在此汇聚,构成一个连贯的单周期 RV32I 处理器。与通过中间包装器嵌套模块的多级层次结构设计不同,TinyRISCV 采用了扁平集成拓扑 ——每个子模块均在一个文件中直接实例化,所有模块间的连线均声明为局部线网,唯一的组合粘合逻辑也以内联形式存在。这种架构决策以结构深度换取了最大的可观测性 :每个跨越模块边界的信号在顶层均可见,使得处理器在仿真和波形调试期间的数据流完全透明。该模块仅暴露四个端口——clk、rst_n、halt和pc_out——在封装整个处理器状态的同时,提供了时钟驱动执行、复位控制以及程序终止检测所需的最小外部接口。 来源: riscv_core.v模块层次与实例化拓扑
该集成遵循严格的一级层次结构。
riscv_core模块从四个 RTL 目录——core/、datapath/、decoder/和memory/——实例化子模块,而不创建任何中间结构模块。下图展示了完整的实例化拓扑及模块间流动的信号类别: riscv_core (顶层集成) pc instr instr opcode, funct3, funct7 rs1, rs2 控制信号 控制信号 控制信号 pc_src, jump rs1data, rs2_data rs1_data, rs2_data rs1_data imm branch_taken alu_result mem_read_data alu_result write_back_data pc_next pc_register _rtl/core/ imem rtl/memory/ decoder rtl/decoder/ imm_gen rtl/datapath/ control rtl/core/ regfile rtl/datapath/ alu rtl/datapath/ dmem rtl/memory/ pc_adder rtl/core/ branch_unit rtl/datapath/ 内联 MUX 逻辑 虚线边框的“内联 MUX 逻辑”节点表示直接存在于riscv_core中而非任何子模块内的组合赋值。颜色编码区分了不同的功能组:蓝色 代表核心控制模块,橙色 代表存储子系统,紫色 代表译码阶段模块,绿色 代表数据通路组件。 实例名称| 模块| 源目录| 流水线角色 —|—|—|—pc_reg|pc_register|rtl/core/| IF — 保持当前 PCinstruction_memory|imem|rtl/memory/| IF — 指令取指dec|decoder|rtl/decoder/| ID — 字段提取imm_generator|imm_gen|rtl/datapath/| ID — 立即数生成ctrl|control|rtl/core/| ID — 控制信号分发register_file|regfile|rtl/datapath/| ID/EX — 寄存器读/写arithmetic_logic_unit|alu|rtl/datapath/| EX — 算术与逻辑运算branch_eval|branch_unit|rtl/datapath/| EX — 分支条件评估data_memory|dmem|rtl/memory/| MEM — 数据加载/存储pc_calculator|pc_adder|rtl/core/| EX/MEM — 下一 PC 计算riscv_core内部的命名约定采用了与模块名不同的描述性实例名 ——例如,使用arithmetic_logic_unit而非alu,branch_eval而非branch_unit,pc_calculator而非pc_adder。这种模式增强了波形层次化信号追踪时的可读性,因为实例名会成为所有内部信号的前缀(例如uut.arithmetic_logic_unit.result对比uut.alu.result)。 来源: riscv_core.v互连布线结构
顶层模块声明了 22 根内部线网 ,构成了连接所有子模块实例的完整信号结构。这些线网可分为五个功能组,每组代表单周期执行模型中的一个不同阶段:
线网类别细分
类别| 线网| 位宽| 流水线方向 —|—|—|— PC 总线|
pc,pc_next| 各 32 位| IF ↔ MEM (反馈环路) 指令与译码|instr,opcode,rd,rs1,rs2,funct3,funct7,imm| 32/7/5/5/5/3/7/32 位| IF → ID 寄存器数据|rs1_data,rs2_data| 各 32 位| ID → EX ALU 与分支|alu_result,alu_zero,branch_taken,alu_operand_a,alu_operand_b| 32/1/1/32/32 位| EX 存储与写回|mem_read_data,write_back_data| 各 32 位| MEM → WB 控制信号|reg_write,mem_read,mem_write,alu_src,mem_to_reg,branch,jump,alu_op,pc_src| 1/1/1/1/1/1/1/4/2 位| ID → 所有阶段 线网声明遵循数据流顺序 :代码自上而下的阅读顺序与 IF → ID → EX → MEM → WB 的流水线推进过程相匹配,使文件本身成为处理器时序执行流的空间表征。线网组之间没有交错——所有译码线网集中声明,所有控制信号集中声明,所有数据通路线网集中声明。 来源: riscv_core.v信号源-宿连接矩阵
下表将每根内部线网映射到其单一源模块和所有宿模块,揭示了决定关键路径关系的扇出拓扑 : 线网| 源模块| 宿模块 —|—|—
pc|pc_register|imem,pc_adder, 内联 (pc_out,pc_plus_4, AUIPC mux)pc_next|pc_adder|pc_registerinstr|imem|decoder,imm_genopcode|decoder|control,imm_gen, 内联 (halt, AUIPC mux)rd|decoder|regfilers1|decoder|regfilers2|decoder|regfilefunct3|decoder|control,branch_unit,dmemfunct7|decoder|controlimm|imm_gen| 内联 (ALU operand mux),pc_adderrs1_data|regfile|alu(经由 mux),branch_unit,pc_adderrs2_data|regfile|alu(经由 mux),branch_unit,dmemalu_result|alu|dmem, 内联 (write-back mux)branch_taken|branch_unit|pc_addermem_read_data|dmem| 内联 (write-back mux)write_back_data| 内联 MUX|regfilealu_op|control|alupc_src|control|pc_adder在仿真期间调试信号完整性问题时,请重点关注具有高扇出 的线网——opcode馈送给四个不同的消费者,而funct3馈送给三个。损坏的opcode值会同时级联影响control、imm_gen、halt 检测器以及 AUIPC 操作数 mux,从而在多个流水线阶段产生看似毫无关联的故障。 来源: riscv_core.v内联多路选择器逻辑
三个多路选择器并未作为子模块实现,而是作为
riscv_core内部的内联组合赋值 。这一设计选择反映了一种刻意权衡:这些多路选择器代表跨阶段的数据选择 ,不属于任何单一子模块的职责,将它们保留在顶层使得数据选择策略无需深入模块内部即可见。ALU 操作数 B 选择
VERILOG Copy code assign alu_operand_b = alu_src ? imm : rs2_data; 该 2:1 多路选择器在来自寄存器的操作数(
rs2_data)和立即数(imm)之间进行选择,作为 ALU 的第二个输入。由控制单元 生成的alu_src控制信号决定了选择结果:0 代表 R 型寄存器操作和分支比较,1 代表以立即数为操作数的 I 型、S 型、U 型和 J 型操作。 来源: riscv_core.vALU 操作数 A 选择(AUIPC 特殊路径)
VERILOG Copy code wire [31:0] alu_operand_a; assign alu_operand_a = (opcode == 7’b0010111) ? pc : rs1_data; 该多路选择器处理 AUIPC 异常 :虽然所有其他指令将
rs1_data馈送至 ALU 的第一个输入,但 AUIPC 需要当前pc作为pc + upper_imm的基地址。此处直接检查操作码7'b0010111,而非使用专用控制信号,这使得riscv_core中出现了唯一一处将opcode用作数据通路 mux 选择器的地方,而不是将其统一经由控制单元传递。这是一种有意的优化——增加单独的alu_src_a控制信号会增加控制单元的输出位宽,而这仅仅是为了服务一条指令。 AUIPC 的操作数 A mux 直接检查opcode,绕过了控制单元。如果你扩展的 ISA 中包含同样需要将pc作为 ALU 输入的指令(例如提议的PCADD自定义指令),你必须将此内联条件泛化为适当的控制信号,或者在此处添加额外的操作码检查——当前的模式在超出单一特殊情况后无法干净地扩展。 来源: riscv_core.v写回数据选择
VERILOG Copy code wire [31:0] pc_plus_4 = pc + 4; assign write_back_data = jump ? pc_plus_4 : (mem_to_reg ? mem_read_data : alu_result); 这是一个级联的 3:1 多路选择器 ,以嵌套三元表达式的形式实现。选择优先级为: 优先级| 条件| 选中值| 指令类型 —|—|—|— 1(最高)|
jump == 1|pc + 4| JAL, JALR 2|mem_to_reg == 1|mem_read_data| LB, LH, LW, LBU, LHU 3(默认)| 均不满足|alu_result| R 型, I 型 ALU, LUI, AUIPCpc_plus_4值作为单独的线网被预计算,且不与其他任何消费者共享——其存在的唯一目的就是用于跳转返回地址的写回。jump信号的优先级高于mem_to_reg,因为没有任何指令可以同时是跳转和内存加载(这在 RV32I 中属于互斥的操作码空间),因此尽管缺乏显式的互斥保护,该优先级顺序在架构上也是安全的。 来源: riscv_core.v停机检测
VERILOG Copy code assign halt = (opcode == 7’b1110011); assign pc_out = pc;
halt输出信号通过直接匹配 SYSTEM 操作码(7'b1110011)派生。这是一种 ECALL/EBREAK 检测 机制——当处理器遇到 SYSTEM 指令时,halt信号有效,导致 PC 寄存器 冻结,并由测试平台检测到程序终止。pc_out输出是内部pc线网的简单直通,暴露当前程序计数器以供外部观察,而未增加任何逻辑。 来源: riscv_core.v按指令类别的信号流
下图追踪了每种指令类别在顶层集成中的激活信号路径 ,展示了哪些线网承载有效数据,以及哪些模块参与了每种执行场景。为清晰起见,省略了未涉及的模块和非活动路径。 Jump (JAL, JALR) branch_taken pc_next pc_register imem decoder control regfile branch_unit pc_adder imm_gen 写回 MUX → pc+4 Load (LB, LH, LW 等) alu_src=1 alu_result mem_read_data pc_register imem decoder control regfile alu 操作数 B MUX → imm dmem 写回 MUX → mem_read_data R-type (ADD, SUB 等) alu_src=0 alu_result pc_register imem decoder control regfile alu 操作数 B MUX → rs2_data 写回 MUX → alu_result
各类别详细信号追踪
下表提供了每种指令类别的逐周期信号追踪,将每根顶层线网映射到其在执行期间的预期值。这可作为集成级验证清单 ——仿真期间的任何偏差均表明顶层存在连线或控制信号故障。 信号| R-type| I-type ALU| Load| Store| Branch| JAL| JALR| LUI| AUIPC —|—|—|—|—|—|—|—|—|—
opcode| 0110011| 0010011| 0000011| 0100011| 1100011| 1101111| 1100111| 0110111| 0010111alu_src| 0| 1| 1| 1| 0| X| 1| 1| 1alu_operand_a| rs1_data| rs1_data| rs1_data| rs1_data| rs1_data| rs1_data| rs1_data| rs1_data| pcalu_operand_b| rs2_data| imm| imm| imm| rs2_data| imm| imm| imm| immalu_op| 依 funct3/7 而定| 依 funct3 而定| ADD| ADD| 依 funct3 而定| ADD| ADD| ADD| ADDalu_result| 计算结果| 计算结果| 基址+偏移| 基址+偏移| 比较结果| pc+imm| rs1+imm| 0+imm| pc+immreg_write| 1| 1| 1| 0| 0| 1| 1| 1| 1mem_read| 0| 0| 1| 0| 0| 0| 0| 0| 0mem_write| 0| 0| 0| 1| 0| 0| 0| 0| 0mem_to_reg| 0| 0| 1| X| X| 0| 0| 0| 0branch| 0| 0| 0| 0| 1| 0| 0| 0| 0jump| 0| 0| 0| 0| 0| 1| 1| 0| 0pc_src| 00| 00| 00| 00| 01| 01| 10| 00| 00write_back_data| alu_result| alu_result| mem_data| —| —| pc+4| pc+4| alu_result| alu_resultbranch_taken| —| —| —| —| 评估结果| —| —| —| —pc_next| pc+4| pc+4| pc+4| pc+4| pc+imm/pc+4| pc+imm| (rs1+imm)&~1| pc+4| pc+4 AUIPC 列突出了其独特的alu_operand_a = pc路径,而 JALR 列则展示了其独特的pc_src = 10路径,该路径经由 PC 加法器 内部的(rs1_data + imm) & ~1进行路由。标记为“X”的项(无关项)表示其值不影响指令执行结果的信号——例如,当reg_write为 0 时,mem_to_reg的值是无关紧要的。 来源: riscv_core.v, control.v集成设计模式:带内联粘合逻辑的扁平布线
TinyRISCV 的顶层集成遵循带内联粘合逻辑的扁平布线 模式——所有子模块实例位于同一层次级别,顶层模块中唯一的组合逻辑由桥接跨模块数据通路的多路选择器和简单赋值组成。这种模式具有值得理解的特定架构影响:
模式特征
方面| 扁平布线模式| 替代方案:层次化包装器 —|—|— 层次深度| 1 级(所有模块直接位于顶层下)| 2 级以上(如 IF, ID, EX, MEM, WB 包装器) 信号可见性| 所有模块间线网在顶层可见| 线网隐藏在中间包装器内部 粘合逻辑位置| 顶层模块内联| 分布到包装器模块中 文件数量| 所有布线在 1 个文件中| 多个包装器文件,增加了文件数量 可扩展性| 随模块数量增加而下降| 随流水线阶段分组具有更好的扩展性 调试| 所有信号可从一个波形作用域追踪| 需要在层次化作用域之间导航
反馈环路架构
单周期设计创建了一个组合反馈环路 ,在集成层面理解这一点至关重要。在一个时钟周期内,信号从 PC 寄存器输出穿过整个数据通路,再回到 PC 寄存器输入: Copy code pc_register → imem → decoder → control → regfile → alu → dmem → 写回 mux → regfile ↑ │ └────────────────── pc_adder ← branch_unit ←────────────────────────────────────┘ 该环路由
pc_register的时钟边缘打破——寄存器在clk的上升沿捕获pc_next,新的pc值启动下一个周期的组合传播。从严格意义上讲,这里不存在组合环路,因为pc_register引入了时序边界。然而,从pc回到pc_next的组合路径 (经由imem → decoder → control → regfile → branch_unit → pc_adder)代表了整个处理器的关键时序路径 。这条链路上的总传播延迟决定了最大可达到的时钟频率。 来源: riscv_core.v, pc_register.v测试平台集成接口
riscv_core_tb.v 中的测试平台通过其四个暴露的端口与
riscv_core接口,将整个处理器视为具有最低可观测性的黑盒: VERILOG Copy code riscv_core uut ( .clk(clk), .rst_n(rst_n), .halt(halt), .pc_out(pc_out) ); 端口| 方向| 位宽| 用途 —|—|—|—clk| input| 1 位| 系统时钟(测试平台中为 100MHz,10ns 周期)rst_n| input| 1 位| 低电平有效异步复位halt| output| 1 位| 检测到 SYSTEM 操作码时有效pc_out| output| 32 位| 当前程序计数器值 测试平台通过 Verilog 的层次化引用机制访问内部状态——第 43 行 display 语句中的uut.instr深入riscv_core实例读取instr线网,而无需其作为输出端口。这是一种仅用于仿真的技术,利用了扁平集成模式的附带优势 :由于所有线网都声明在riscv_core的顶层,它们无需遍历深层嵌套即可通过层次化路径轻松访问。 测试平台的执行流程遵循一个简单的模式:复位 20ns(2 个时钟周期),释放复位,运行 1000ns,然后检查halt是否已有效。如果程序在超时窗口内未停机,测试平台将报告失败。有关详细的仿真过程和波形分析技术,请参阅仿真与波形调试 。 来源: riscv_core_tb.v, riscv_core_tb.v常见集成陷阱
在修改或扩展顶层集成时,一些布线模式是产生细微错误的常见根源: 陷阱| 症状| 根本原因 —|—|— 未连接的线网| 模块输出始终为
x(未定义)| 实例化中缺少端口连接 操作数总线交叉| ALU 对 R 型指令计算出错误结果|rs1_data/rs2_data线网交叉接反 写回值过时| 寄存器包含上一条指令的结果| 写回 MUX 选择信号对新指令类型不正确 PC 停滞在 0| 处理器永不推进|halt被错误有效,或pc_next未连接到pc_register内存数据损坏| 存储覆盖了错误的地址|alu_result未正确连接到dmem.addr分支永不执行| 所有分支均顺序执行|branch_taken线网未连接到pc_adder扁平布线模式减轻了“未连接的线网”陷阱,因为 Verilog 编译器会明确警告未连接的端口——并且在所有布线处于同一级别的情况下,没有中间包装器会掩盖此类警告。有关如何评估这些集成权衡的深入讨论,请参阅设计决策与权衡 。 来源: riscv_core.v导航
在了解了所有子模块如何在顶层连接在一起之后,下一步是理解这些集成选择背后的基本原理。设计决策与权衡 页面探讨了为何选择扁平布线模式而非层次化替代方案,内联 MUX 逻辑如何平衡可见性与可扩展性,以及单周期反馈环路施加了何种性能限制。有关集成的处理器如何作为整体进行验证的补充视角,请参阅验证与测试平台策略 。 划线 写想法 提问
- 分享
-
在Github README中添加Zread徽章添加徽章
来源
顶层模块集成
-
rtl/core
- riscv_core.v
- control.v
- pc_register.v
-
tb
-
riscv_core_tb.v
设计决策与权衡
⌘K
-
-
- 分享
每一款处理器的实现,都是一系列权衡决策的结晶——在何处投入复杂度,在何处接受局限性,以及如何使架构选择与项目的根本目标保持一致。TinyRISCV 以清晰笃定的方式做出了这些决策:教育透明性优于性能 ,结构简洁性优于功能完备性 ,单周期确定性优于频率优化 。本页将剖析每一项重大设计决策、当初备选的替代方案,以及选择当前路径背后的逻辑依据——旨在使你不仅理解该设计 做了什么 ,更懂得它 为何 这么做,以及若要向更偏向生产级的架构演进,需要付出哪些努力。
架构理念:单周期执行
TinyRISCV 中最举足轻重的决策当属其单周期执行模型 ——每一条指令,从简单的
ADD到加载-存储序列,都精确地在一个时钟周期内完成。这一选择决定了整个下游架构:组合逻辑关键路径、存储器接口设计、控制信号时序,以及流水线冒险逻辑的缺失。当halt信号无效时,处理器的pc_register会在每个上升沿捕获pc_next;由于pc_next是在同一周期内由当前状态组合计算得出的,因此每条指令都在一个节拍内,走完了从 PC 取指到写回的完整数据通路。 另一种替代方案——多周期或流水线设计——会将执行过程分解为多个阶段(IF、ID、EX、MEM、WB),并用中间流水线寄存器在各阶段间保存部分结果。虽然这能显著缩短关键路径并提升可达到的时钟频率,但它会引入一类在教学上具有遮蔽性的问题:需要前递逻辑的数据冒险、需要分支预测或延迟槽的控制冒险,以及需要资源仲裁的结构冒险。单周期模型彻底消除了这三类问题,使得时钟沿与已完成指令之间的关系变为双射且确定性的 。 其代价也十分高昂:关键路径作为一条单一的组合链路,横跨了整个数据通路。从架构中追踪最长路径,可以揭示出如下序列:PC → IMEM → 译码器 → 控制单元 → 寄存器堆读取 → ALU/分支 → DMEM → 写回多路选择器 → 寄存器堆写入输入 。对于加载指令,该链路在所有其他操作之上还包含了数据存储器的读取延迟。流水线设计会在每个阶段之间插入寄存器,将此链路切分为五个阶段,以流水线控制复杂度为代价,有望实现 3-5 倍的时钟频率提升。对于 TinyRISCV 的教育使命而言,这种权衡是毫不含糊的:学生可以在单个波形周期内端到端地追踪任何一条指令,而无需推演流水线暂存或时序交错。 来源: riscv_core.v, pc_register.v, architecture_zh.md存储架构:哈佛架构与定长数组
TinyRISCV 采用了哈佛架构 ,指令存储器和数据存储器物理分离,且均实现为 Verilog 寄存器数组。指令存储器是一个包含 1024 个 32 位字的数组(
reg [31:0] memory [0:1023]),提供 4KB 的只读指令存储空间,由addr[11:2]寻址——这是一个从字节地址派生出的字对齐索引。数据存储器是一个包含 4096 个 8 位字节的数组(reg [7:0] memory [0:4095]),同为 4KB,但以字节粒度组织,以支持子字(sub-word)的加载/存储操作。这种不对称性——按字索引的 IMEM 与按字节索引的 DMEM——是在实现简洁性与 ISA 兼容性之间做出的刻意权衡。 哈佛架构的选择消除了对统一存储器仲裁器的需求。在冯·诺依曼架构中,单一存储器端口必须在指令取指和数据访问之间进行时分复用;在单周期处理器中,这将需要双端口存储器或多周期的存储阶段。分离的存储器允许指令取指和数据访问同时进行——尽管在单周期模型中,这种并行性是隐式的,并未被显式利用,因为 IMEM 读取发生在周期早期,而 DMEM 读取发生在周期晚期。其核心优势在于结构简洁性 :无需仲裁逻辑,无需总线多路复用,无需存储阶段状态机。 每个存储体 4KB 的大小反映了一种务实的平衡。它大到足以容纳阶乘和斐波那契等非平凡的测试程序,并为基于栈的数据留有余地;又小到使仿真依然瞬时完成,且 FPGA 综合不会消耗过多的块 RAM。IMEM 的$readmemh初始化意味着程序在展开阶段加载,且在运行时永不修改——这一限制与教育用例相吻合,但排除了自修改代码或动态加载的可能。链接脚本通过将所有代码映射到起始地址0x00000000来强制执行此约束。 IMEM 使用addr[11:2]进行字索引(丢弃最低 2 位用于对齐),而 DMEM 使用addr[11:0]进行字节寻址。这意味着 IMEM 地址必须是 4 字节对齐的——未对齐的取指将读取错误的字,且不会产生任何错误指示。 来源: imem.v, dmem.v, linker.ld指令集覆盖范围:务实的 RV32I 子集
TinyRISCV 实现了 40 条标准 RV32I 指令中的 38 条 (加上作为停机机制的 ECALL),刻意省略了 FENCE、FENCE.I、EBREAK 以及所有 CSR 指令。这并非数据通路的技术局限,而是一个划定复杂度边界的决策 :被省略的指令服务于系统级功能——内存排序、调试断点和特权寄存器访问——这些在没有缓存层次结构、没有中断控制器、且没有特权模式强制执行的裸机教育型处理器中毫无意义。 下表映射了每个指令类别的设计决策: 类别| 指令| 数量| 设计依据 —|—|—|— R-type ALU| ADD, SUB, AND, OR, XOR, SLL, SRL, SRA, SLT, SLTU| 10| 核心计算;直接映射到 ALU I-type ALU| ADDI, ANDI, ORI, XORI, SLLI, SRLI, SRAI, SLTI, SLTIU| 9| 立即数变体;通过
alu_src多路选择器共享 ALU 加载| LW, LH, LB, LHU, LBU| 5| 完整子字支持;DMEM 中的funct3解复用 存储| SW, SH, SB| 3| 完整子字支持;字节级 DMEM 写入 分支| BEQ, BNE, BLT, BGE, BLTU, BGEU| 6| 专用分支单元;涵盖所有比较模式 跳转| JAL, JALR| 2|pc_src在 PC+imm 和 rs1+imm 间选择 上位立即数| LUI, AUIPC| 2|alu_src多路选择器将 ALU 加法器复用于 PC+imm 系统| ECALL| 1| 被改造为停机指令;操作码7'b1110011触发冻结 省略| FENCE, FENCE.I, EBREAK, CSR*| —| 需要缓存一致性、调试模块、特权模式 ECALL 指令体现了务实的功能复用 模式。控制单元并未实现带有陷阱向量和特权提升的陷阱处理机制,而是将 SYSTEM 操作码视为停机信号:当opcode == 7'b1110011时,halt线拉高,PC 寄存器冻结。这将一个复杂的架构特性(同步异常处理)转化为微不足道的组合逻辑检查,使程序能够干净地终止,而无需在内存中提供异常处理程序。 来源: control.v, control.v, riscv_core.v, README.mdALU 与操作数选择:基于多路选择器的操作数路由
ALU 设计采用了统一的 10 操作算术单元 ,配合基于多路选择器的操作数选择,以硬件冗余换取控制逻辑的简洁。该设计并未为 PC 相对地址计算、立即数加法和寄存器-寄存器操作分别维护独立的加法器,而是通过两个多路选择器选择适当的操作数,将所有计算路由至单一的 ALU。 ALU 操作数选择 opcode ≠ AUIPC opcode == AUIPC alu_src == 0 alu_src == 1 alu_operand_a rs1_data pc alu_operand_b rs2_data imm ALU 核心 (10 种操作) alu_result alu_zero 两个多路选择器中,
alu_operand_a更耐人寻味。对于除 AUIPC 之外的所有指令,operand_a = rs1_data。对于 AUIPC,operand_a = pc,使 ALU 能够无需专用 PC 加法器即可计算PC + upper_imm。这是通过操作数多路选择实现资源共享 的绝佳示例——用于计算ADD、ADDI及加载/存储地址的同一个 ALU 加法器,也同时处理了 AUIPC 操作。alu_operand_b多路选择器则更为常规:alu_src在rs2_data(用于 R-type)和imm(用于 I-type、加载、存储、LUI、AUIPC、JALR)之间进行选择。 LUI 指令揭示了该设计中一个巧妙的边缘情况。LUI 将上位立即数加载到rd中——概念上是一个零扩展并移位的操作。但在 TinyRISCV 的实现中,imm_gen为 LUI 生成{instr[31:12], 12'b0},控制单元设置alu_src = 1且alu_op = ALU_ADD。这意味着 LUI 通过 ALU 的加法路径作为0 + upper_imm执行。第一个操作数(rs1_data)实际上是 x[rs1] 所包含的任何内容 ,但由于 LUI 的指令格式将rs1置为00000(即 x0,硬连线至零),ALU 自然计算出0 + upper_imm = upper_imm。这是一种被用作设计简化的格式编码巧合 ——无需增加专用的“直通”ALU 操作,现有的 ADD 路径即可胜任。 ALU 输出的zero标志虽已生成,但从未被控制逻辑或分支单元消费。分支评估使用的是专用的branch_unit模块。zero标志作为一个遗留信号存在——对未来的扩展可能有用,但目前未连接至任何决策路径。 来源: riscv_core.v, alu.v, imm_gen.v, control.v分支单元:专用比较器 vs. ALU 复用
TinyRISCV 在专用的
branch_unit模块中实现分支条件评估,而非复用 ALU 基于减法的比较。这是一个重要的架构选择,因为许多单周期设计通过在 ALU 中执行operand_a - operand_b并检查结果的符号和零标志来评估分支——这种模式避免了复制比较器硬件。 选择专用方案基于三个原因。首先是语义清晰性 :分支单元的组合逻辑在 case 语句中将六种比较操作(BEQ, BNE, BLT, BGE, BLTU, BGEU)直接编码为独立的情况,使funct3与比较结果之间的关系一目了然。基于减法的方法则要求读者理解a - b == 0意味着a == b,或者a - b为负(在有符号解释下)意味着a < b——这增加了一层推理负担。其次是时序独立性 :分支单元与 ALU 并行操作,因此分支决断不会增加 ALU 的关键路径。在 ALU 结果馈入数据存储器的设计中,这种并行性意味着分支决断与数据通路计算同时进行。第三是有符号比较的正确性 :ALU 执行 32 位减法时没有单独的符号标志提取,而分支单元使用$signed()类型转换为 BLT 和 BGE 执行架构上正确的有符号比较。 其代价是硬件重复:分支单元实现了自身的等值与大小比较逻辑,这与 ALU 减法部分重叠。在 FPGA 或 ASIC 环境中,综合工具未必能优化掉这种冗余。但在教育语境下,将分支评估作为独立且可单独测试的模块所带来的益处,远超微小的面积开销。 来源: branch_unit.v, riscv_core.v写回路径:三路选择器设计
写回多路选择器实现了一个三路选择 ,决定将何值写回寄存器堆:ALU 结果、数据存储器读取数据,或
PC + 4(用于跳转并链接指令)。该设计将其编码为级联的条件表达式: Copy code write_back_data = jump ? pc_plus_4 : (mem_to_reg ? mem_read_data : alu_result) 这创建了一个优先级编码的多路选择器 ,而非平衡的三路选择器。jump信号拥有绝对优先权:当jump == 1时,写回值始终为PC + 4,无论mem_to_reg为何值。这在架构上是正确的,因为 JAL 和 JALR 永远不会同时执行内存读取和链接操作——ISA 语义保证了互斥性。然而,优先级编码引入了微妙的设计风险:如果控制信号缺陷导致jump和mem_to_reg同时有效,jump路径将静默覆盖,这可能会在调试时掩盖错误。 另一种设计方案是使用专用的 2 位写回源选择器(wb_src[1:0])并进行显式编码:00= ALU,01= Memory,10= PC+4,11= 保留。这将使所有路径在选择器中具有同等权重,并为验证提供显式的无效状态。当前的基于优先级的方法以牺牲验证鲁棒性为代价,换取了更简单的控制单元,且所需信号减少一个——jump信号身兼两职,既是 PC 源选择器,也是写回路径覆盖信号。pc_plus_4的值作为连续赋值计算(wire [31:0] pc_plus_4 = pc + 4),这意味着无论当前指令是否为跳转,它始终可用。这是推测计算 的又一实例:加法器始终处于活动状态,消耗功率并增加pc的组合扇出,但它通过免除使用jump信号门控pc_plus_4的需求,简化了写回多路选择器的控制。 来源: riscv_core.v, control.vPC 逻辑:集中式下一 PC 计算
pc_adder模块将由pc_src[1:0]信号控制的所有下一 PC 计算集中到单一的组合逻辑块中。此设计使 PC 流转具有局部可见性 :只需检查一个模块即可揭示所有可能的 PC 转换。这三种模式直接映射到架构需求:pc_src| 模式| 计算| 使用者 —|—|—|—2'b00| 顺序|PC + 4| R-type, I-type ALU, 加载, 存储, LUI, AUIPC2'b01| 分支/JAL| 若branch_taken || jump则PC + imm,否则PC + 4| 分支, JAL2'b10| JALR|(rs1 + imm) & ~1| JALR 分支/JAL 模式揭示了一个重要的设计细节。当pc_src == PC_BRANCH时,下一 PC 仅在branch_taken || jump为真时才为PC + imm;否则回落至PC + 4。这意味着分支未命中路径 依然流经PC_BRANCH情况,而非被重定向至PC_PLUS4情况。该逻辑正确运行是因为条件检查内嵌于 case 中,但这意味着PC_BRANCH情况处理了两种概念上不同的场景:命中分支和未命中分支。另一种设计方案会让控制单元为未命中分支设置pc_src = PC_PLUS4,但这将要求控制单元依赖于branch_taken——从而形成一条穿过分支单元的组合逻辑环路。当前设计通过将命中/未命中决策推迟至pc_adder本身,避免了该环路。 JALR 路径正确实现了最低有效位清零:(rs1_data + imm) & ~32'b1。这确保了目标地址始终为偶数对齐,符合 RISC-V 规范要求。表达式~32'b1生成32'hFFFFFFFE,将求和结果的第 0 位置零——单行代码即替代了本可能需要的独立对齐阶段。 来源: pc_adder.v, control.v, riscv_core.v寄存器堆:同步写入与硬连线 x0
寄存器堆实现了一个 32 项 × 32 位 的寄存器组,具备双异步读端口和单同步写端口。x0 寄存器并未实际存储——相反,两个读端口会检查地址
5'b0并组合地返回32'b0。这是处理硬连线零寄存器的标准 RISC-V 方案:寄存器并非存储零并阻止对地址 0 的写入,而是该索引处根本不存在寄存器,由读多路选择器提供常数。 写入逻辑包含一个保护条件write_addr != 5'b0,阻止对 x0 的任何写入。严格来说这显得冗余——无论存储了什么,组合读多路选择器从 x0 都会返回零——但它作为一项纵深防御 措施而存在。若无此保护,当错误控制信号导致write_addr == 0时触发reg_write,将静默写入registers[0],该值虽永远不会被读取,却会浪费功耗,并可能在调试检查寄存器数组时造成困扰。该保护使写入路径在架构上更为忠实:x0 不仅读取为零,且永远不会被写入。 异步读取设计(assign语句)意味着读取数据是组合可用的——它反映了寄存器数组的当前状态,无需等待时钟沿。这对于单周期模型至关重要:ALU 需要在寻址rs1_data和rs2_data的同一周期内获取它们。然而,这产生了一种写中读冒险 ,而单周期模型恰好从结构上避免了它。在单周期设计中,写入发生在时钟沿,而读取在同一周期内组合求值——但由于写入数据由当前周期组合逻辑的末尾决定,且直到下一时钟沿才被锁存,因此对正被写入的寄存器的读取将返回旧值 ,而非新计算的值。对于单周期模型而言,这是正确的,因为没有指令会读取由同一条指令写入的寄存器(写入针对rd,读取针对rs1/rs2,虽然编码中可能出现rd == rs1,但 ISA 语义规定读取看到的是写入前的值——这正是该实现所提供的)。在流水线扩展中,这将变为需要前递逻辑的数据冒险。 来源: regfile.v, riscv_core.v数据存储器:字节可寻址的小端存储
数据存储器的字节级组织是 TinyRISCV 中实现密集度最高的模块之一,其设计反映了一个刻意的选择:支持完整的 RV32I 加载/存储指令集 ,而非仅限于字访问。4096 字节的数组以及由
funct3解复用的读/写逻辑处理了 LB、LH、LW、LBU、LHU、SB、SH 和 SW——五种加载变体和三种存储变体——并在读取时对有符号形式应用符号扩展。 写入路径是时钟同步的:当mem_write有效时,存储在上升沿生效。字节、半字和字存储将写入数据分解为独立的字节通道,以小端序(最低有效字节位于最低地址)写入连续地址。读取路径是组合的:加载在同一周期内立即产生结果,并通过前置相应的常数位来执行符号或零扩展。这种不对称性——同步写入,异步读取——与单周期时序相吻合:ALU 组合计算地址,DMEM 组合读取,结果通过写回多路选择器流入寄存器堆的写入输入端,所有这些都在下一个时钟沿锁存之前完成。 完整子字支持的代价是数据存储器模块中显著的组合逻辑复杂性 。仅支持字的存储器设计会将 DMEM 简化为简单的reg [31:0] memory [0:1023]并采用字索引访问,在结构上与 IMEM 相同。支持字节和半字访问则需要funct3case 语句、字节级地址分解以及符号扩展逻辑——与仅支持字的设计相比,DMEM 的代码量大约增加了两倍。对于一个旨在运行真实程序(经常使用lb/sb进行字符串操作)的教育型处理器而言,这种复杂性是合理的。 来源: dmem.v控制单元:单片组合译码器
控制单元实现了一个单一的 always 块组合译码器 ,将
(opcode, funct3, funct7)元组直接映射到九个控制信号。这种单片方法——一个覆盖所有指令类型的大型 case 语句——以模块化为代价换取了全信号可见性 :每条指令的每一个控制信号的值,都可以通过阅读一块连续的代码来确定。 另一种方案是采用分布式控制设计,为每个信号或每个指令类配备独立的译码器。例如,reg_write可以由仅检查操作码的小模块生成,而alu_op可由检查funct3和funct7的独立模块生成。这种分布式方法将使单个信号的逻辑更容易独立验证,但更难从整体上进行推演——理解某条指令的完整控制信号集将需要交叉引用多个模块。单片设计为指令级推理 进行了优化,这恰恰是处理器设计者通常的思维方式:“JALR 指令对每个控制信号做了什么?” 一个值得注意的实现细节是,在 R-type 和 I-type 情况下,均使用funct7[5]检查来区分 ADD 与 SUB(以及 SRL 与 SRA)。RISC-V 规范将这一区别编码在指令的第 30 位(funct7[5]),控制单元直接检查该位,而非比较完整的funct7字段。这是一种最小译码 策略:仅检查影响控制决策的位,将比较宽度从 7 位减少至 1 位。其风险在于非标准的funct7编码(规范可能保留的部分)将被静默接受——但由于 TinyRISCV 未实现非法指令陷阱,这与整体设计理念中简洁性优于防御性验证的原则保持一致。 控制单元的默认情况将所有信号设置为其“安全”值:reg_write = 0,mem_write = 0,pc_src = PC_PLUS4。这意味着无法识别的操作码不会写入寄存器或存储器,只会简单地将 PC 推进 4——这是一种易于推理的静默失效 行为,但不提供任何诊断反馈。更具防御性的设计会断言一个错误信号,但这将要求测试平台或硬件监视器来观察它。 来源: control.v, control.v, control.v关键路径分析
理解关键路径对于评估单周期设计的性能上限以及规划未来的任何流水线化努力至关重要。TinyRISCV 中最长的组合路径遍历以下序列: PC 寄存器 (时序输出) 指令存储器 (异步读取) 译码器 (位提取) 控制单元 (case 译码) 寄存器堆 (异步读取) 立即数生成器 (符号扩展) ALU (计算) 数据存储器 (异步读取) 写回多路选择器 (三路选择) 寄存器堆 (写入输入) 对于加载指令 (最坏情况),关键路径为: 1. PC 输出 → IMEM 读取 (1024 项数组查找) 2. 指令 → 译码器 (组合位切片) 3. opcode → 控制单元 (case 语句求值) 4. rs1, rs2 → 寄存器堆读取 (32 项数组查找 × 2) 5. rs1_data + imm → ALU 加法 (32 位进位链) 6. alu_result → DMEM 读取 (4096 字节数组 + 符号扩展) 7. mem_read_data → 写回多路选择器 → 寄存器堆写入输入 两次存储器查找(IMEM 和 DMEM)以及 32 位 ALU 进位链是主要的耗时贡献者。在流水线重设计中,在 IMEM 读取之后(IF/ID 边界)和 ALU 结果之后(EX/MEM 边界)插入寄存器,会将关键路径大致缩减为以下三者中的最长者:IMEM 访问时间、寄存器堆 + ALU 时间,或 DMEM 访问时间——通常可实现 3-5 倍的可达到时钟频率提升。 分支决断路径 比加载路径短,因为它终止于
branch_unit输出,直接馈入pc_adder而不遍历 DMEM。这意味着分支指令不会造成最坏情况的关键路径,对它们进行流水线化带来的收益不如加载路径——这是单周期设计中为人熟知的非对称性。 来源: riscv_core.v, architecture_zh.md决策总结与演进路径
下表汇总了每一项重大设计决策、被否决的替代方案以及主要的权衡维度: 决策| 选择| 被否决的替代方案| 主要权衡 —|—|—|— 执行模型| 单周期| 多周期 / 流水线| 简洁性 vs. 频率 存储架构| 哈佛(独立 IMEM/DMEM)| 冯·诺依曼(统一)| 并行性 vs. 灵活性 ISA 覆盖范围| 38 条指令 + ECALL 停机| 完整 RV32I(47 条指令)| 完备性 vs. 控制复杂度 IMEM 组织| 按字索引,只读| 按字节寻址,可写| 简洁性 vs. 自修改代码 DMEM 组织| 按字节寻址,子字支持| 仅支持字| ISA 兼容性 vs. 实现成本 ALU 设计| 统一,基于多路选择器的操作数| 独立 PC 加法器 + 数据加法器| 资源共享 vs. 时序隔离 分支评估| 专用分支单元| ALU 减法 + 标志检查| 清晰性 vs. 面积 写回多路选择器| 优先级编码(jump > mem > ALU)| 平衡的 2 位选择器| 信号经济性 vs. 验证鲁棒性 PC 逻辑| 集中式 pc_adder 模块| 分布于数据通路各处| 局部性 vs. 模块化 寄存器 x0| 组合零 + 写入保护| 存储零并带写入保护| 优雅性 vs. 可调试性 控制单元| 单片组合逻辑| 分布式每信号译码器| 整体可读性 vs. 独立可验证性 非法指令| 静默 PC+4 推进| 陷阱 / 错误断言| 故障安全 vs. 故障诊断 停机机制| ECALL → 操作码匹配 → PC 冻结| 软件循环 / GPIO 信号| ISA 对齐 vs. 外部控制 对于考虑扩展 TinyRISCV 的开发者而言,最自然的演进路径是5 级流水线 (IF → ID → EX → MEM → WB),这需要:各阶段之间的流水线寄存器、用于数据依赖的冒险检测单元、用于旁路写回阶段的前递单元,以及 ID 阶段的分支决策(对命中分支施加 1 周期惩罚)。当前的模块化结构——具有控制、数据通路和存储模块的清晰分离——刻意组织成使这种过渡在结构上可行,尽管信号时序将需要大幅修订。例如,专用分支单元可以提前移入流水线而无需重新设计 ALU,且写回多路选择器的优先级编码需替换为平衡选择器,以妥善支持前递。 来源: architecture_zh.md, riscv_core.v, control.v
后续步骤
在剖析了每项重大设计选择背后的架构推理之后,自然的延续是理解这些决策在实践中如何得到验证。验证与测试平台策略 页面记录了单周期确定性模型如何简化测试,以及测试平台如何利用
halt信号提供干净的程序终止语义。若要更深入地理解任何特定模块的实现细节,可从控制单元 或 ALU 设计 开始,重温各独立模块页面。 划线 写想法 提问
- 分享
每一款处理器的实现,都是一系列权衡决策的结晶——在何处投入复杂度,在何处接受局限性,以及如何使架构选择与项目的根本目标保持一致。TinyRISCV 以清晰笃定的方式做出了这些决策:教育透明性优于性能 ,结构简洁性优于功能完备性 ,单周期确定性优于频率优化 。本页将剖析每一项重大设计决策、当初备选的替代方案,以及选择当前路径背后的逻辑依据——旨在使你不仅理解该设计 做了什么 ,更懂得它 为何 这么做,以及若要向更偏向生产级的架构演进,需要付出哪些努力。
-
在Github README中添加Zread徽章添加徽章
来源
设计决策与权衡
-
rtl
-
core
- riscv_core.v
- pc_register.v
- control.v
- pc_adder.v
-
memory
- imem.v
- dmem.v
-
datapath
- alu.v
- imm_gen.v
- branch_unit.v
- regfile.v
-
-
docs
- architecture_zh.md
-
programs
- linker.ld
-
README.md
验证与测试平台策略
⌘K -
- 分享
TinyRISCV 采用了程序驱动验证 的理念:它并非将设计拆分为独立的测试单元,而是将整个核心作为集成实体进行验证,具体方式是将编译后的 RISC-V 汇编程序加载到指令存储器中,在 RTL 仿真中执行它们,并观察处理器是否通过
ecall干净地停机。这种端到端的方法以牺牲细粒度的隔离为代价,换取了架构的真实性——每个测试都会同时运行完整的取指-译码-执行流水线、控制信号矩阵和存储子系统,这与真实软件在真实硅片上的运行方式如出一辙。测试台架构
唯一的测试台将
riscv_core实例化为待测单元 (UUT),仅暴露四个顶层端口:clk、rst_n、halt和pc_out。在内部,测试台执行三个截然不同的功能——时钟生成 、复位序列 以及带跟踪日志的停机检测 ——每个功能都实现为一个独立且并发运行的initial或always块。 Syntax error in textmermaid version 11.6.0 时钟生成器产生一个周期为 10ns 的信号(forever #5 clk = ~clk),产生 100 MHz 的有效频率。复位序列将rst_n保持低电平 20ns——恰好两个完整时钟周期——然后释放它,确保 PC 寄存器初始化为0x00000000,并且所有寄存器堆条目在第一次取指之前清零。停机检测器在复位释放后等待 1000ns(100 个时钟周期),然后检查halt输出:如果有效,则报告最终的 PC;否则,标记超时失败。 来源: riscv_core_tb.v, riscv_core.v停机机制与通过/失败语义
测试台的通过/失败标准是二元的,其根源在于
ecall指令(操作码7'b1110011)。当译码器产生此操作码时,顶层halt信号通过riscv_core中的assign halt = (opcode == 7'b1110011)组合生效。PC 寄存器通过冻结来响应halt——PC 寄存器 always 块中的else if (!halt)保护条件阻止了任何进一步的 PC 更新,从而有效地终止执行。 这种机制创建了一个关键的验证契约:每个测试程序都必须以ecall终止。如果没有它,处理器将在内存中紧随其后的任何指令(可能是零,译码为非法指令或空操作变体)中无限循环,并且测试台将在 1000ns 时报告超时。100 个时钟周期的超时窗口被刻意设置得很紧凑——它迫使测试保持简明,同时仍能容纳现有最长的测试程序(factorial.s,它执行嵌套乘法循环)。 停机条件| 测试台行为| 诊断输出 —|—|— 在 1000ns 内halt == 1|$display("Program halted at PC = 0x%h", pc_out)| 最终 PC 地址 在 1000ns 后halt == 0|$display("Program did not halt within timeout")| 超时警告 在 1000ns 前出现仿真错误| Icarus Verilog 运行时错误| 来自vvp的错误跟踪 1000ns 的超时是一个硬性约束,决定了测试程序的复杂度上限。如果你编写的测试需要超过约 95 条指令(计入 20ns 的复位阶段),请增加测试台中的#1000延迟,否则程序将错误地报告超时失败。 来源: riscv_core.v, pc_register.v, riscv_core_tb.v程序加载流水线
测试程序经过从汇编源码到仿真执行的四级流水线。链接脚本将所有代码放置在地址
0x00000000,编译链生成 Verilog 十六进制文件,imem在仿真初始化时通过$readmemh加载该文件。 Syntax error in textmermaid version 11.6.0compile.sh脚本为programs/asm/中的所有.s文件自动化了此流水线,将生成的.hex文件放入programs/hex/。关键的交接点是手动复制 步骤:仿真始终从program.hex(固定文件名)中读取,因此你必须在运行make simulate之前将所需的十六进制文件复制到sim/program.hex。这是一种刻意为之的权衡,即简洁性优先于自动化——没有将编译和仿真链接起来的 Makefile 目标。 阶段| 工具| 关键标志| 输出 —|—|—|— 汇编|riscv32-unknown-elf-as|-march=rv32i -mabi=ilp32|.o(ELF 目标文件) 链接|riscv32-unknown-elf-ld|-m elf32lriscv -T linker.ld|.elf(已链接的二进制文件) 十六进制转换|riscv32-unknown-elf-objcopy|-O verilog|.hex(Verilog 存储器初始化) 指令存储器是一个 1024 项 × 32 位的寄存器阵列,由addr[11:2]寻址——这是一个涵盖地址范围0x000–0xFFF(4 KB) 的字对齐索引。由objcopy生成的 Verilog 十六进制格式直接映射到此阵列,每行代表一个 32 位指令字。 来源: compile.sh, linker.ld, imem.v现有测试程序及其验证目标
代码库附带了三个汇编测试程序,每个程序针对不同的行为类别。了解每个程序测试了什么——以及它留下了什么未测试——对于评估验证完整性至关重要。 程序| 类别| 涵盖的指令| 预期行为 —|—|—|—
hello.s| 基本算术与高位立即数|li,add,addi,sub,lui,ecall| R 型和 I 型 ALU 操作,LUI 高位立即数加载fibonacci.s| 循环与条件分支|li,beq,add,mv,addi,j,ecall| 分支求值 (beq),向后跳转 (j=jal x0),循环迭代factorial.s| 嵌套循环与寄存器压力|li,beq,mv,add,addi,j,ecall| 嵌套循环控制,多寄存器数据流,计数器递减模式hello.s程序是最简单的:它加载两个立即数,将它们相加,加上立即数偏移量,相减,并加载高位立即数——然后停机。它验证了组合 ALU 路径 和 I 型/R 型译码 分支,但不执行存储器操作、分支和除最终ecall之外的跳转。fibonacci.s程序使用带有beq退出条件和j(jal x0, offset的伪指令)向后跳转的紧凑循环计算 10 次 Fibonacci 迭代。这测试了分支单元的 BEQ 求值 、PC 加法器的分支目标计算 (pc_src = PC_BRANCH)以及 branch_taken → pc_next 数据路径。它仍然完全避免了加载/存储操作。factorial.s程序使用嵌套循环结构实现 factorial(5) = 120:外层循环递减被乘数,而内层循环通过重复加法执行乘法。这是最密集的寄存器测试,同时使用寄存器x1–x4,它执行与fibonacci.s相同的分支/跳转路径,但嵌套更深,寄存器堆读/写冲突更频繁。 现有的三个测试程序均未涵盖加载/存储指令(lw,sw,lb,sb,lh,sh,lbu,lhu)、跳转并链接(带链接的jal,jalr)或比较操作(slt,slti,sltu,sltiu)。全面的验证策略必须用针对性的汇编测试来补充这些内容。 来源: hello.s, fibonacci.s, factorial.s信号可观测性与波形策略
测试台通过
$dumpvars(0, riscv_core_tb)将所有信号捕获到 VCD 文件中,该操作转储了整个仿真层次结构——DUT 中的每根连线和寄存器都是可观测的。wave.gtkw文件为 GTKWave 预配置了一组精选的信号子集,分为三个逻辑组: 控制平面信号 :clk、rst_n、halt——基本的测试台到 DUT 接口。这些信号在波形视图中排在最前面,因为它们建立了时间框架(时钟边沿、复位断言、停机检测)。 数据路径信号 :pc_out[31:0]、instr[31:0]、opcode[6:0]、rs1_data[31:0]、rs2_data[31:0]、alu_result[31:0]、write_back_data[31:0]——这些信号逐条指令地跟踪流水线中的数据流。同时包含instr(原始 32 位编码)和opcode(译码后的 7 位字段)允许同时验证取指正确性和译码准确性。 存储器接口信号 :reg_write、mem_read、mem_write、pc_next[31:0]——这些信号揭示了控制单元的决策和下一 PC 计算。pc_next信号尤其具有诊断价值:通过在时钟边沿锁存到 PC 寄存器之前将pc_next与期望值进行比较,任何意外的 PC 轨迹(例如,错误的分支目标,不正确的jalr返回地址)都能立即显现。 Python VCD 查看器(tools/vcd_viewer.py)提供了一种基于文本的替代方案,它从 VCD 文件中提取 PC、指令和停机信号,并生成表格化的执行跟踪。它对 PC 值进行去重(仅在pc更改时打印)并计算直到停机时执行的总指令数,这使其适用于无需启动 GUI 波形查看器的快速健全性检查。 来源: wave.gtkw, vcd_viewer.py, riscv_core_tb.v仿真基础设施
仿真流程由
sim/Makefile编排,它定义了构成线性流水线的四个目标: Syntax error in textmermaid version 11.6.0compile目标调用 Icarus Verilog (iverilog),其包含路径指向每个 RTL 子目录(core/、datapath/、memory/、decoder/),并将所有.v源文件和测试台编译为中间.vvp文件。simulate目标依赖于compile,并使用vvp执行.vvp文件,生成riscv_core.vcd。wave目标依赖于simulate并启动 GTKWave,具有针对 macOS Homebrew 安装与原生 Linux GTKWave 的平台特定检测。clean目标删除所有生成的产物——来自sim/的仿真文件(.vvp、.vcd)和来自programs/hex/的编译产物(.o、.elf、.hex)。这很重要,因为如果修改汇编源码后忘记重新编译,之前编译的十六进制文件可能会静默保留并被后续仿真加载。 Makefile 目标| 依赖项| 命令| 输出 —|—|—|—all/compile| RTL + 测试台源码|iverilog -o riscv_core.vvp ...|riscv_core.vvpsimulate|compile|vvp riscv_core.vvp|riscv_core.vcd+ 控制台跟踪wave|simulate|gtkwave riscv_core.vcd wave.gtkw| GTKWave GUIclean| 无|rm -f *.vvp *.vcd ...| 删除所有生成文件 来源: Makefile, view_wave.sh, run_sim.sh验证覆盖率分析
当前的测试台策略具有刻意的架构优势,但也存在明显的覆盖率缺口。以下分析将 RV32I 指令集与现有测试语料库进行映射,以揭示哪些已被验证,哪些仍未测试。 已验证的指令类别 (至少由一个现有测试程序涵盖): 类别| 指令| 测试程序| 验证的信号路径 —|—|—|— R 型 ALU|
ADD,SUB|hello.s|rs1_data→ ALU →write_back_data→ 寄存器堆 I 型 ALU|ADDI|hello.s,fibonacci.s,factorial.s|imm→ ALU 操作数 B 选择器 → ALU 高位立即数|LUI|hello.s|imm_genLUI 路径 → ALU (操作数 A = 0,操作数 B = imm) 分支 (相等)|BEQ|fibonacci.s,factorial.s| 分支单元 →branch_taken→pc_next选择 跳转 (非链接)|J(JAL x0)|fibonacci.s,factorial.s|jump信号 →pc_src = PC_BRANCH→pc_next = pc + imm系统|ECALL| 所有程序|opcode == 7'b1110011→halt→ PC 冻结 未验证的指令类别 (未被任何现有测试程序涵盖): 类别| 指令| 未测试的风险| 暴露的信号路径 —|—|—|— 加载|LB,LH,LW,LBU,LHU| 数据存储器读取路径,mem_to_reg选择器,dmem中基于funct3的符号扩展|mem_read→dmem→read_data→write_back_data存储|SB,SH,SW| 数据存储器写入路径,字节级寻址|mem_write→dmem写逻辑 → 按字节寻址的存储 R 型逻辑|AND,OR,XOR| ALU 操作 0010–0100|alu_op→ ALU case 语句 R 型移位|SLL,SRL,SRA| ALU 移位操作,funct7[5]消歧义|alu_op0101–0111 → ALU 移位逻辑 R 型比较|SLT,SLTU| 有符号/无符号比较|alu_op1000–1001 → ALU 比较 I 型逻辑/移位|ANDI,ORI,XORI,SLLI,SRLI,SRAI| 逻辑/移位的立即数变体|imm_genI 型路径 +alu_op选择 I 型比较|SLTI,SLTIU| 立即数比较|imm_genI 型路径 +alu_op1000–1001 分支 (不等)|BNE,BLT,BGE,BLTU,BGEU| BEQ 之外的分支单元条件| 分支单元funct3情况 001, 100–111 跳转 (链接)|JAL(带 rd≠x0),JALR| 返回地址存储,pc_src = PC_JALR,JALR 目标计算|jump=1+reg_write=1→write_back_data = pc+4→ 寄存器堆 AUIPC|AUIPC| PC 相对寻址,ALU 操作数 A 选择器|opcode == 7'b0010111→alu_operand_a = pc最重大的缺口是完全缺乏加载/存储测试 。数据存储器模块(dmem.v)包含设计中最复杂的行为逻辑——字节级寻址、基于funct3的符号扩展以及小端字节排序——然而当前的测试套件并未涵盖其中任何内容。 来源: control.v, dmem.v, branch_unit.v扩展测试台:战略建议
当前单一测试台、程序驱动的方法对于这种复杂度的设计在架构上是合理的,但可以通过三个正交轴进行加强:指令覆盖率 、自检断言 和自动化回归 。
通过寄存器观察实现自检
测试台目前缺乏自动化的值检查——它仅判断程序是否停机,而不判断是否产生了正确的结果。一种务实的增强方法是在停机检测后添加寄存器堆观察。由于测试台已经通过
uut具有对 DUT 的层次化访问权限,你可以直接探测寄存器值: VERILOG Copy code // After halt detection in riscv_core_tb.v if (halt) begin $display(“=== Register File at Halt ===”); for (i = 0; i < 32; i = i + 1) begin $display(“x%0d = 0x%h”, i, uut.register_file.registers[i]); end // Specific assertion example for hello.s: // x3 should contain x1(10) + x2(20) = 30 if (uut.register_file.registers[3] !== 32’d30) begin $display(“FAIL: x3 = 0x%h, expected 0x%h”, uut.register_file.registers[3], 32’d30); end end 这种方法需要针对每个测试程序修改测试台(因为期望的寄存器值不同),但它增加了自检 特性,将手动检查波形的工作流转变为自动化的通过/失败门控。面向覆盖率的汇编程序
为了填补上述指令覆盖率的缺口,应创建有针对性的汇编程序,系统地涵盖每个未测试的指令类别。按优先级排序,最需要添加的程序如下: 1. 加载/存储测试 ——涵盖
LW、SW、LB、SB、LH、SH、LBU、LHU,通过向数据存储器写入已知模式并读回,验证字节寻址和符号扩展。 2. 分支条件测试 ——涵盖所有六个分支条件(BEQ、BNE、BLT、BGE、BLTU、BGEU)的跳转和不跳转路径,验证分支单元的funct3分发。 3. JAL/JALR 测试 ——涵盖将pc+4存入目标寄存器然后通过JALR返回的链接跳转,验证当jump=1时write_back_data = pc_plus_4路径以及pc_src = PC_JALR的下一 PC 计算。 4. ALU 综合测试 ——使用已知操作数对涵盖所有 10 种 ALU 操作,验证 ALU always 块中的每个alu_op分支。 每个程序应以ecall结束,并设计为在 1000ns 超时窗口内完成。将已知值写入特定寄存器的程序能够启用上述自检增强功能。回归自动化
手动的
cp program.hex && make simulate工作流很脆弱——很容易忘记复制步骤或运行错误的十六进制文件。一个编译所有汇编程序、依次运行仿真并报告通过/失败的回归脚本,可以捕获由 RTL 更改引入的回归问题: BASH Copy code #!/bin/bash cd programs && ./compile.sh && cd ../sim for hex in ../programs/hex/*.hex; do cp “$hex” program.hex make simulate > /dev/null 2>&1 if grep -q “Program halted” <(vvp riscv_core.vvp 2>&1); then echo “PASS: $(basename $hex .hex)” else echo “FAIL: $(basename $hex .hex)” fi done 这将验证从临时手动过程转变为可重复的、可自动化的门控,可以集成到 CI 流水线中。 来源: riscv_core_tb.v, riscv_core.v, Makefile测试台局限性与设计理念
理解测试台为何如此构建——以及它体现了哪些刻意的权衡——对于任何扩展它的人来说都是必不可少的。当前的设计反映了三个明确的决策: 单级集成测试优先于单元测试。 没有 ALU、寄存器堆、分支单元或存储器模块的独立模块测试台。其理念是,TinyRISCV 的单周期、纯组合数据路径(除了边沿触发的 PC 寄存器和寄存器堆)使得单元级别的错误很容易通过指令跟踪在集成级别观察到。例如,计算错误的 ALU 结果会立即传播到寄存器堆,并在
$display跟踪中显示为错误值。这种权衡只有在错误表现为时序冒险或组合环路时才会失效——而在这个同步单周期设计中不存在这些情况。 基于十六进制文件的程序加载优先于过程式激励。 测试台不会通过 Verilog task 或 force 语句直接驱动指令存储器。相反,它依赖$readmemh加载预编译的十六进制文件。这意味着更改测试程序需要重新汇编和重新复制十六进制文件,但这同时也意味着测试激励与真实软件产生的激励完全相同 ——相同的工具链、相同的链接脚本、相同的二进制格式。这消除了一整类测试台与硅片之间的不匹配。 基于超时的停机检测优先于周期精确的完成。#1000延迟是一个粗略的超时,而不是精确的完成标记。测试台无法区分在第 95 个周期停机的程序和在第 5 个周期停机的程序——两者都简单地产生“Program halted”。对于指令数等于周期数的单周期处理器,这用于功能验证是可以接受的。然而,如果没有手动波形检查,它排除了性能验证(例如,确认每条指令都在恰好一个周期内完成)。 这些局限性并非疏忽——它们是有意识的选择,优先考虑简单性和快速迭代,而非穷举覆盖率。测试台旨在回答“处理器是否正确执行了程序?”这一问题,而不是“每个内部信号在每个可能的输入组合下是否正确转换?”后一个问题需要前述章节中描述的扩展。 来源: riscv_core_tb.v, imem.v, riscv_core.v下一步
要在实践中应用此处讨论的验证策略,请参阅编写汇编测试程序 以创建面向覆盖率的测试,以及仿真与波形调试 以导航 VCD 输出和诊断故障。要了解你的测试程序将要运行的控制信号,请查阅控制信号参考 和RV32I 指令参考 。 划线 写想法 提问
- 分享
TinyRISCV 采用了程序驱动验证 的理念:它并非将设计拆分为独立的测试单元,而是将整个核心作为集成实体进行验证,具体方式是将编译后的 RISC-V 汇编程序加载到指令存储器中,在 RTL 仿真中执行它们,并观察处理器是否通过
-
在Github README中添加Zread徽章添加徽章
来源
验证与测试平台策略
-
tb
- riscv_core_tb.v
-
rtl
-
core
- riscv_core.v
- pc_register.v
- control.v
-
memory
- imem.v
- dmem.v
-
datapath
- branch_unit.v
-
-
programs
- compile.sh
- linker.ld
-
asm
- hello.s
- fibonacci.s
- factorial.s
-
sim
- wave.gtkw
- Makefile
- view_wave.sh
- run_sim.sh
-
tools
- vcd_viewer.py
🖼️ Mermaid 图解
以下图表由 zread.ai 页面中的 Mermaid 源码预渲染生成,共 37 张。
ALU 设计 - 图 1
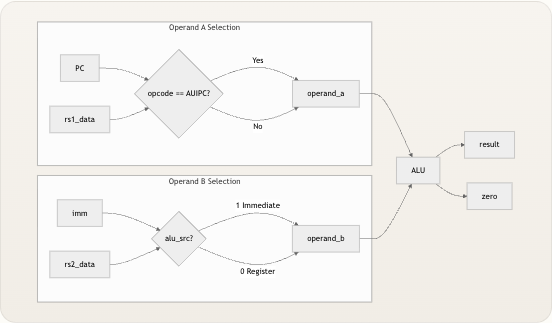
ALU 设计 - 图 2
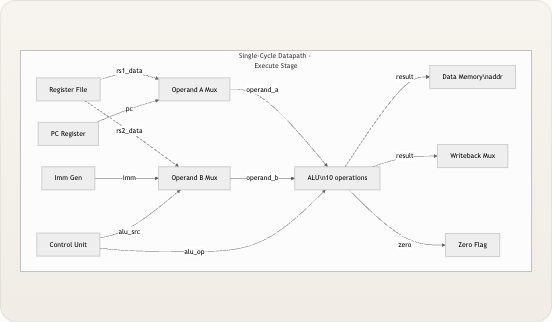
PC 加法器与下一 PC 选择 - 图 1
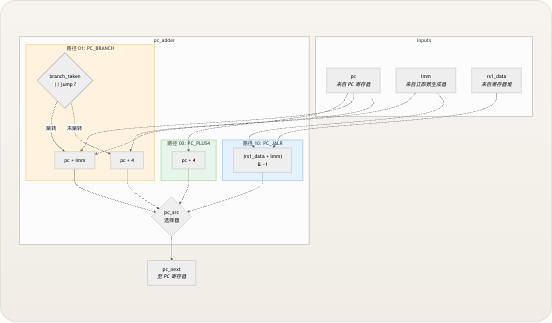
PC 加法器与下一 PC 选择 - 图 2
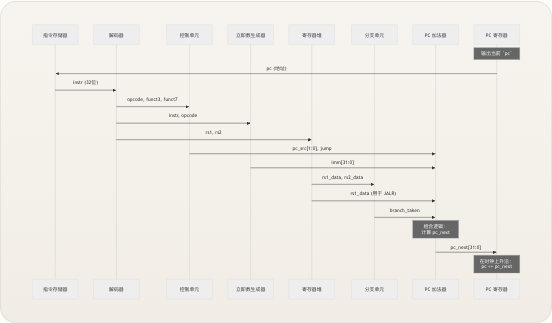
PC 寄存器 - 图 1
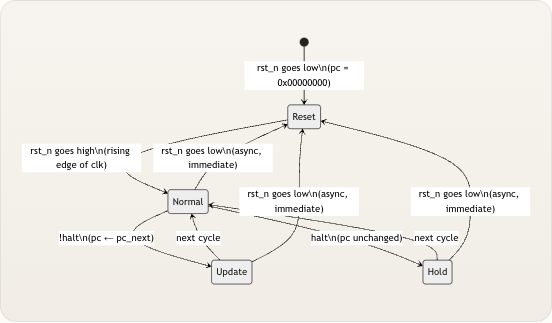
PC 寄存器 - 图 2
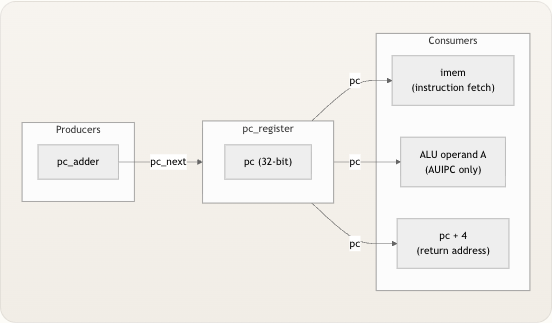
RV32I 指令参考 - 图 1
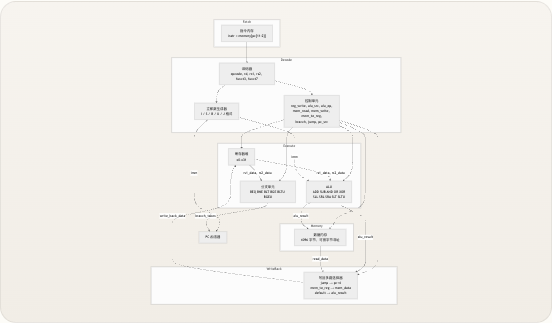
内存映射与地址布局 - 图 1
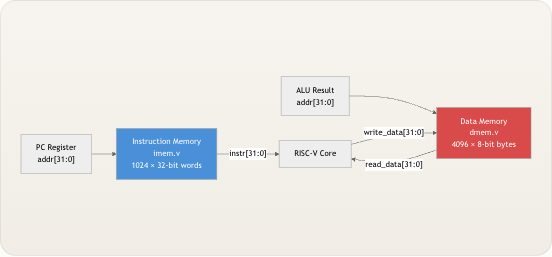
内存映射与地址布局 - 图 2
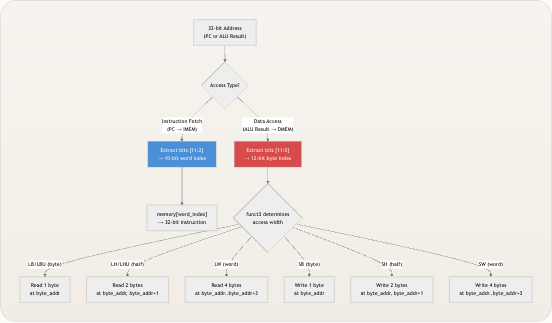
分支单元 - 图 1
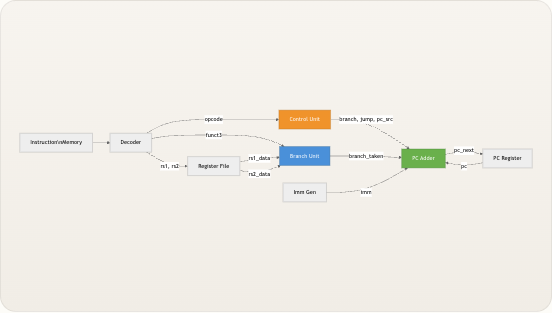
寄存器堆 - 图 1
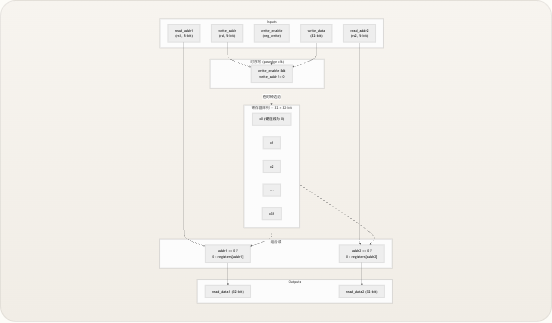
寄存器堆 - 图 2
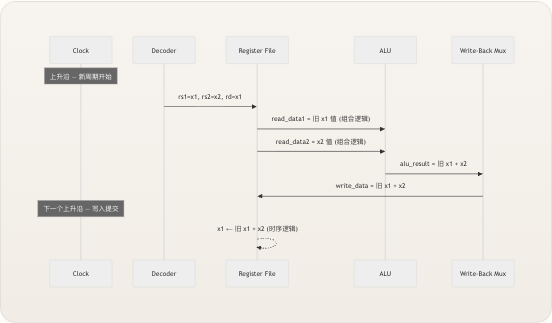
快速上手 - 图 1

指令存储器 - 图 1
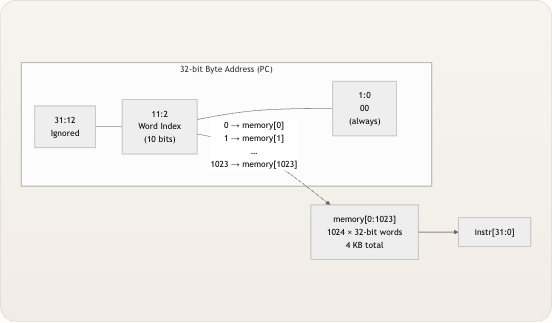
指令存储器 - 图 2
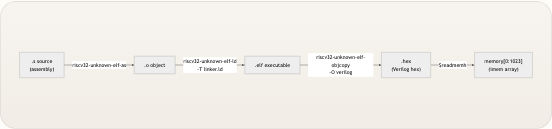
指令存储器 - 图 3
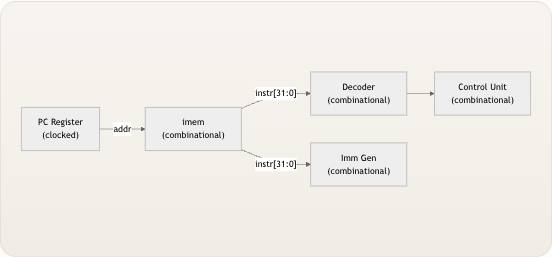
指令译码器 - 图 1
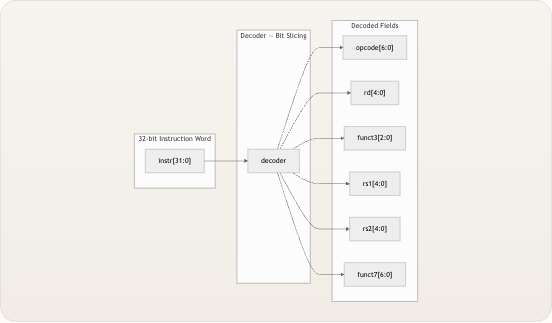
指令译码器 - 图 2
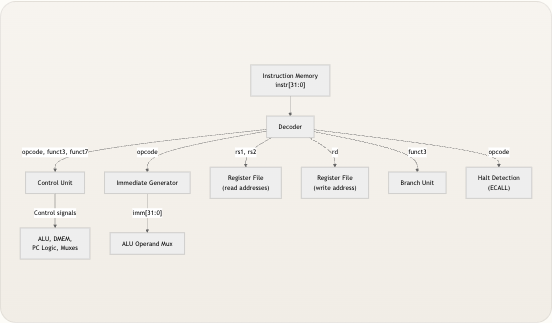
控制信号参考 - 图 1
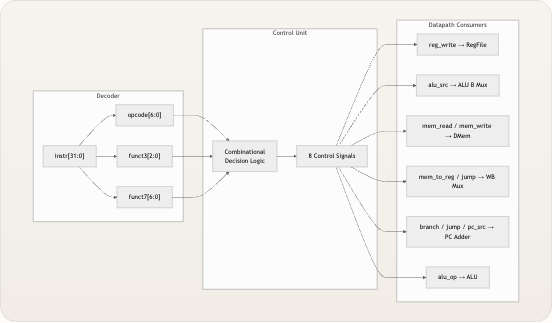
控制信号参考 - 图 2
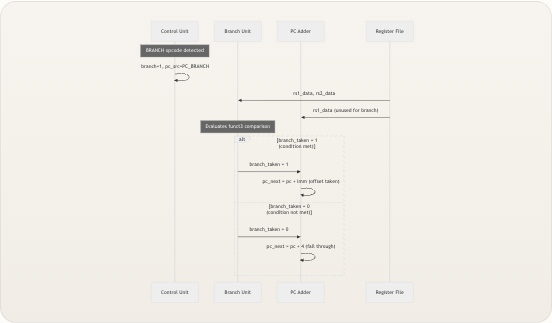
控制单元 - 图 1
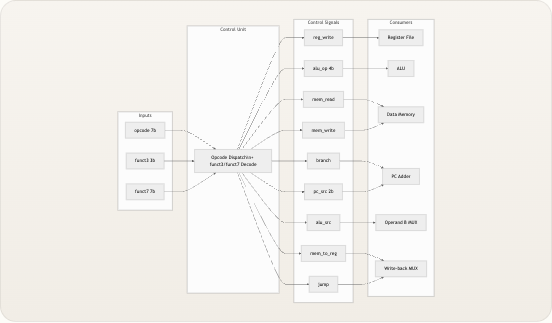
控制单元 - 图 2
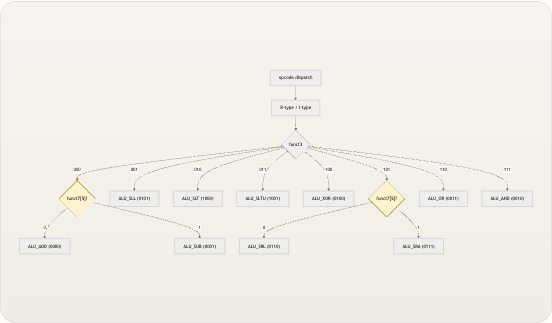
控制单元 - 图 3
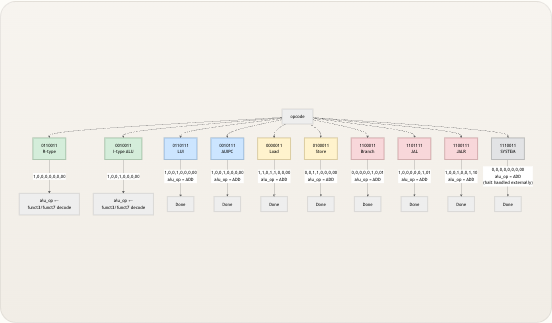
架构概览 - 图 1
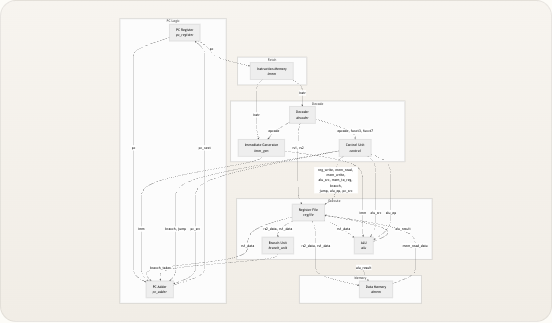
架构概览 - 图 2
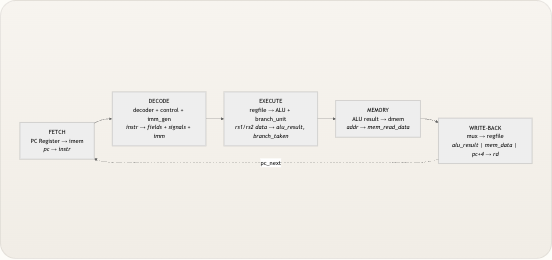
概述 - 图 1
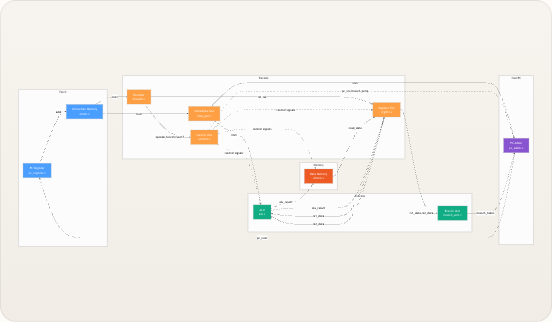
立即数生成器 - 图 1
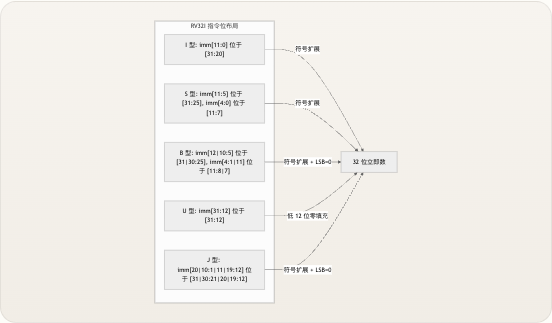
编写汇编测试程序 - 图 1
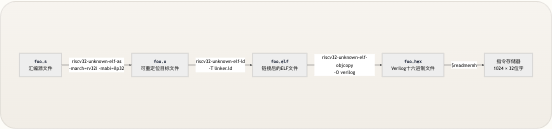
编写汇编测试程序 - 图 2
编写汇编测试程序 - 图 3

设计决策与权衡 - 图 1
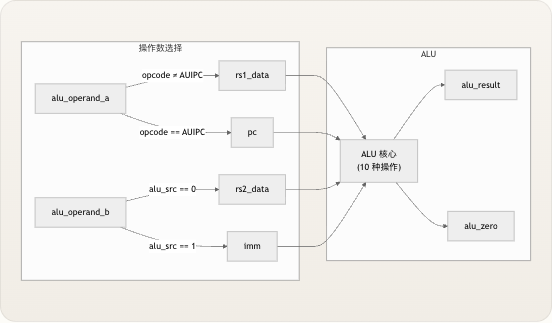
设计决策与权衡 - 图 2
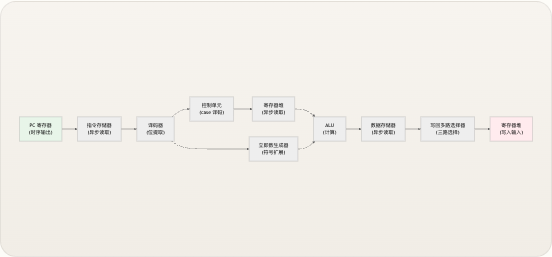
顶层模块集成 - 图 1
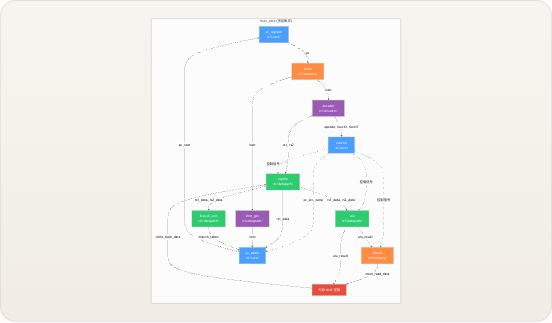
顶层模块集成 - 图 2
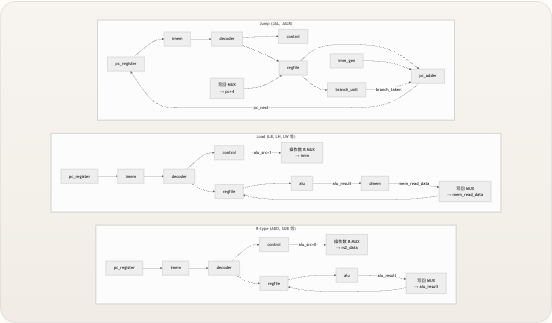
验证与测试平台策略 - 图 1
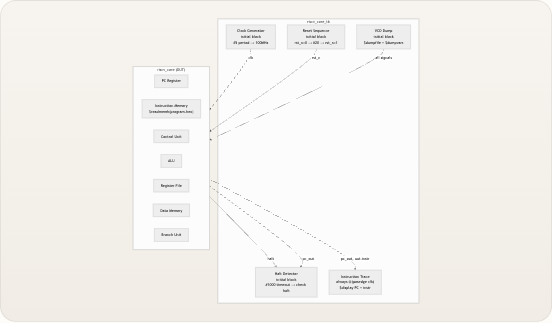
验证与测试平台策略 - 图 2
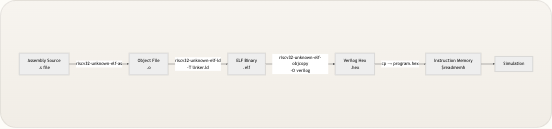
验证与测试平台策略 - 图 3